|
|
@@ -1,1485 +0,0 @@
|
|
|
-<?xml version="1.0"?>
|
|
|
-<!--
|
|
|
- Licensed to the Apache Software Foundation (ASF) under one or more
|
|
|
- contributor license agreements. See the NOTICE file distributed with
|
|
|
- this work for additional information regarding copyright ownership.
|
|
|
- The ASF licenses this file to You under the Apache License, Version 2.0
|
|
|
- (the "License"); you may not use this file except in compliance with
|
|
|
- the License. You may obtain a copy of the License at
|
|
|
-
|
|
|
- http://www.apache.org/licenses/LICENSE-2.0
|
|
|
-
|
|
|
- Unless required by applicable law or agreed to in writing, software
|
|
|
- distributed under the License is distributed on an "AS IS" BASIS,
|
|
|
- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
|
|
- See the License for the specific language governing permissions and
|
|
|
- limitations under the License.
|
|
|
--->
|
|
|
-
|
|
|
-<!DOCTYPE document PUBLIC "-//APACHE//DTD Documentation V2.0//EN" "http://forrest.apache.org/dtd/document-v20.dtd">
|
|
|
-
|
|
|
-<document>
|
|
|
-
|
|
|
- <header>
|
|
|
- <title>Cluster Setup</title>
|
|
|
- </header>
|
|
|
-
|
|
|
- <body>
|
|
|
-
|
|
|
- <section>
|
|
|
- <title>Purpose</title>
|
|
|
-
|
|
|
- <p>This document describes how to install, configure and manage non-trivial
|
|
|
- Hadoop clusters ranging from a few nodes to extremely large clusters with
|
|
|
- thousands of nodes.</p>
|
|
|
- <p>
|
|
|
- To play with Hadoop, you may first want to install Hadoop on a single machine (see <a href="single_node_setup.html"> Hadoop Quick Start</a>).
|
|
|
- </p>
|
|
|
- </section>
|
|
|
-
|
|
|
- <section>
|
|
|
- <title>Pre-requisites</title>
|
|
|
-
|
|
|
- <ol>
|
|
|
- <li>
|
|
|
- Make sure all <a href="single_node_setup.html#PreReqs">requisite</a> software
|
|
|
- is installed on all nodes in your cluster.
|
|
|
- </li>
|
|
|
- <li>
|
|
|
- <a href="single_node_setup.html#Download">Get</a> the Hadoop software.
|
|
|
- </li>
|
|
|
- </ol>
|
|
|
- </section>
|
|
|
-
|
|
|
- <section>
|
|
|
- <title>Installation</title>
|
|
|
-
|
|
|
- <p>Installing a Hadoop cluster typically involves unpacking the software
|
|
|
- on all the machines in the cluster.</p>
|
|
|
-
|
|
|
- <p>Typically one machine in the cluster is designated as the
|
|
|
- <code>NameNode</code> and another machine the as <code>JobTracker</code>,
|
|
|
- exclusively. These are the <em>masters</em>. The rest of the machines in
|
|
|
- the cluster act as both <code>DataNode</code> <em>and</em>
|
|
|
- <code>TaskTracker</code>. These are the <em>slaves</em>.</p>
|
|
|
-
|
|
|
- <p>The root of the distribution is referred to as
|
|
|
- <code>HADOOP_PREFIX</code>. All machines in the cluster usually have the same
|
|
|
- <code>HADOOP_PREFIX</code> path.</p>
|
|
|
- </section>
|
|
|
-
|
|
|
- <section>
|
|
|
- <title>Configuration</title>
|
|
|
-
|
|
|
- <p>The following sections describe how to configure a Hadoop cluster.</p>
|
|
|
-
|
|
|
- <section>
|
|
|
- <title>Configuration Files</title>
|
|
|
-
|
|
|
- <p>Hadoop configuration is driven by two types of important
|
|
|
- configuration files:</p>
|
|
|
- <ol>
|
|
|
- <li>
|
|
|
- Read-only default configuration -
|
|
|
- <a href="ext:core-default">src/core/core-default.xml</a>,
|
|
|
- <a href="ext:hdfs-default">src/hdfs/hdfs-default.xml</a>,
|
|
|
- <a href="ext:mapred-default">src/mapred/mapred-default.xml</a> and
|
|
|
- <a href="ext:mapred-queues">conf/mapred-queues.xml.template</a>.
|
|
|
- </li>
|
|
|
- <li>
|
|
|
- Site-specific configuration -
|
|
|
- <a href="#core-site.xml">conf/core-site.xml</a>,
|
|
|
- <a href="#hdfs-site.xml">conf/hdfs-site.xml</a>,
|
|
|
- <a href="#mapred-site.xml">conf/mapred-site.xml</a> and
|
|
|
- <a href="#mapred-queues.xml">conf/mapred-queues.xml</a>.
|
|
|
- </li>
|
|
|
- </ol>
|
|
|
-
|
|
|
- <p>To learn more about how the Hadoop framework is controlled by these
|
|
|
- configuration files, look
|
|
|
- <a href="ext:api/org/apache/hadoop/conf/configuration">here</a>.</p>
|
|
|
-
|
|
|
- <p>Additionally, you can control the Hadoop scripts found in the
|
|
|
- <code>bin/</code> directory of the distribution, by setting site-specific
|
|
|
- values via the <code>conf/hadoop-env.sh</code>.</p>
|
|
|
- </section>
|
|
|
-
|
|
|
- <section>
|
|
|
- <title>Site Configuration</title>
|
|
|
-
|
|
|
- <p>To configure the Hadoop cluster you will need to configure the
|
|
|
- <em>environment</em> in which the Hadoop daemons execute as well as
|
|
|
- the <em>configuration parameters</em> for the Hadoop daemons.</p>
|
|
|
-
|
|
|
- <p>The Hadoop daemons are <code>NameNode</code>/<code>DataNode</code>
|
|
|
- and <code>JobTracker</code>/<code>TaskTracker</code>.</p>
|
|
|
-
|
|
|
- <section>
|
|
|
- <title>Configuring the Environment of the Hadoop Daemons</title>
|
|
|
-
|
|
|
- <p>Administrators should use the <code>conf/hadoop-env.sh</code> script
|
|
|
- to do site-specific customization of the Hadoop daemons' process
|
|
|
- environment.</p>
|
|
|
-
|
|
|
- <p>At the very least you should specify the
|
|
|
- <code>JAVA_HOME</code> so that it is correctly defined on each
|
|
|
- remote node.</p>
|
|
|
-
|
|
|
- <p>Administrators can configure individual daemons using the
|
|
|
- configuration options <code>HADOOP_*_OPTS</code>. Various options
|
|
|
- available are shown below in the table. </p>
|
|
|
- <table>
|
|
|
- <tr><th>Daemon</th><th>Configure Options</th></tr>
|
|
|
- <tr><td>NameNode</td><td>HADOOP_NAMENODE_OPTS</td></tr>
|
|
|
- <tr><td>DataNode</td><td>HADOOP_DATANODE_OPTS</td></tr>
|
|
|
- <tr><td>SecondaryNamenode</td>
|
|
|
- <td>HADOOP_SECONDARYNAMENODE_OPTS</td></tr>
|
|
|
- </table>
|
|
|
-
|
|
|
- <p> For example, To configure Namenode to use parallelGC, the
|
|
|
- following statement should be added in <code>hadoop-env.sh</code> :
|
|
|
- <br/><code>
|
|
|
- export HADOOP_NAMENODE_OPTS="-XX:+UseParallelGC ${HADOOP_NAMENODE_OPTS}"
|
|
|
- </code><br/></p>
|
|
|
-
|
|
|
- <p>Other useful configuration parameters that you can customize
|
|
|
- include:</p>
|
|
|
- <ul>
|
|
|
- <li>
|
|
|
- <code>HADOOP_LOG_DIR</code> - The directory where the daemons'
|
|
|
- log files are stored. They are automatically created if they don't
|
|
|
- exist.
|
|
|
- </li>
|
|
|
- <li>
|
|
|
- <code>HADOOP_HEAPSIZE</code> - The maximum amount of heapsize
|
|
|
- to use, in MB e.g. <code>1000MB</code>. This is used to
|
|
|
- configure the heap size for the hadoop daemon. By default,
|
|
|
- the value is <code>1000MB</code>.
|
|
|
- </li>
|
|
|
- </ul>
|
|
|
- </section>
|
|
|
-
|
|
|
- <section>
|
|
|
- <title>Configuring the Hadoop Daemons</title>
|
|
|
-
|
|
|
- <p>This section deals with important parameters to be specified in the
|
|
|
- following:</p>
|
|
|
- <anchor id="core-site.xml"/><p><code>conf/core-site.xml</code>:</p>
|
|
|
-
|
|
|
- <table>
|
|
|
- <tr>
|
|
|
- <th>Parameter</th>
|
|
|
- <th>Value</th>
|
|
|
- <th>Notes</th>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>fs.defaultFS</td>
|
|
|
- <td>URI of <code>NameNode</code>.</td>
|
|
|
- <td><em>hdfs://hostname/</em></td>
|
|
|
- </tr>
|
|
|
- </table>
|
|
|
-
|
|
|
- <anchor id="hdfs-site.xml"/><p><code>conf/hdfs-site.xml</code>:</p>
|
|
|
-
|
|
|
- <table>
|
|
|
- <tr>
|
|
|
- <th>Parameter</th>
|
|
|
- <th>Value</th>
|
|
|
- <th>Notes</th>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>dfs.namenode.name.dir</td>
|
|
|
- <td>
|
|
|
- Path on the local filesystem where the <code>NameNode</code>
|
|
|
- stores the namespace and transactions logs persistently.</td>
|
|
|
- <td>
|
|
|
- If this is a comma-delimited list of directories then the name
|
|
|
- table is replicated in all of the directories, for redundancy.
