
 Alejandro Abdelnur
Alejandro Abdelnur
100 změnil soubory, kde provedl 978 přidání a 130 odebrání
+ 2
- 0
hadoop-common-project/hadoop-common/CHANGES.txt
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 6
- 0
hadoop-mapreduce-project/hadoop-mapreduce-client/hadoop-mapreduce-client-jobclient/pom.xml
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 2
- 2
hadoop-mapreduce-project/src/test/mapred/org/apache/hadoop/mapred/ClusterMapReduceTestCase.java → hadoop-mapreduce-project/hadoop-mapreduce-client/hadoop-mapreduce-client-jobclient/src/test/java/org/apache/hadoop/mapred/ClusterMapReduceTestCase.java
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 0
hadoop-mapreduce-project/src/test/mapred/org/apache/hadoop/mapreduce/MapReduceTestUtil.java → hadoop-mapreduce-project/hadoop-mapreduce-client/hadoop-mapreduce-client-jobclient/src/test/java/org/apache/hadoop/mapreduce/MapReduceTestUtil.java
+ 48
- 0
hadoop-mapreduce-project/hadoop-mapreduce-examples/pom.xml
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/AggregateWordCount.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/AggregateWordCount.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/AggregateWordHistogram.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/AggregateWordHistogram.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/BaileyBorweinPlouffe.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/BaileyBorweinPlouffe.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/DBCountPageView.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/DBCountPageView.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/ExampleDriver.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/ExampleDriver.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/Grep.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/Grep.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/Join.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/Join.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/MultiFileWordCount.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/MultiFileWordCount.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/QuasiMonteCarlo.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/QuasiMonteCarlo.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/RandomTextWriter.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/RandomTextWriter.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/RandomWriter.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/RandomWriter.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/SecondarySort.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/SecondarySort.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/Sort.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/Sort.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/WordCount.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/WordCount.java
+ 196
- 0
hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/WordMean.java
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 208
- 0
hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/WordMedian.java
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 210
- 0
hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/WordStandardDeviation.java