|
|
|
- </td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>dfs.datanode.data.dir</td>
|
|
|
- <td>
|
|
|
- Comma separated list of paths on the local filesystem of a
|
|
|
- <code>DataNode</code> where it should store its blocks.
|
|
|
- </td>
|
|
|
- <td>
|
|
|
- If this is a comma-delimited list of directories, then data will
|
|
|
- be stored in all named directories, typically on different
|
|
|
- devices.
|
|
|
- </td>
|
|
|
- </tr>
|
|
|
- </table>
|
|
|
-
|
|
|
- <anchor id="mapred-site.xml"/><p><code>conf/mapred-site.xml</code>:</p>
|
|
|
-
|
|
|
- <table>
|
|
|
- <tr>
|
|
|
- <th>Parameter</th>
|
|
|
- <th>Value</th>
|
|
|
- <th>Notes</th>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>mapreduce.jobtracker.address</td>
|
|
|
- <td>Host or IP and port of <code>JobTracker</code>.</td>
|
|
|
- <td><em>host:port</em> pair.</td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>mapreduce.jobtracker.system.dir</td>
|
|
|
- <td>
|
|
|
- Path on the HDFS where where the Map/Reduce framework stores
|
|
|
- system files e.g. <code>/hadoop/mapred/system/</code>.
|
|
|
- </td>
|
|
|
- <td>
|
|
|
- This is in the default filesystem (HDFS) and must be accessible
|
|
|
- from both the server and client machines.
|
|
|
- </td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>mapreduce.cluster.local.dir</td>
|
|
|
- <td>
|
|
|
- Comma-separated list of paths on the local filesystem where
|
|
|
- temporary Map/Reduce data is written.
|
|
|
- </td>
|
|
|
- <td>Multiple paths help spread disk i/o.</td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>mapred.tasktracker.{map|reduce}.tasks.maximum</td>
|
|
|
- <td>
|
|
|
- The maximum number of Map/Reduce tasks, which are run
|
|
|
- simultaneously on a given <code>TaskTracker</code>, individually.
|
|
|
- </td>
|
|
|
- <td>
|
|
|
- Defaults to 2 (2 maps and 2 reduces), but vary it depending on
|
|
|
- your hardware.
|
|
|
- </td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>dfs.hosts/dfs.hosts.exclude</td>
|
|
|
- <td>List of permitted/excluded DataNodes.</td>
|
|
|
- <td>
|
|
|
- If necessary, use these files to control the list of allowable
|
|
|
- datanodes.
|
|
|
- </td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>mapreduce.jobtracker.hosts.filename/mapreduce.jobtracker.hosts.exclude.filename</td>
|
|
|
- <td>List of permitted/excluded TaskTrackers.</td>
|
|
|
- <td>
|
|
|
- If necessary, use these files to control the list of allowable
|
|
|
- TaskTrackers.
|
|
|
- </td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>mapreduce.cluster.acls.enabled</td>
|
|
|
- <td>Boolean, specifying whether checks for queue ACLs and job ACLs
|
|
|
- are to be done for authorizing users for doing queue operations and
|
|
|
- job operations.
|
|
|
- </td>
|
|
|
- <td>
|
|
|
- If <em>true</em>, queue ACLs are checked while submitting
|
|
|
- and administering jobs and job ACLs are checked for authorizing
|
|
|
- view and modification of jobs. Queue ACLs are specified using the
|
|
|
- configuration parameters of the form defined below under
|
|
|
- mapred-queues.xml. Job ACLs are described at
|
|
|
- mapred-tutorial in "Job Authorization" section.
|
|
|
- For enabling this flag(mapreduce.cluster.acls.enabled), this is to be
|
|
|
- set to true in mapred-site.xml on JobTracker node and on all
|
|
|
- TaskTracker nodes.
|
|
|
- </td>
|
|
|
- </tr>
|
|
|
-
|
|
|
- </table>
|
|
|
-
|
|
|
- <p>Typically all the above parameters are marked as
|
|
|
- <a href="ext:api/org/apache/hadoop/conf/configuration/final_parameters">
|
|
|
- final</a> to ensure that they cannot be overriden by user-applications.
|
|
|
- </p>
|
|
|
-
|
|
|
- <anchor id="mapred-queues.xml"/><p><code>conf/mapred-queues.xml
|
|
|
- </code>:</p>
|
|
|
- <p>This file is used to configure the queues in the Map/Reduce
|
|
|
- system. Queues are abstract entities in the JobTracker that can be
|
|
|
- used to manage collections of jobs. They provide a way for
|
|
|
- administrators to organize jobs in specific ways and to enforce
|
|
|
- certain policies on such collections, thus providing varying
|
|
|
- levels of administrative control and management functions on jobs.
|
|
|
- </p>
|
|
|
- <p>One can imagine the following sample scenarios:</p>
|
|
|
- <ul>
|
|
|
- <li> Jobs submitted by a particular group of users can all be
|
|
|
- submitted to one queue. </li>
|
|
|
- <li> Long running jobs in an organization can be submitted to a
|
|
|
- queue. </li>
|
|
|
- <li> Short running jobs can be submitted to a queue and the number
|
|
|
- of jobs that can run concurrently can be restricted. </li>
|
|
|
- </ul>
|
|
|
- <p>The usage of queues is closely tied to the scheduler configured
|
|
|
- at the JobTracker via <em>mapreduce.jobtracker.taskscheduler</em>.
|
|
|
- The degree of support of queues depends on the scheduler used. Some
|
|
|
- schedulers support a single queue, while others support more complex
|
|
|
- configurations. Schedulers also implement the policies that apply
|
|
|
- to jobs in a queue. Some schedulers, such as the Fairshare scheduler,
|
|
|
- implement their own mechanisms for collections of jobs and do not rely
|
|
|
- on queues provided by the framework. The administrators are
|
|
|
- encouraged to refer to the documentation of the scheduler they are
|
|
|
- interested in for determining the level of support for queues.</p>
|
|
|
- <p>The Map/Reduce framework supports some basic operations on queues
|
|
|
- such as job submission to a specific queue, access control for queues,
|
|
|
- queue states, viewing configured queues and their properties
|
|
|
- and refresh of queue properties. In order to fully implement some of
|
|
|
- these operations, the framework takes the help of the configured
|
|
|
- scheduler.</p>
|
|
|
- <p>The following types of queue configurations are possible:</p>
|
|
|
- <ul>
|
|
|
- <li> Single queue: The default configuration in Map/Reduce comprises
|
|
|
- of a single queue, as supported by the default scheduler. All jobs
|
|
|
- are submitted to this default queue which maintains jobs in a priority
|
|
|
- based FIFO order.</li>
|
|
|
- <li> Multiple single level queues: Multiple queues are defined, and
|
|
|
- jobs can be submitted to any of these queues. Different policies
|
|
|
- can be applied to these queues by schedulers that support this
|
|
|
- configuration to provide a better level of support. For example,
|
|
|
- the <a href="ext:capacity-scheduler">capacity scheduler</a>
|
|
|
- provides ways of configuring different
|
|
|
- capacity and fairness guarantees on these queues.</li>
|
|
|
- <li> Hierarchical queues: Hierarchical queues are a configuration in
|
|
|
- which queues can contain other queues within them recursively. The
|
|
|
- queues that contain other queues are referred to as
|
|
|
- container queues. Queues that do not contain other queues are
|
|
|
- referred as leaf or job queues. Jobs can only be submitted to leaf
|
|
|
- queues. Hierarchical queues can potentially offer a higher level
|
|
|
- of control to administrators, as schedulers can now build a
|
|
|
- hierarchy of policies where policies applicable to a container
|
|
|
- queue can provide context for policies applicable to queues it
|
|
|
- contains. It also opens up possibilities for delegating queue
|
|
|
- administration where administration of queues in a container queue
|
|
|
- can be turned over to a different set of administrators, within
|
|
|
- the context provided by the container queue. For example, the
|
|
|
- <a href="ext:capacity-scheduler">capacity scheduler</a>
|
|
|
- uses hierarchical queues to partition capacity of a cluster
|
|
|
- among container queues, and allowing queues they contain to divide
|
|
|
- that capacity in more ways.</li>
|
|
|
- </ul>
|
|
|
-
|
|
|
- <p>Most of the configuration of the queues can be refreshed/reloaded
|
|
|
- without restarting the Map/Reduce sub-system by editing this
|
|
|
- configuration file as described in the section on
|
|
|
- <a href="commands_manual.html#RefreshQueues">reloading queue
|
|
|
- configuration</a>.
|
|
|
- Not all configuration properties can be reloaded of course,
|
|
|
- as will description of each property below explain.</p>
|
|
|
-
|
|
|
- <p>The format of conf/mapred-queues.xml is different from the other
|
|
|
- configuration files, supporting nested configuration
|
|
|
- elements to support hierarchical queues. The format is as follows:
|
|
|
- </p>
|
|
|
-
|
|
|
- <source>
|
|
|
- <queues>
|
|
|
- <queue>
|
|
|
- <name>$queue-name</name>
|
|
|
- <state>$state</state>
|
|
|
- <queue>
|
|
|
- <name>$child-queue1</name>
|
|
|
- <properties>
|
|
|
- <property key="$key" value="$value"/>
|
|
|
- ...
|
|
|
- </properties>
|
|
|
- <queue>
|
|
|
- <name>$grand-child-queue1</name>
|
|
|
- ...
|
|
|
- </queue>
|
|
|
- </queue>
|
|
|
- <queue>
|
|
|
- <name>$child-queue2</name>
|
|
|
- ...
|
|
|
- </queue>
|
|
|
- ...
|
|
|
- ...
|
|
|
- ...
|
|
|
- <queue>
|
|
|
- <name>$leaf-queue</name>
|
|
|
- <acl-submit-job>$acls</acl-submit-job>
|
|
|
- <acl-administer-jobs>$acls</acl-administer-jobs>
|
|
|
- <properties>
|
|
|
- <property key="$key" value="$value"/>
|
|
|
- ...