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/dancing/DancingLinks.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/dancing/DancingLinks.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/dancing/DistributedPentomino.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/dancing/DistributedPentomino.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/dancing/OneSidedPentomino.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/dancing/OneSidedPentomino.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/dancing/Pentomino.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/dancing/Pentomino.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/dancing/Sudoku.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/dancing/Sudoku.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/dancing/package.html → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/dancing/package.html
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/dancing/puzzle1.dta → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/dancing/puzzle1.dta
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/package.html → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/package.html
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/pi/Combinable.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/pi/Combinable.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/pi/Container.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/pi/Container.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/pi/DistBbp.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/pi/DistBbp.java
+ 7
- 4
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/pi/DistSum.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/pi/DistSum.java
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/pi/Parser.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/pi/Parser.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/pi/SummationWritable.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/pi/SummationWritable.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/pi/TaskResult.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/pi/TaskResult.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/pi/Util.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/pi/Util.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/pi/math/ArithmeticProgression.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/pi/math/ArithmeticProgression.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/pi/math/Bellard.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/pi/math/Bellard.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/pi/math/LongLong.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/pi/math/LongLong.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/pi/math/Modular.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/pi/math/Modular.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/pi/math/Montgomery.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/pi/math/Montgomery.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/pi/math/Summation.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/pi/math/Summation.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/pi/math/package.html → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/pi/math/package.html
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/pi/package.html → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/pi/package.html