|
|
|
- </properties>
|
|
|
- </queue>
|
|
|
- </queue>
|
|
|
- </queues>
|
|
|
- </source>
|
|
|
- <table>
|
|
|
- <tr>
|
|
|
- <th>Tag/Attribute</th>
|
|
|
- <th>Value</th>
|
|
|
- <th>
|
|
|
- <a href="commands_manual.html#RefreshQueues">Refresh-able?</a>
|
|
|
- </th>
|
|
|
- <th>Notes</th>
|
|
|
- </tr>
|
|
|
-
|
|
|
- <tr>
|
|
|
- <td><anchor id="queues_tag"/>queues</td>
|
|
|
- <td>Root element of the configuration file.</td>
|
|
|
- <td>Not-applicable</td>
|
|
|
- <td>All the queues are nested inside this root element of the
|
|
|
- file. There can be only one root queues element in the file.</td>
|
|
|
- </tr>
|
|
|
-
|
|
|
- <tr>
|
|
|
- <td>aclsEnabled</td>
|
|
|
- <td>Boolean attribute to the
|
|
|
- <a href="#queues_tag"><em><queues></em></a> tag
|
|
|
- specifying whether ACLs are supported for controlling job
|
|
|
- submission and administration for <em>all</em> the queues
|
|
|
- configured.
|
|
|
- </td>
|
|
|
- <td>Yes</td>
|
|
|
- <td>If <em>false</em>, ACLs are ignored for <em>all</em> the
|
|
|
- configured queues. <br/><br/>
|
|
|
- If <em>true</em>, the user and group details of the user
|
|
|
- are checked against the configured ACLs of the corresponding
|
|
|
- job-queue while submitting and administering jobs. ACLs can be
|
|
|
- specified for each queue using the queue-specific tags
|
|
|
- "acl-$acl_name", defined below. ACLs are checked only against
|
|
|
- the job-queues, i.e. the leaf-level queues; ACLs configured
|
|
|
- for the rest of the queues in the hierarchy are ignored.
|
|
|
- </td>
|
|
|
- </tr>
|
|
|
-
|
|
|
- <tr>
|
|
|
- <td><anchor id="queue_tag"/>queue</td>
|
|
|
- <td>A child element of the
|
|
|
- <a href="#queues_tag"><em><queues></em></a> tag or another
|
|
|
- <a href="#queue_tag"><em><queue></em></a>. Denotes a queue
|
|
|
- in the system.
|
|
|
- </td>
|
|
|
- <td>Not applicable</td>
|
|
|
- <td>Queues can be hierarchical and so this element can contain
|
|
|
- children of this same type.</td>
|
|
|
- </tr>
|
|
|
-
|
|
|
- <tr>
|
|
|
- <td>name</td>
|
|
|
- <td>Child element of a
|
|
|
- <a href="#queue_tag"><em><queue></em></a> specifying the
|
|
|
- name of the queue.</td>
|
|
|
- <td>No</td>
|
|
|
- <td>Name of the queue cannot contain the character <em>":"</em>
|
|
|
- which is reserved as the queue-name delimiter when addressing a
|
|
|
- queue in a hierarchy.</td>
|
|
|
- </tr>
|
|
|
-
|
|
|
- <tr>
|
|
|
- <td>state</td>
|
|
|
- <td>Child element of a
|
|
|
- <a href="#queue_tag"><em><queue></em></a> specifying the
|
|
|
- state of the queue.
|
|
|
- </td>
|
|
|
- <td>Yes</td>
|
|
|
- <td>Each queue has a corresponding state. A queue in
|
|
|
- <em>'running'</em> state can accept new jobs, while a queue in
|
|
|
- <em>'stopped'</em> state will stop accepting any new jobs. State
|
|
|
- is defined and respected by the framework only for the
|
|
|
- leaf-level queues and is ignored for all other queues.
|
|
|
- <br/><br/>
|
|
|
- The state of the queue can be viewed from the command line using
|
|
|
- <code>'bin/mapred queue'</code> command and also on the the Web
|
|
|
- UI.<br/><br/>
|
|
|
- Administrators can stop and start queues at runtime using the
|
|
|
- feature of <a href="commands_manual.html#RefreshQueues">reloading
|
|
|
- queue configuration</a>. If a queue is stopped at runtime, it
|
|
|
- will complete all the existing running jobs and will stop
|
|
|
- accepting any new jobs.
|
|
|
- </td>
|
|
|
- </tr>
|
|
|
-
|
|
|
- <tr>
|
|
|
- <td>acl-submit-job</td>
|
|
|
- <td>Child element of a
|
|
|
- <a href="#queue_tag"><em><queue></em></a> specifying the
|
|
|
- list of users and groups that can submit jobs to the specified
|
|
|
- queue.</td>
|
|
|
- <td>Yes</td>
|
|
|
- <td>
|
|
|
- Applicable only to leaf-queues.<br/><br/>
|
|
|
- The list of users and groups are both comma separated
|
|
|
- list of names. The two lists are separated by a blank.
|
|
|
- Example: <em>user1,user2 group1,group2</em>.
|
|
|
- If you wish to define only a list of groups, provide
|
|
|
- a blank at the beginning of the value.
|
|
|
- <br/><br/>
|
|
|
- </td>
|
|
|
- </tr>
|
|
|
-
|
|
|
- <tr>
|
|
|
- <td>acl-administer-jobs</td>
|
|
|
- <td>Child element of a
|
|
|
- <a href="#queue_tag"><em><queue></em></a> specifying the
|
|
|
- list of users and groups that can view job details, change the
|
|
|
- priority of a job or kill a job that has been submitted to the
|
|
|
- specified queue.
|
|
|
- </td>
|
|
|
- <td>Yes</td>
|
|
|
- <td>
|
|
|
- Applicable only to leaf-queues.<br/><br/>
|
|
|
- The list of users and groups are both comma separated
|
|
|
- list of names. The two lists are separated by a blank.
|
|
|
- Example: <em>user1,user2 group1,group2</em>.
|
|
|
- If you wish to define only a list of groups, provide
|
|
|
- a blank at the beginning of the value. Note that the
|
|
|
- owner of a job can always change the priority or kill
|
|
|
- his/her own job, irrespective of the ACLs.
|
|
|
- </td>
|
|
|
- </tr>
|
|
|
-
|
|
|
- <tr>
|
|
|
- <td><anchor id="properties_tag"/>properties</td>
|
|
|
- <td>Child element of a
|
|
|
- <a href="#queue_tag"><em><queue></em></a> specifying the
|
|
|
- scheduler specific properties.</td>
|
|
|
- <td>Not applicable</td>
|
|
|
- <td>The scheduler specific properties are the children of this
|
|
|
- element specified as a group of <property> tags described
|
|
|
- below. The JobTracker completely ignores these properties. These
|
|
|
- can be used as per-queue properties needed by the scheduler
|
|
|
- being configured. Please look at the scheduler specific
|
|
|
- documentation as to how these properties are used by that
|
|
|
- particular scheduler.
|
|
|
- </td>
|
|
|
- </tr>
|
|
|
-
|
|
|
- <tr>
|
|
|
- <td><anchor id="property_tag"/>property</td>
|
|
|
- <td>Child element of
|
|
|
- <a href="#properties_tag"><em><properties></em></a> for a
|
|
|
- specific queue.</td>
|
|
|
- <td>Not applicable</td>
|
|
|
- <td>A single scheduler specific queue-property. Ignored by
|
|
|
- the JobTracker and used by the scheduler that is configured.</td>
|
|
|
- </tr>
|
|
|
-
|
|
|
- <tr>
|
|
|
- <td>key</td>
|
|
|
- <td>Attribute of a
|
|
|
- <a href="#property_tag"><em><property></em></a> for a
|
|
|
- specific queue.</td>
|
|
|
- <td>Scheduler-specific</td>
|
|
|
- <td>The name of a single scheduler specific queue-property.</td>
|
|
|
- </tr>
|
|
|
-
|
|
|
- <tr>
|
|
|
- <td>value</td>
|
|
|
- <td>Attribute of a
|
|
|
- <a href="#property_tag"><em><property></em></a> for a
|
|
|
- specific queue.</td>
|
|
|
- <td>Scheduler-specific</td>
|
|
|
- <td>The value of a single scheduler specific queue-property.
|
|
|
- The value can be anything that is left for the proper
|
|
|
- interpretation by the scheduler that is configured.</td>
|
|
|
- </tr>
|
|
|
-
|
|
|
- </table>
|
|
|
-
|
|
|
- <p>Once the queues are configured properly and the Map/Reduce
|
|
|
- system is up and running, from the command line one can
|
|
|
- <a href="commands_manual.html#QueuesList">get the list
|
|
|
- of queues</a> and
|
|
|
- <a href="commands_manual.html#QueuesInfo">obtain
|
|
|
- information specific to each queue</a>. This information is also
|
|
|
- available from the web UI. On the web UI, queue information can be
|
|
|
- seen by going to queueinfo.jsp, linked to from the queues table-cell
|
|
|
- in the cluster-summary table. The queueinfo.jsp prints the hierarchy
|
|
|
- of queues as well as the specific information for each queue.
|
|
|
- </p>
|
|
|
-
|
|
|
- <p> Users can submit jobs only to a
|
|
|
- leaf-level queue by specifying the fully-qualified queue-name for
|
|
|
- the property name <em>mapreduce.job.queuename</em> in the job
|
|
|
- configuration. The character ':' is the queue-name delimiter and so,
|
|
|
- for e.g., if one wants to submit to a configured job-queue 'Queue-C'
|
|
|
- which is one of the sub-queues of 'Queue-B' which in-turn is a
|
|
|
- sub-queue of 'Queue-A', then the job configuration should contain
|
|
|
- property <em>mapreduce.job.queuename</em> set to the <em>
|
|
|
- <value>Queue-A:Queue-B:Queue-C</value></em></p>
|
|
|
- </section>
|
|
|
- <section>
|
|
|
- <title>Real-World Cluster Configurations</title>
|
|
|
-
|
|
|
- <p>This section lists some non-default configuration parameters which
|
|
|
- have been used to run the <em>sort</em> benchmark on very large
|
|
|
- clusters.</p>
|
|
|
-
|
|
|
- <ul>
|
|
|
- <li>
|
|
|
- <p>Some non-default configuration values used to run sort900,
|
|
|
- that is 9TB of data sorted on a cluster with 900 nodes:</p>
|
|
|
- <table>
|
|
|
- <tr>
|
|
|
- <th>Configuration File</th>
|
|
|
- <th>Parameter</th>
|
|
|
- <th>Value</th>
|
|
|
- <th>Notes</th>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>conf/hdfs-site.xml</td>
|
|
|
- <td>dfs.blocksize</td>
|
|
|
- <td>128m</td>
|
|
|
- <td>
|
|
|
- HDFS blocksize of 128 MB for large file-systems. Sizes can be provided
|
|
|
- in size-prefixed values (10k, 128m, 1g, etc.) or simply in bytes (134217728 for 128 MB, etc.).
|
|
|
- </td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>conf/hdfs-site.xml</td>
|
|
|
- <td>dfs.namenode.handler.count</td>
|
|
|
- <td>40</td>
|
|
|
- <td>
|
|
|
- More NameNode server threads to handle RPCs from large
|
|
|
- number of DataNodes.
|
|
|
- </td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>conf/mapred-site.xml</td>
|
|
|
- <td>mapreduce.reduce.shuffle.parallelcopies</td>
|
|
|
- <td>20</td>
|
|
|
- <td>
|
|
|
- Higher number of parallel copies run by reduces to fetch
|
|
|
- outputs from very large number of maps.
|
|
|
- </td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>conf/mapred-site.xml</td>
|
|
|
- <td>mapreduce.map.java.opts</td>
|
|
|
- <td>-Xmx512M</td>
|
|
|
- <td>
|
|
|
- Larger heap-size for child jvms of maps.
|
|
|
- </td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>conf/mapred-site.xml</td>
|
|
|
- <td>mapreduce.reduce.java.opts</td>
|
|
|
- <td>-Xmx512M</td>
|
|
|
- <td>
|
|
|
- Larger heap-size for child jvms of reduces.
|
|
|
- </td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>conf/mapred-site.xml</td>
|
|
|
- <td>mapreduce.reduce.shuffle.input.buffer.percent</td>
|
|
|
- <td>0.80</td>
|
|
|
- <td>
|
|
|
- Larger amount of memory allocated for merging map output
|
|
|
- in memory during the shuffle. Expressed as a fraction of
|
|
|
- the total heap.
|
|
|
- </td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>conf/mapred-site.xml</td>
|
|
|
- <td>mapreduce.reduce.input.buffer.percent</td>
|
|
|
- <td>0.80</td>
|
|
|
- <td>
|
|
|
- Larger amount of memory allocated for retaining map output
|
|
|
- in memory during the reduce. Expressed as a fraction of
|
|
|
- the total heap.
|
|
|
- </td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>conf/mapred-site.xml</td>
|
|
|
- <td>mapreduce.task.io.sort.factor</td>
|
|
|
- <td>100</td>
|
|
|
- <td>More streams merged at once while sorting files.</td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>conf/mapred-site.xml</td>
|
|
|
- <td>mapreduce.task.io.sort.mb</td>
|
|
|
- <td>200</td>
|
|
|
- <td>Higher memory-limit while sorting data.</td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>conf/core-site.xml</td>
|
|
|
- <td>io.file.buffer.size</td>
|
|
|
- <td>131072</td>
|
|
|
- <td>Size of read/write buffer used in SequenceFiles.</td>
|
|
|
- </tr>
|
|
|
- </table>
|
|
|
- </li>
|
|
|
- <li>
|
|
|
- <p>Updates to some configuration values to run sort1400 and
|
|
|
- sort2000, that is 14TB of data sorted on 1400 nodes and 20TB of
|
|
|
- data sorted on 2000 nodes:</p>
|
|
|
- <table>
|
|
|
- <tr>
|
|
|
- <th>Configuration File</th>
|
|
|
- <th>Parameter</th>
|
|
|
- <th>Value</th>
|
|
|
- <th>Notes</th>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>conf/mapred-site.xml</td>
|
|
|
- <td>mapreduce.jobtracker.handler.count</td>
|
|
|
- <td>60</td>
|
|
|
- <td>
|
|
|
- More JobTracker server threads to handle RPCs from large
|
|
|
- number of TaskTrackers.
|
|
|
- </td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>conf/mapred-site.xml</td>
|
|
|
- <td>mapreduce.reduce.shuffle.parallelcopies</td>
|
|
|
- <td>50</td>
|
|
|
- <td></td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>conf/mapred-site.xml</td>
|
|
|
- <td>mapreduce.tasktracker.http.threads</td>
|
|
|
- <td>50</td>
|
|
|
- <td>
|
|
|
- More worker threads for the TaskTracker's http server. The
|
|
|
- http server is used by reduces to fetch intermediate
|
|
|
- map-outputs.
|
|
|
- </td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>conf/mapred-site.xml</td>
|
|
|
- <td>mapreduce.map.java.opts</td>
|
|
|
- <td>-Xmx512M</td>
|
|
|
- <td>
|
|
|
- Larger heap-size for child jvms of maps.
|
|
|
- </td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>conf/mapred-site.xml</td>
|
|
|
- <td>mapreduce.reduce.java.opts</td>
|
|
|
- <td>-Xmx1024M</td>
|
|
|
- <td>Larger heap-size for child jvms of reduces.</td>
|
|
|
- </tr>
|
|
|
- </table>
|
|
|
- </li>
|
|
|
- </ul>
|
|
|
- </section>
|
|
|
- <section>
|
|
|
- <title>Configuring Memory Parameters for MapReduce Jobs</title>
|
|
|
- <p>
|
|
|
- As MapReduce jobs could use varying amounts of memory, Hadoop
|
|
|
- provides various configuration options to users and administrators
|
|
|
- for managing memory effectively. Some of these options are job
|
|
|
- specific and can be used by users. While setting up a cluster,
|
|
|
- administrators can configure appropriate default values for these
|
|
|
- options so that users jobs run out of the box. Other options are
|
|
|
- cluster specific and can be used by administrators to enforce
|
|
|
- limits and prevent misconfigured or memory intensive jobs from
|
|
|
- causing undesired side effects on the cluster.
|
|
|
- </p>
|
|
|
- <p>
|
|
|
- The values configured should
|
|
|
- take into account the hardware resources of the cluster, such as the
|
|
|
- amount of physical and virtual memory available for tasks,
|
|
|
- the number of slots configured on the slaves and the requirements
|
|
|
- for other processes running on the slaves. If right values are not
|
|
|
- set, it is likely that jobs start failing with memory related
|
|
|
- errors or in the worst case, even affect other tasks or
|
|
|
- the slaves themselves.
|
|
|
- </p>
|
|
|
-
|
|
|
- <section>
|
|
|
- <title>Monitoring Task Memory Usage</title>
|
|
|
- <p>
|
|
|
- Before describing the memory options, it is
|
|
|
- useful to look at a feature provided by Hadoop to monitor
|
|
|
- memory usage of MapReduce tasks it runs. The basic objective
|
|
|
- of this feature is to prevent MapReduce tasks from consuming
|
|
|
- memory beyond a limit that would result in their affecting
|
|
|
- other processes running on the slave, including other tasks
|
|
|
- and daemons like the DataNode or TaskTracker.
|
|
|
- </p>
|
|
|
-
|
|
|
- <p>
|
|
|
- <em>Note:</em> For the time being, this feature is available
|
|
|
- only for the Linux platform.
|
|
|
- </p>
|
|
|
-
|
|
|
- <p>
|
|
|
- Hadoop allows monitoring to be done both for virtual
|
|
|
- and physical memory usage of tasks. This monitoring
|
|
|
- can be done independently of each other, and therefore the
|
|
|
- options can be configured independently of each other. It
|
|
|
- has been found in some environments, particularly related
|
|
|
- to streaming, that virtual memory recorded for tasks is high
|
|
|
- because of libraries loaded by the programs used to run
|
|
|
- the tasks. However, this memory is largely unused and does
|
|
|
- not affect the slaves's memory itself. In such cases,
|
|
|
- monitoring based on physical memory can provide a more
|
|
|
- accurate picture of memory usage.
|
|
|
- </p>
|
|
|
-
|
|
|
- <p>
|
|
|
- This feature considers that there is a limit on
|
|
|
- the amount of virtual or physical memory on the slaves
|
|
|
- that can be used by
|
|
|
- the running MapReduce tasks. The rest of the memory is
|
|
|
- assumed to be required for the system and other processes.
|
|
|
- Since some jobs may require higher amount of memory for their
|
|
|
- tasks than others, Hadoop allows jobs to specify how much
|
|
|
- memory they expect to use at a maximum. Then by using
|
|
|
- resource aware scheduling and monitoring, Hadoop tries to
|
|
|
- ensure that at any time, only enough tasks are running on
|
|
|
- the slaves as can meet the dual constraints of an individual
|
|
|
- job's memory requirements and the total amount of memory
|
|
|
- available for all MapReduce tasks.