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/terasort/2009-write-up/.gitignore → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/terasort/2009-write-up/.gitignore
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/terasort/2009-write-up/100TBTaskTime.png → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/terasort/2009-write-up/100TBTaskTime.png
{kind=link}

+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/terasort/2009-write-up/1PBTaskTime.png → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/terasort/2009-write-up/1PBTaskTime.png
{kind=link}
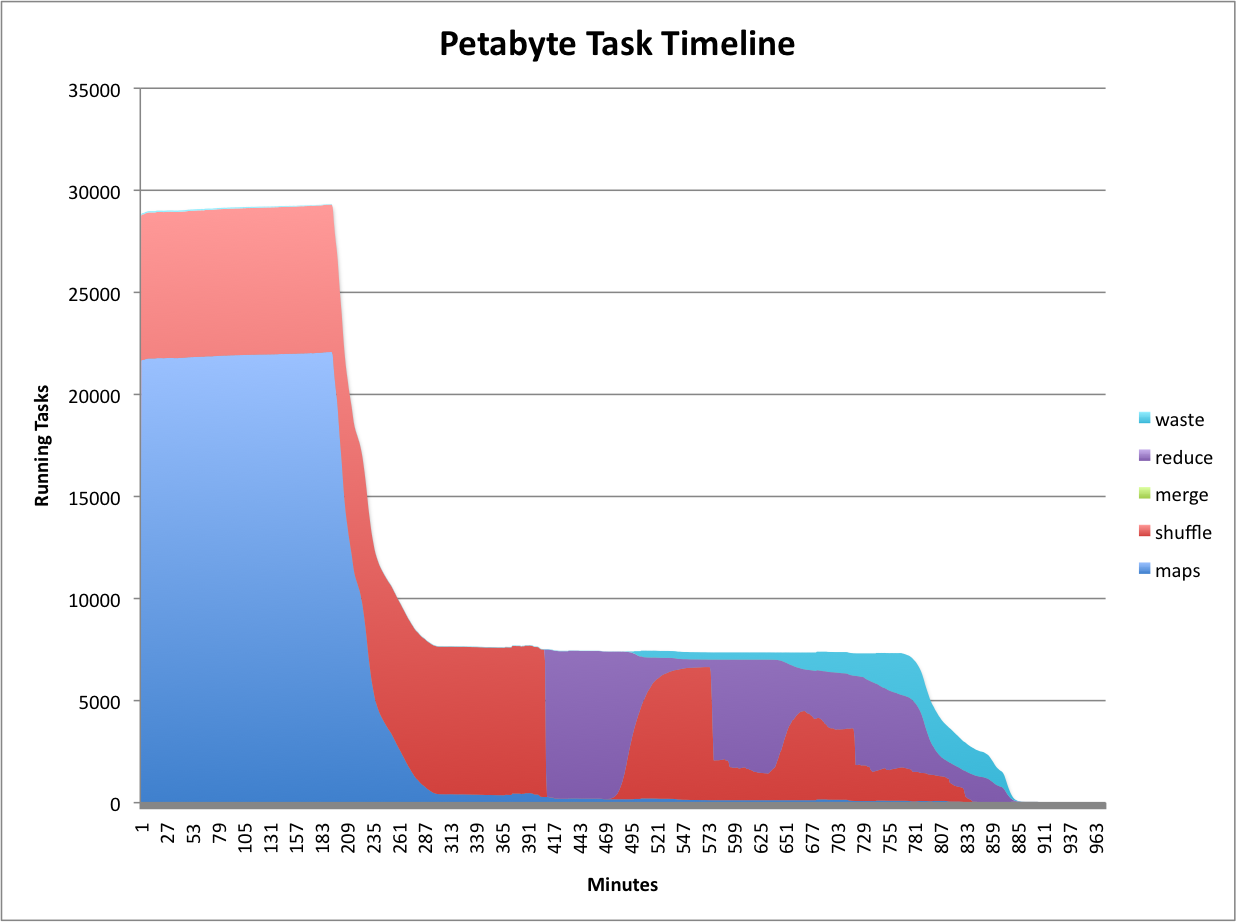
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/terasort/2009-write-up/1TBTaskTime.png → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/terasort/2009-write-up/1TBTaskTime.png
{kind=link}
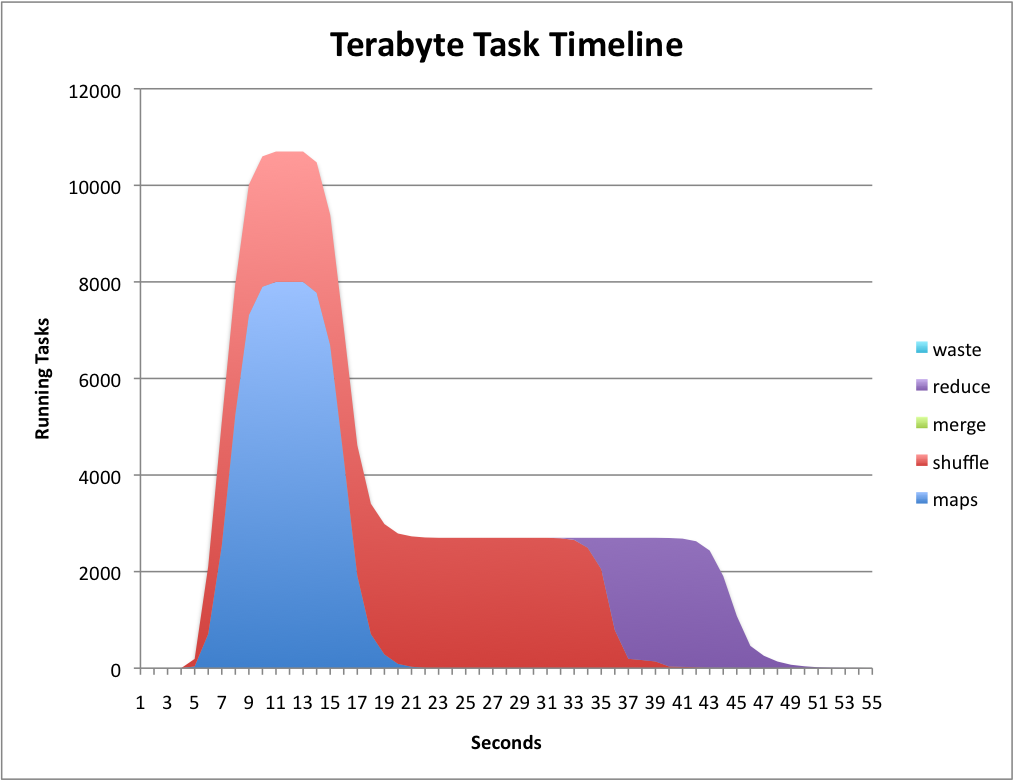
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/terasort/2009-write-up/500GBTaskTime.png → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/terasort/2009-write-up/500GBTaskTime.png
{kind=link}
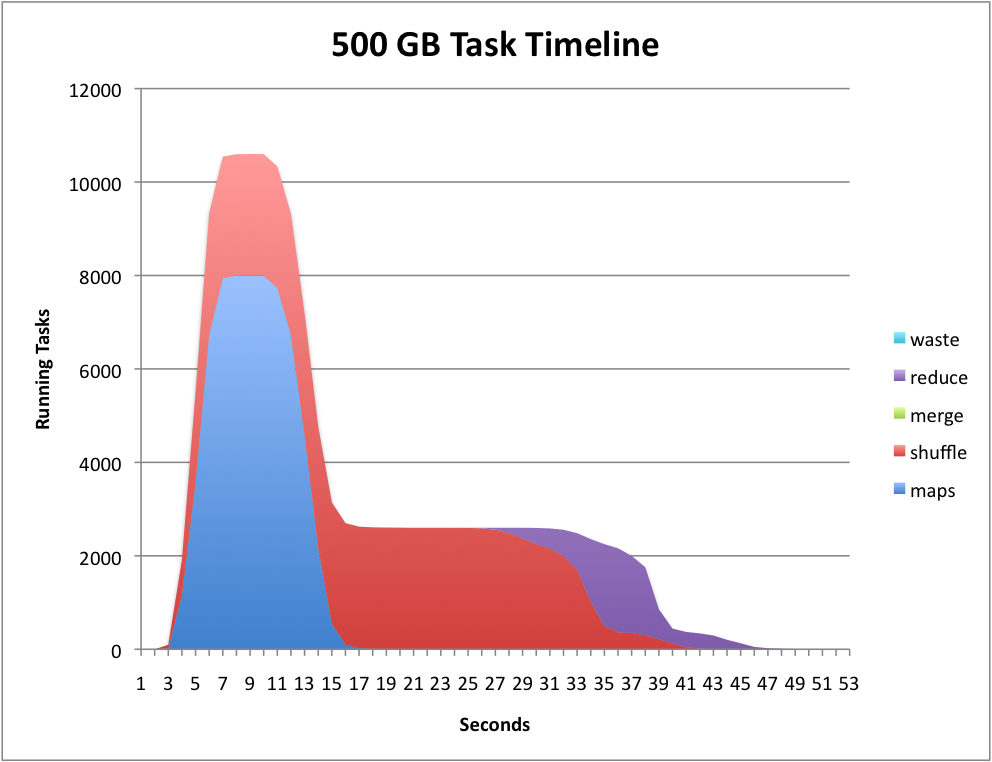
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/terasort/2009-write-up/Yahoo2009.tex → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/terasort/2009-write-up/Yahoo2009.tex
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/terasort/2009-write-up/tera.bib → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/terasort/2009-write-up/tera.bib
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/terasort/GenSort.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/terasort/GenSort.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/terasort/Random16.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/terasort/Random16.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/terasort/TeraChecksum.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/terasort/TeraChecksum.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/terasort/TeraGen.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/terasort/TeraGen.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/terasort/TeraInputFormat.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/terasort/TeraInputFormat.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/terasort/TeraOutputFormat.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/terasort/TeraOutputFormat.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/terasort/TeraScheduler.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/terasort/TeraScheduler.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/terasort/TeraSort.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/terasort/TeraSort.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/terasort/TeraValidate.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/terasort/TeraValidate.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/terasort/Unsigned16.java → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/terasort/Unsigned16.java
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/terasort/job_history_summary.py → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/terasort/job_history_summary.py
+ 0
- 0
hadoop-mapreduce-project/src/examples/org/apache/hadoop/examples/terasort/package.html → hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/terasort/package.html
+ 8
- 7
hadoop-mapreduce-project/pom.xml