|
|
|
- </p>
|
|
|
-
|
|
|
- <p>
|
|
|
- The TaskTracker monitors tasks in regular intervals. Each time,
|
|
|
- it operates in two steps:
|
|
|
- </p>
|
|
|
-
|
|
|
- <ul>
|
|
|
-
|
|
|
- <li>
|
|
|
- In the first step, it
|
|
|
- checks that a job's task and any child processes it
|
|
|
- launches are not cumulatively using more virtual or physical
|
|
|
- memory than specified. If both virtual and physical memory
|
|
|
- monitoring is enabled, then virtual memory usage is checked
|
|
|
- first, followed by physical memory usage.
|
|
|
- Any task that is found to
|
|
|
- use more memory is killed along with any child processes it
|
|
|
- might have launched, and the task status is marked
|
|
|
- <em>failed</em>. Repeated failures such as this will terminate
|
|
|
- the job.
|
|
|
- </li>
|
|
|
-
|
|
|
- <li>
|
|
|
- In the next step, it checks that the cumulative virtual and
|
|
|
- physical memory
|
|
|
- used by all running tasks and their child processes
|
|
|
- does not exceed the total virtual and physical memory limit,
|
|
|
- respectively. Again, virtual memory limit is checked first,
|
|
|
- followed by physical memory limit. In this case, it kills
|
|
|
- enough number of tasks, along with any child processes they
|
|
|
- might have launched, until the cumulative memory usage
|
|
|
- is brought under limit. In the case of virtual memory limit
|
|
|
- being exceeded, the tasks chosen for killing are
|
|
|
- the ones that have made the least progress. In the case of
|
|
|
- physical memory limit being exceeded, the tasks chosen
|
|
|
- for killing are the ones that have used the maximum amount
|
|
|
- of physical memory. Also, the status
|
|
|
- of these tasks is marked as <em>killed</em>, and hence repeated
|
|
|
- occurrence of this will not result in a job failure.
|
|
|
- </li>
|
|
|
-
|
|
|
- </ul>
|
|
|
-
|
|
|
- <p>
|
|
|
- In either case, the task's diagnostic message will indicate the
|
|
|
- reason why the task was terminated.
|
|
|
- </p>
|
|
|
-
|
|
|
- <p>
|
|
|
- Resource aware scheduling can ensure that tasks are scheduled
|
|
|
- on a slave only if their memory requirement can be satisfied
|
|
|
- by the slave. The Capacity Scheduler, for example,
|
|
|
- takes virtual memory requirements into account while
|
|
|
- scheduling tasks, as described in the section on
|
|
|
- <a href="ext:capacity-scheduler/MemoryBasedTaskScheduling">
|
|
|
- memory based scheduling</a>.
|
|
|
- </p>
|
|
|
-
|
|
|
- <p>
|
|
|
- Memory monitoring is enabled when certain configuration
|
|
|
- variables are defined with non-zero values, as described below.
|
|
|
- </p>
|
|
|
-
|
|
|
- </section>
|
|
|
-
|
|
|
- <section>
|
|
|
- <title>Job Specific Options</title>
|
|
|
- <p>
|
|
|
- Memory related options that can be configured individually per
|
|
|
- job are described in detail in the section on
|
|
|
- <a href="ext:mapred-tutorial/ConfiguringMemoryRequirements">
|
|
|
- Configuring Memory Requirements For A Job</a> in the MapReduce
|
|
|
- tutorial. While setting up
|
|
|
- the cluster, the Hadoop defaults for these options can be reviewed
|
|
|
- and changed to better suit the job profiles expected to be run on
|
|
|
- the clusters, as also the hardware configuration.
|
|
|
- </p>
|
|
|
- <p>
|
|
|
- As with any other configuration option in Hadoop, if the
|
|
|
- administrators desire to prevent users from overriding these
|
|
|
- options in jobs they submit, these values can be marked as
|
|
|
- <em>final</em> in the cluster configuration.
|
|
|
- </p>
|
|
|
- </section>
|
|
|
-
|
|
|
-
|
|
|
- <section>
|
|
|
- <title>Cluster Specific Options</title>
|
|
|
-
|
|
|
- <p>
|
|
|
- This section describes the memory related options that are
|
|
|
- used by the JobTracker and TaskTrackers, and cannot be changed
|
|
|
- by jobs. The values set for these options should be the same
|
|
|
- for all the slave nodes in a cluster.
|
|
|
- </p>
|
|
|
-
|
|
|
- <ul>
|
|
|
-
|
|
|
- <li>
|
|
|
- <code>mapreduce.cluster.{map|reduce}memory.mb</code>: These
|
|
|
- options define the default amount of virtual memory that should be
|
|
|
- allocated for MapReduce tasks running in the cluster. They
|
|
|
- typically match the default values set for the options
|
|
|
- <code>mapreduce.{map|reduce}.memory.mb</code>. They help in the
|
|
|
- calculation of the total amount of virtual memory available for
|
|
|
- MapReduce tasks on a slave, using the following equation:<br/>
|
|
|
- <em>Total virtual memory for all MapReduce tasks =
|
|
|
- (mapreduce.cluster.mapmemory.mb *
|
|
|
- mapreduce.tasktracker.map.tasks.maximum) +
|
|
|
- (mapreduce.cluster.reducememory.mb *
|
|
|
- mapreduce.tasktracker.reduce.tasks.maximum)</em><br/>
|
|
|
- Typically, reduce tasks require more memory than map tasks.
|
|
|
- Hence a higher value is recommended for
|
|
|
- <em>mapreduce.cluster.reducememory.mb</em>. The value is
|
|
|
- specified in MB. To set a value of 2GB for reduce tasks, set
|
|
|
- <em>mapreduce.cluster.reducememory.mb</em> to 2048.
|
|
|
- </li>
|
|
|
-
|
|
|
- <li>
|
|
|
- <code>mapreduce.jobtracker.max{map|reduce}memory.mb</code>:
|
|
|
- These options define the maximum amount of virtual memory that
|
|
|
- can be requested by jobs using the parameters
|
|
|
- <code>mapreduce.{map|reduce}.memory.mb</code>. The system
|
|
|
- will reject any job that is submitted requesting for more
|
|
|
- memory than these limits. Typically, the values for these
|
|
|
- options should be set to satisfy the following constraint:<br/>
|
|
|
- <em>mapreduce.jobtracker.maxmapmemory.mb =
|
|
|
- mapreduce.cluster.mapmemory.mb *
|
|
|
- mapreduce.tasktracker.map.tasks.maximum<br/>
|
|
|
- mapreduce.jobtracker.maxreducememory.mb =
|
|
|
- mapreduce.cluster.reducememory.mb *
|
|
|
- mapreduce.tasktracker.reduce.tasks.maximum</em><br/>
|
|
|
- The value is specified in MB. If
|
|
|
- <code>mapreduce.cluster.reducememory.mb</code> is set to 2GB and
|
|
|
- there are 2 reduce slots configured in the slaves, the value
|
|
|
- for <code>mapreduce.jobtracker.maxreducememory.mb</code> should
|
|
|
- be set to 4096.
|
|
|
- </li>
|
|
|
-
|
|
|
- <li>
|
|
|
- <code>mapreduce.tasktracker.reserved.physicalmemory.mb</code>:
|
|
|
- This option defines the amount of physical memory that is
|
|
|
- marked for system and daemon processes. Using this, the amount
|
|
|
- of physical memory available for MapReduce tasks is calculated
|
|
|
- using the following equation:<br/>
|
|
|
- <em>Total physical memory for all MapReduce tasks =
|
|
|
- Total physical memory available on the system -
|
|
|
- mapreduce.tasktracker.reserved.physicalmemory.mb</em><br/>
|
|
|
- The value is specified in MB. To set this value to 2GB,
|
|
|
- specify the value as 2048.
|
|
|
- </li>
|
|
|
-
|
|
|
- <li>
|
|
|
- <code>mapreduce.tasktracker.taskmemorymanager.monitoringinterval</code>:
|
|
|
- This option defines the time the TaskTracker waits between
|
|
|
- two cycles of memory monitoring. The value is specified in
|
|
|
- milliseconds.
|
|
|
- </li>
|
|
|
-
|
|
|
- </ul>
|
|
|
-
|
|
|
- <p>
|
|
|
- <em>Note:</em> The virtual memory monitoring function is only
|
|
|
- enabled if
|
|
|
- the variables <code>mapreduce.cluster.{map|reduce}memory.mb</code>
|
|
|
- and <code>mapreduce.jobtracker.max{map|reduce}memory.mb</code>
|
|
|
- are set to values greater than zero. Likewise, the physical
|
|
|
- memory monitoring function is only enabled if the variable
|
|
|
- <code>mapreduce.tasktracker.reserved.physicalmemory.mb</code>
|
|
|
- is set to a value greater than zero.
|
|
|
- </p>
|
|
|
- </section>
|
|
|
- </section>
|
|
|
-
|
|
|
-
|
|
|
- <section>
|
|
|
- <title>Task Controllers</title>
|
|
|
- <p>Task controllers are classes in the Hadoop Map/Reduce
|
|
|
- framework that define how user's map and reduce tasks
|
|
|
- are launched and controlled. They can
|
|
|
- be used in clusters that require some customization in
|
|
|
- the process of launching or controlling the user tasks.
|
|
|
- For example, in some
|
|
|
- clusters, there may be a requirement to run tasks as
|
|
|
- the user who submitted the job, instead of as the task
|
|
|
- tracker user, which is how tasks are launched by default.
|
|
|
- This section describes how to configure and use
|
|
|
- task controllers.</p>
|
|
|
- <p>The following task controllers are the available in
|
|
|
- Hadoop.
|
|
|
- </p>
|
|
|
- <table>
|
|
|
- <tr><th>Name</th><th>Class Name</th><th>Description</th></tr>
|
|
|
- <tr>
|
|
|
- <td>DefaultTaskController</td>
|
|
|
- <td>org.apache.hadoop.mapred.DefaultTaskController</td>
|
|
|
- <td> The default task controller which Hadoop uses to manage task
|
|
|
- execution. The tasks run as the task tracker user.</td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>LinuxTaskController</td>
|
|
|
- <td>org.apache.hadoop.mapred.LinuxTaskController</td>
|
|
|
- <td>This task controller, which is supported only on Linux,
|
|
|
- runs the tasks as the user who submitted the job. It requires
|
|
|
- these user accounts to be created on the cluster nodes
|
|
|
- where the tasks are launched. It
|
|
|
- uses a setuid executable that is included in the Hadoop
|
|
|
- distribution. The task tracker uses this executable to
|
|
|
- launch and kill tasks. The setuid executable switches to
|
|
|
- the user who has submitted the job and launches or kills
|
|
|
- the tasks. For maximum security, this task controller
|
|
|
- sets up restricted permissions and user/group ownership of
|
|
|
- local files and directories used by the tasks such as the
|
|
|
- job jar files, intermediate files, task log files and distributed
|
|
|
- cache files. Particularly note that, because of this, except the
|
|
|
- job owner and tasktracker, no other user can access any of the
|
|
|
- local files/directories including those localized as part of the
|
|
|
- distributed cache.
|
|
|
- </td>
|
|
|
- </tr>
|
|
|
- </table>
|
|
|
- <section>
|
|
|
- <title>Configuring Task Controllers</title>
|
|
|
- <p>The task controller to be used can be configured by setting the
|
|
|
- value of the following key in mapred-site.xml</p>
|
|
|
- <table>
|
|
|
- <tr>
|
|
|
- <th>Property</th><th>Value</th><th>Notes</th>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>mapreduce.tasktracker.taskcontroller</td>
|
|
|
- <td>Fully qualified class name of the task controller class</td>
|
|
|
- <td>Currently there are two implementations of task controller
|
|
|
- in the Hadoop system, DefaultTaskController and LinuxTaskController.
|
|
|
- Refer to the class names mentioned above to determine the value
|
|
|
- to set for the class of choice.
|
|
|
- </td>
|
|
|
- </tr>
|
|
|
- </table>
|
|
|
- </section>
|
|
|
- <section>
|
|
|
- <title>Using the LinuxTaskController</title>
|
|
|
- <p>This section of the document describes the steps required to
|
|
|
- use the LinuxTaskController.</p>
|
|
|
-
|
|
|
- <p>In order to use the LinuxTaskController, a setuid executable
|
|
|
- should be built and deployed on the compute nodes. The
|
|
|
- executable is named task-controller. To build the executable,
|
|
|
- execute
|
|
|
- <em>ant task-controller -Dhadoop.conf.dir=/path/to/conf/dir.
|
|
|
- </em>
|
|
|
- The path passed in <em>-Dhadoop.conf.dir</em> should be the path
|
|
|
- on the cluster nodes where a configuration file for the setuid
|
|
|
- executable would be located. The executable would be built to
|
|
|
- <em>build.dir/dist.dir/bin</em> and should be installed to
|
|
|
- <em>$HADOOP_PREFIX/bin</em>.
|
|
|
- </p>
|
|
|
-
|
|
|
- <p>
|
|
|
- The executable must have specific permissions as follows. The
|
|
|
- executable should have <em>6050 or --Sr-s---</em> permissions
|
|
|
- user-owned by root(super-user) and group-owned by a special group
|
|
|
- of which the TaskTracker's user is the group member and no job
|
|
|
- submitter is. If any job submitter belongs to this special group,
|
|
|
- security will be compromised. This special group name should be
|
|
|
- specified for the configuration property
|
|
|
- <em>"mapreduce.tasktracker.group"</em> in both mapred-site.xml and
|
|
|
- <a href="#task-controller.cfg">task-controller.cfg</a>.
|
|
|
- For example, let's say that the TaskTracker is run as user
|
|
|
- <em>mapred</em> who is part of the groups <em>users</em> and
|
|
|
- <em>specialGroup</em> any of them being the primary group.
|
|
|
- Let also be that <em>users</em> has both <em>mapred</em> and
|
|
|
- another user (job submitter) <em>X</em> as its members, and X does
|
|
|
- not belong to <em>specialGroup</em>. Going by the above
|
|
|
- description, the setuid/setgid executable should be set
|
|
|
- <em>6050 or --Sr-s---</em> with user-owner as <em>mapred</em> and
|
|
|
- group-owner as <em>specialGroup</em> which has
|
|
|
- <em>mapred</em> as its member(and not <em>users</em> which has
|
|
|
- <em>X</em> also as its member besides <em>mapred</em>).
|
|
|
- </p>
|
|
|
-
|
|
|
- <p>
|
|
|
- The LinuxTaskController requires that paths including and leading up
|
|
|
- to the directories specified in
|
|
|
- <em>mapreduce.cluster.local.dir</em> and <em>hadoop.log.dir</em> to
|
|
|
- be set 755 permissions.
|
|
|
- </p>
|
|
|
-
|
|
|
- <section>
|
|
|
- <title>task-controller.cfg</title>
|
|
|
- <p>The executable requires a configuration file called
|
|
|
- <em>taskcontroller.cfg</em> to be
|
|
|
- present in the configuration directory passed to the ant target
|
|
|
- mentioned above. If the binary was not built with a specific
|
|
|
- conf directory, the path defaults to
|
|
|
- <em>/path-to-binary/../conf</em>. The configuration file must be
|
|
|
- owned by the user running TaskTracker (user <em>mapred</em> in the
|
|
|
- above example), group-owned by anyone and should have the
|
|
|
- permissions <em>0400 or r--------</em>.
|
|
|
- </p>
|
|
|
-
|
|
|
- <p>The executable requires following configuration items to be
|
|
|
- present in the <em>taskcontroller.cfg</em> file. The items should
|
|
|
- be mentioned as simple <em>key=value</em> pairs.
|
|
|
- </p>
|
|
|
- <table><tr><th>Name</th><th>Description</th></tr>
|
|
|
- <tr>
|
|
|
- <td>mapreduce.cluster.local.dir</td>
|
|
|
- <td>Path to mapreduce.cluster.local.directories. Should be same as the value
|
|
|
- which was provided to key in mapred-site.xml. This is required to
|
|
|
- validate paths passed to the setuid executable in order to prevent
|
|
|
- arbitrary paths being passed to it.</td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>hadoop.log.dir</td>
|
|
|
- <td>Path to hadoop log directory. Should be same as the value which
|
|
|
- the TaskTracker is started with. This is required to set proper
|
|
|
- permissions on the log files so that they can be written to by the user's
|
|
|
- tasks and read by the TaskTracker for serving on the web UI.</td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td>mapreduce.tasktracker.group</td>
|
|
|
- <td>Group to which the TaskTracker belongs. The group owner of the
|
|
|
- taskcontroller binary should be this group. Should be same as
|
|
|
- the value with which the TaskTracker is configured. This
|
|
|
- configuration is required for validating the secure access of the
|
|
|
- task-controller binary.</td>
|
|
|
- </tr>
|
|
|
- </table>
|
|
|
- </section>
|
|
|
- </section>
|
|
|
-
|
|
|
- </section>
|
|
|
- <section>
|
|
|
- <title>Monitoring Health of TaskTracker Nodes</title>
|
|
|
- <p>Hadoop Map/Reduce provides a mechanism by which administrators
|
|
|
- can configure the TaskTracker to run an administrator supplied
|
|
|
- script periodically to determine if a node is healthy or not.
|
|
|
- Administrators can determine if the node is in a healthy state
|
|
|
- by performing any checks of their choice in the script. If the
|
|
|
- script detects the node to be in an unhealthy state, it must print
|
|
|
- a line to standard output beginning with the string <em>ERROR</em>.
|
|
|
- The TaskTracker spawns the script periodically and checks its
|
|
|
- output. If the script's output contains the string <em>ERROR</em>,
|
|
|
- as described above, the node's status is reported as 'unhealthy'
|
|
|
- and the node is black-listed on the JobTracker. No further tasks
|
|
|
- will be assigned to this node. However, the
|
|
|
- TaskTracker continues to run the script, so that if the node
|
|
|
- becomes healthy again, it will be removed from the blacklisted
|
|
|
- nodes on the JobTracker automatically. The node's health
|
|
|
- along with the output of the script, if it is unhealthy, is
|
|
|
- available to the administrator in the JobTracker's web interface.
|
|
|
- The time since the node was healthy is also displayed on the
|
|
|
- web interface.
|
|
|
- </p>
|
|
|
-
|
|
|
- <section>
|
|
|
- <title>Configuring the Node Health Check Script</title>
|
|
|
- <p>The following parameters can be used to control the node health
|
|
|
- monitoring script in <em>mapred-site.xml</em>.</p>
|
|
|
- <table>
|
|
|
- <tr><th>Name</th><th>Description</th></tr>
|
|
|
- <tr><td><code>mapreduce.tasktracker.healthchecker.script.path</code></td>
|
|
|
- <td>Absolute path to the script which is periodically run by the
|
|
|
- TaskTracker to determine if the node is
|
|
|
- healthy or not. The file should be executable by the TaskTracker.
|
|
|
- If the value of this key is empty or the file does
|
|
|
- not exist or is not executable, node health monitoring
|
|
|
- is not started.</td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td><code>mapreduce.tasktracker.healthchecker.interval</code></td>
|
|
|
- <td>Frequency at which the node health script is run,
|
|
|
- in milliseconds</td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td><code>mapreduce.tasktracker.healthchecker.script.timeout</code></td>
|
|
|
- <td>Time after which the node health script will be killed by
|
|
|
- the TaskTracker if unresponsive.
|
|
|
- The node is marked unhealthy. if node health script times out.</td>
|
|
|
- </tr>
|
|
|
- <tr>
|
|
|
- <td><code>mapreduce.tasktracker.healthchecker.script.args</code></td>
|
|
|
- <td>Extra arguments that can be passed to the node health script
|
|
|
- when launched.