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 53
- 0
hadoop-project/pom.xml
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 121
- 0
hadoop-tools/hadoop-streaming/pom.xml
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 0
hadoop-mapreduce-project/src/contrib/streaming/src/java/org/apache/hadoop/streaming/AutoInputFormat.java → hadoop-tools/hadoop-streaming/src/main/java/org/apache/hadoop/streaming/AutoInputFormat.java
+ 0
- 0
hadoop-mapreduce-project/src/contrib/streaming/src/java/org/apache/hadoop/streaming/DumpTypedBytes.java → hadoop-tools/hadoop-streaming/src/main/java/org/apache/hadoop/streaming/DumpTypedBytes.java
+ 0
- 0
hadoop-mapreduce-project/src/contrib/streaming/src/java/org/apache/hadoop/streaming/Environment.java → hadoop-tools/hadoop-streaming/src/main/java/org/apache/hadoop/streaming/Environment.java
+ 0
- 0
hadoop-mapreduce-project/src/contrib/streaming/src/java/org/apache/hadoop/streaming/HadoopStreaming.java → hadoop-tools/hadoop-streaming/src/main/java/org/apache/hadoop/streaming/HadoopStreaming.java
+ 0
- 0
hadoop-mapreduce-project/src/contrib/streaming/src/java/org/apache/hadoop/streaming/JarBuilder.java → hadoop-tools/hadoop-streaming/src/main/java/org/apache/hadoop/streaming/JarBuilder.java
+ 0
- 0
hadoop-mapreduce-project/src/contrib/streaming/src/java/org/apache/hadoop/streaming/LoadTypedBytes.java → hadoop-tools/hadoop-streaming/src/main/java/org/apache/hadoop/streaming/LoadTypedBytes.java
+ 0
- 0
hadoop-mapreduce-project/src/contrib/streaming/src/java/org/apache/hadoop/streaming/PathFinder.java → hadoop-tools/hadoop-streaming/src/main/java/org/apache/hadoop/streaming/PathFinder.java
+ 0
- 0
hadoop-mapreduce-project/src/contrib/streaming/src/java/org/apache/hadoop/streaming/PipeCombiner.java → hadoop-tools/hadoop-streaming/src/main/java/org/apache/hadoop/streaming/PipeCombiner.java
+ 0
- 0
hadoop-mapreduce-project/src/contrib/streaming/src/java/org/apache/hadoop/streaming/PipeMapRed.java → hadoop-tools/hadoop-streaming/src/main/java/org/apache/hadoop/streaming/PipeMapRed.java
+ 0
- 0
hadoop-mapreduce-project/src/contrib/streaming/src/java/org/apache/hadoop/streaming/PipeMapRunner.java → hadoop-tools/hadoop-streaming/src/main/java/org/apache/hadoop/streaming/PipeMapRunner.java
+ 0
- 0
hadoop-mapreduce-project/src/contrib/streaming/src/java/org/apache/hadoop/streaming/PipeMapper.java → hadoop-tools/hadoop-streaming/src/main/java/org/apache/hadoop/streaming/PipeMapper.java
+ 0
- 0
hadoop-mapreduce-project/src/contrib/streaming/src/java/org/apache/hadoop/streaming/PipeReducer.java → hadoop-tools/hadoop-streaming/src/main/java/org/apache/hadoop/streaming/PipeReducer.java
+ 0
- 0
hadoop-mapreduce-project/src/contrib/streaming/src/java/org/apache/hadoop/streaming/StreamBaseRecordReader.java → hadoop-tools/hadoop-streaming/src/main/java/org/apache/hadoop/streaming/StreamBaseRecordReader.java
+ 0
- 0
hadoop-mapreduce-project/src/contrib/streaming/src/java/org/apache/hadoop/streaming/StreamInputFormat.java → hadoop-tools/hadoop-streaming/src/main/java/org/apache/hadoop/streaming/StreamInputFormat.java
+ 117
- 117
hadoop-mapreduce-project/src/contrib/streaming/src/java/org/apache/hadoop/streaming/StreamJob.java → hadoop-tools/hadoop-streaming/src/main/java/org/apache/hadoop/streaming/StreamJob.java
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||