|
|
|
- These should be comma separated list of arguments. </td>
|
|
|
- </tr>
|
|
|
- </table>
|
|
|
- </section>
|
|
|
- </section>
|
|
|
-
|
|
|
- </section>
|
|
|
-
|
|
|
- <section>
|
|
|
- <title>Slaves</title>
|
|
|
-
|
|
|
- <p>Typically you choose one machine in the cluster to act as the
|
|
|
- <code>NameNode</code> and one machine as to act as the
|
|
|
- <code>JobTracker</code>, exclusively. The rest of the machines act as
|
|
|
- both a <code>DataNode</code> and <code>TaskTracker</code> and are
|
|
|
- referred to as <em>slaves</em>.</p>
|
|
|
-
|
|
|
- <p>List all slave hostnames or IP addresses in your
|
|
|
- <code>conf/slaves</code> file, one per line.</p>
|
|
|
- </section>
|
|
|
-
|
|
|
- <section>
|
|
|
- <title>Logging</title>
|
|
|
-
|
|
|
- <p>Hadoop uses the <a href="http://logging.apache.org/log4j/">Apache
|
|
|
- log4j</a> via the <a href="http://commons.apache.org/logging/">Apache
|
|
|
- Commons Logging</a> framework for logging. Edit the
|
|
|
- <code>conf/log4j.properties</code> file to customize the Hadoop
|
|
|
- daemons' logging configuration (log-formats and so on).</p>
|
|
|
-
|
|
|
- <section>
|
|
|
- <title>History Logging</title>
|
|
|
-
|
|
|
- <p> The job history files are stored in central location
|
|
|
- <code> mapreduce.jobtracker.jobhistory.location </code> which can be on DFS also,
|
|
|
- whose default value is <code>${HADOOP_LOG_DIR}/history</code>.
|
|
|
- The history web UI is accessible from job tracker web UI.</p>
|
|
|
-
|
|
|
- <p> The history files are also logged to user specified directory
|
|
|
- <code>mapreduce.job.userhistorylocation</code>
|
|
|
- which defaults to job output directory. The files are stored in
|
|
|
- "_logs/history/" in the specified directory. Hence, by default
|
|
|
- they will be in "mapreduce.output.fileoutputformat.outputdir/_logs/history/". User can stop
|
|
|
- logging by giving the value <code>none</code> for
|
|
|
- <code>mapreduce.job.userhistorylocation</code> </p>
|
|
|
-
|
|
|
- <p> User can view the history logs summary in specified directory
|
|
|
- using the following command <br/>
|
|
|
- <code>$ bin/hadoop job -history output-dir</code><br/>
|
|
|
- This command will print job details, failed and killed tip
|
|
|
- details. <br/>
|
|
|
- More details about the job such as successful tasks and
|
|
|
- task attempts made for each task can be viewed using the
|
|
|
- following command <br/>
|
|
|
- <code>$ bin/hadoop job -history all output-dir</code><br/></p>
|
|
|
- </section>
|
|
|
- </section>
|
|
|
-
|
|
|
- <p>Once all the necessary configuration is complete, distribute the files
|
|
|
- to the <code>HADOOP_CONF_DIR</code> directory on all the machines,
|
|
|
- typically <code>${HADOOP_PREFIX}/conf</code>.</p>
|
|
|
- </section>
|
|
|
- <section>
|
|
|
- <title>Cluster Restartability</title>
|
|
|
- <section>
|
|
|
- <title>Map/Reduce</title>
|
|
|
- <p>The job tracker restart can recover running jobs if
|
|
|
- <code>mapreduce.jobtracker.restart.recover</code> is set true and
|
|
|
- <a href="#Logging">JobHistory logging</a> is enabled. Also
|
|
|
- <code>mapreduce.jobtracker.jobhistory.block.size</code> value should be
|
|
|
- set to an optimal value to dump job history to disk as soon as
|
|
|
- possible, the typical value is 3145728(3MB).</p>
|
|
|
- </section>
|
|
|
- </section>
|
|
|
-
|
|
|
- <section>
|
|
|
- <title>Hadoop Rack Awareness</title>
|
|
|
- <p>
|
|
|
- Both HDFS and Map/Reduce components are rack-aware. HDFS block placement will use rack
|
|
|
- awareness for fault tolerance by placing one block replica on a different rack. This provides
|
|
|
- data availability in the event of a network switch failure within the cluster. The jobtracker uses rack
|
|
|
- awareness to reduce network transfers of HDFS data blocks by attempting to schedule tasks on datanodes with a local
|
|
|
- copy of needed HDFS blocks. If the tasks cannot be scheduled on the datanodes
|
|
|
- containing the needed HDFS blocks, then the tasks will be scheduled on the same rack to reduce network transfers if possible.
|
|
|
- </p>
|
|
|
- <p>The NameNode and the JobTracker obtain the rack id of the cluster slaves by invoking either
|
|
|
- an external script or java class as specified by configuration files. Using either the
|
|
|
- java class or external script for topology, output must adhere to the java
|
|
|
- <a href="ext:api/org/apache/hadoop/net/dnstoswitchmapping/resolve">DNSToSwitchMapping</a>
|
|
|
- interface. The interface expects a one-to-one correspondence to be maintained
|
|
|
- and the topology information in the format of '/myrack/myhost', where '/' is the topology
|
|
|
- delimiter, 'myrack' is the rack identifier, and 'myhost' is the individual host. Assuming
|
|
|
- a single /24 subnet per rack, one could use the format of '/192.168.100.0/192.168.100.5' as a
|
|
|
- unique rack-host topology mapping.
|
|
|
- </p>
|
|
|
- <p>
|
|
|
- To use the java class for topology mapping, the class name is specified by the
|
|
|
- <code>'topology.node.switch.mapping.impl'</code> parameter in the configuration file.
|
|
|
- An example, NetworkTopology.java, is included with the hadoop distribution and can be customized
|
|
|
- by the hadoop administrator. If not included with your distribution, NetworkTopology.java can also be found in the Hadoop
|
|
|
- <a href="http://svn.apache.org/viewvc/hadoop/common/trunk/hadoop-common-project/hadoop-common/src/main/java/org/apache/hadoop/net/NetworkTopology.java?view=markup">
|
|
|
- subversion tree</a>. Using a java class instead of an external script has a slight performance benefit in
|
|
|
- that it doesn't need to fork an external process when a new slave node registers itself with the jobtracker or namenode.
|
|
|
- As this class is only used during slave node registration, the performance benefit is limited.
|
|
|
- </p>
|
|
|
- <p>
|
|
|
- If implementing an external script, it will be specified with the
|
|
|
- <code>topology.script.file.name</code> parameter in the configuration files. Unlike the java
|
|
|
- class, the external topology script is not included with the Hadoop distribution and is provided by the
|
|
|
- administrator. Hadoop will send multiple IP addresses to ARGV when forking the topology script. The
|
|
|
- number of IP addresses sent to the topology script is controlled with <code>net.topology.script.number.args</code>
|
|
|
- and defaults to 100. If <code>net.topology.script.number.args</code> was changed to 1, a topology script would
|
|
|
- get forked for each IP submitted by datanodes and/or tasktrackers. Below are example topology scripts.
|
|
|
- </p>
|
|
|
- <section>
|
|
|
- <title>Python example</title>
|
|
|
- <source>
|
|
|
- <code>
|
|
|
- #!/usr/bin/python
|
|
|
-
|
|
|
- # this script makes assumptions about the physical environment.
|
|
|
- # 1) each rack is its own layer 3 network with a /24 subnet, which could be typical where each rack has its own
|
|
|
- # switch with uplinks to a central core router.
|
|
|
- #
|
|
|
- # +-----------+
|
|
|
- # |core router|
|
|
|
- # +-----------+
|
|
|
- # / \
|
|
|
- # +-----------+ +-----------+
|
|
|
- # |rack switch| |rack switch|
|
|
|
- # +-----------+ +-----------+
|
|
|
- # | data node | | data node |
|
|
|
- # +-----------+ +-----------+
|
|
|
- # | data node | | data node |
|
|
|
- # +-----------+ +-----------+
|
|
|
- #
|
|
|
- # 2) topology script gets list of IP's as input, calculates network address, and prints '/network_address/ip'.
|
|
|
-
|
|
|
- import netaddr
|
|
|
- import sys
|
|
|
- sys.argv.pop(0) # discard name of topology script from argv list as we just want IP addresses
|
|
|
-
|
|
|
- netmask = '255.255.255.0' # set netmask to what's being used in your environment. The example uses a /24
|
|
|
-
|
|
|
- for ip in sys.argv: # loop over list of datanode IP's
|
|
|
- address = '{0}/{1}'.format(ip, netmask) # format address string so it looks like 'ip/netmask' to make netaddr work
|
|
|
- try:
|
|
|
- network_address = netaddr.IPNetwork(address).network # calculate and print network address
|
|
|
- print "/{0}".format(network_address)
|
|
|
- except:
|
|
|
- print "/rack-unknown" # print catch-all value if unable to calculate network address
|
|
|
-
|
|
|
- </code>
|
|
|
- </source>
|
|
|
- </section>
|
|
|
-
|
|
|
- <section>
|
|
|
- <title>Bash example</title>
|
|
|
- <source>
|
|
|
- <code>
|
|
|
- #!/bin/bash
|
|
|
- # Here's a bash example to show just how simple these scripts can be
|
|
|
-
|
|
|
- # Assuming we have flat network with everything on a single switch, we can fake a rack topology.
|
|
|
- # This could occur in a lab environment where we have limited nodes,like 2-8 physical machines on a unmanaged switch.
|
|
|
- # This may also apply to multiple virtual machines running on the same physical hardware.
|
|
|
- # The number of machines isn't important, but that we are trying to fake a network topology when there isn't one.
|
|
|
- #
|
|
|
- # +----------+ +--------+
|
|
|
- # |jobtracker| |datanode|
|
|
|
- # +----------+ +--------+
|
|
|
- # \ /
|
|
|
- # +--------+ +--------+ +--------+
|
|
|
- # |datanode|--| switch |--|datanode|
|
|
|
- # +--------+ +--------+ +--------+
|
|
|
- # / \
|
|
|
- # +--------+ +--------+
|
|
|
- # |datanode| |namenode|
|
|
|
- # +--------+ +--------+
|
|
|
- #
|
|
|
- # With this network topology, we are treating each host as a rack. This is being done by taking the last octet
|
|
|
- # in the datanode's IP and prepending it with the word '/rack-'. The advantage for doing this is so HDFS
|
|
|
- # can create its 'off-rack' block copy.
|
|
|
-
|
|
|
- # 1) 'echo $@' will echo all ARGV values to xargs.
|
|
|
- # 2) 'xargs' will enforce that we print a single argv value per line
|
|
|
- # 3) 'awk' will split fields on dots and append the last field to the string '/rack-'. If awk
|
|
|
- # fails to split on four dots, it will still print '/rack-' last field value
|
|
|
-
|
|
|
- echo $@ | xargs -n 1 | awk -F '.' '{print "/rack-"$NF}'
|
|
|
-
|
|
|
-
|
|
|
- </code>
|
|
|
- </source>
|
|
|
- </section>
|
|
|
-
|
|
|
-
|
|
|
- <p>
|
|
|
- If <code>topology.script.file.name</code> or <code>topology.node.switch.mapping.impl</code> is
|
|
|
- not set, the rack id '/default-rack' is returned for any passed IP address.
|
|
|
- While this behavior appears desirable, it can cause issues with HDFS block replication as
|
|
|
- default behavior is to write one replicated block off rack and is unable to do so as there is
|
|
|
- only a single rack named '/default-rack'.
|
|
|
- </p>
|
|
|
- <p>
|
|
|
- An additional configuration setting is <code>mapred.cache.task.levels</code> which determines
|
|
|
- the number of levels (in the network topology) of caches. So, for example, if it is the
|
|
|
- default value of 2, two levels of caches will be constructed - one for hosts
|
|
|
- (host -> task mapping) and another for racks (rack -> task mapping). Giving us our one-to-one
|
|
|
- mapping of '/myrack/myhost'
|
|
|
- </p>
|
|
|
- </section>
|
|
|
-
|
|
|
- <section>
|
|
|
- <title>Hadoop Startup</title>
|
|
|
-
|
|
|
- <p>To start a Hadoop cluster you will need to start both the HDFS and
|
|
|
- Map/Reduce cluster.</p>
|
|
|
-
|
|
|
- <p>
|
|
|
- Format a new distributed filesystem:<br/>
|
|
|
- <code>$ bin/hadoop namenode -format</code>
|
|
|
- </p>
|
|
|
-
|
|
|
- <p>
|
|
|
- Start the HDFS with the following command, run on the designated
|
|
|
- <code>NameNode</code>:<br/>
|
|
|
- <code>$ bin/start-dfs.sh</code>
|
|
|
- </p>
|
|
|
- <p>The <code>bin/start-dfs.sh</code> script also consults the
|
|
|
- <code>${HADOOP_CONF_DIR}/slaves</code> file on the <code>NameNode</code>
|
|
|
- and starts the <code>DataNode</code> daemon on all the listed slaves.</p>
|
|
|
-
|
|
|
- <p>
|
|
|
- Start Map-Reduce with the following command, run on the designated
|
|
|
- <code>JobTracker</code>:<br/>
|
|
|
- <code>$ bin/start-mapred.sh</code>
|
|
|
- </p>
|
|
|
- <p>The <code>bin/start-mapred.sh</code> script also consults the
|
|
|
- <code>${HADOOP_CONF_DIR}/slaves</code> file on the <code>JobTracker</code>
|
|
|
- and starts the <code>TaskTracker</code> daemon on all the listed slaves.
|
|
|
- </p>
|
|
|
- </section>
|
|
|
-
|
|
|
- <section>
|
|
|
- <title>Hadoop Shutdown</title>
|
|
|
-
|
|
|
- <p>
|
|
|
- Stop HDFS with the following command, run on the designated
|
|
|
- <code>NameNode</code>:<br/>
|
|
|
- <code>$ bin/stop-dfs.sh</code>
|
|
|
- </p>
|
|
|
- <p>The <code>bin/stop-dfs.sh</code> script also consults the
|
|
|
- <code>${HADOOP_CONF_DIR}/slaves</code> file on the <code>NameNode</code>
|
|
|
- and stops the <code>DataNode</code> daemon on all the listed slaves.</p>
|
|
|
-
|
|
|
- <p>
|
|
|
- Stop Map/Reduce with the following command, run on the designated
|
|
|
- the designated <code>JobTracker</code>:<br/>
|
|
|
- <code>$ bin/stop-mapred.sh</code><br/>
|
|
|
- </p>
|
|
|
- <p>The <code>bin/stop-mapred.sh</code> script also consults the
|
|
|
- <code>${HADOOP_CONF_DIR}/slaves</code> file on the <code>JobTracker</code>
|
|
|
- and stops the <code>TaskTracker</code> daemon on all the listed slaves.</p>
|
|
|
- </section>
|
|
|
- </body>
|
|
|
-
|
|
|
-</document>
|

 Alejandro Abdelnur
Alejandro Abdelnur
{kind=link}
{kind=link}
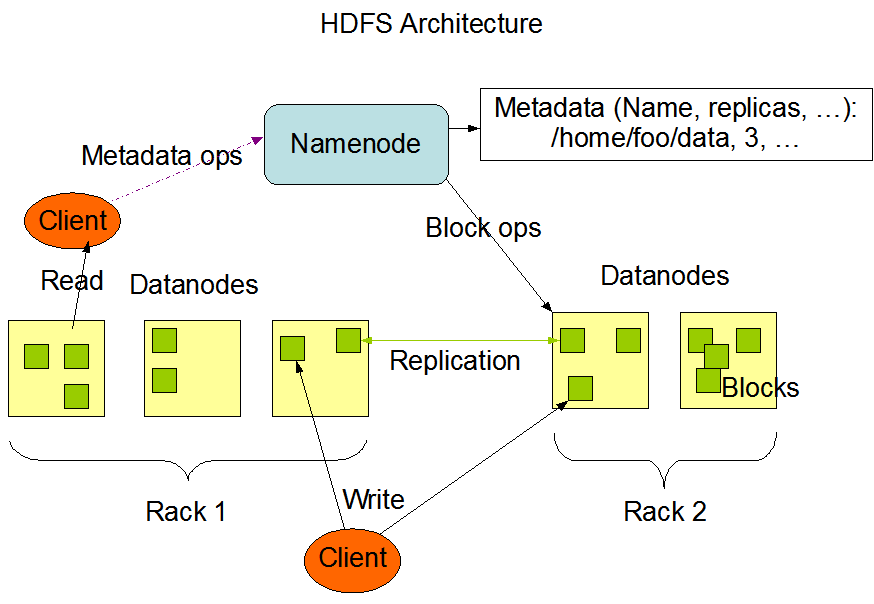
{kind=link}

{kind=link}
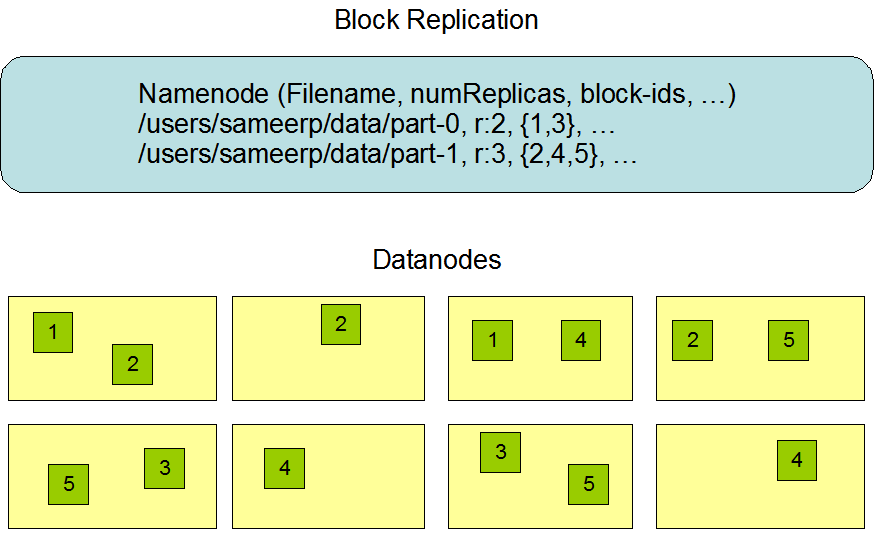
{kind=link}

{kind=link}
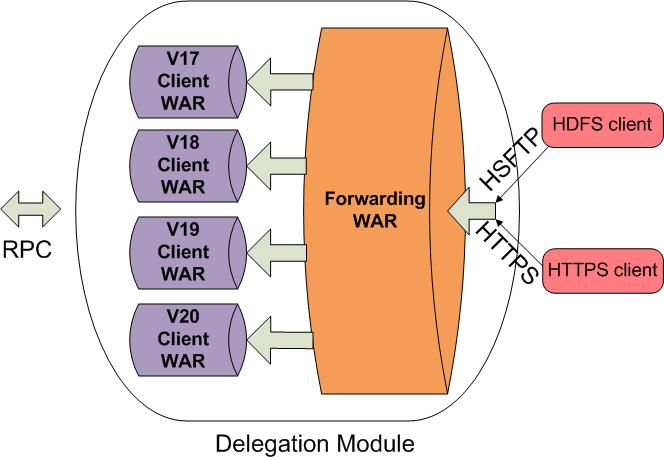
{kind=link}

{kind=link}
