|
|
@@ -0,0 +1,10969 @@
|
|
|
+Hadoop Change Log
|
|
|
+
|
|
|
+Trunk (unreleased changes)
|
|
|
+
|
|
|
+ INCOMPATIBLE CHANGES
|
|
|
+
|
|
|
+ HADOOP-6904. Support method based RPC compatiblity. (hairong)
|
|
|
+
|
|
|
+ HADOOP-6432. Add Statistics support in FileContext. (jitendra)
|
|
|
+
|
|
|
+ HADOOP-7136. Remove failmon contrib component. (nigel)
|
|
|
+
|
|
|
+ NEW FEATURES
|
|
|
+
|
|
|
+ HADOOP-7342. Add an utility API in FileUtil for JDK File.list
|
|
|
+ avoid NPEs on File.list() (Bharath Mundlapudi via mattf)
|
|
|
+
|
|
|
+ HADOOP-7322. Adding a util method in FileUtil for directory listing,
|
|
|
+ avoid NPEs on File.listFiles() (Bharath Mundlapudi via mattf)
|
|
|
+
|
|
|
+ HADOOP-7023. Add listCorruptFileBlocks to Filesysem. (Patrick Kling
|
|
|
+ via hairong)
|
|
|
+
|
|
|
+ HADOOP-7096. Allow setting of end-of-record delimiter for TextInputFormat
|
|
|
+ (Ahmed Radwan via todd)
|
|
|
+
|
|
|
+ HADOOP-6994. Api to get delegation token in AbstractFileSystem. (jitendra)
|
|
|
+
|
|
|
+ HADOOP-7171. Support UGI in FileContext API. (jitendra)
|
|
|
+
|
|
|
+ HADOOP-7257 Client side mount tables (sanjay)
|
|
|
+
|
|
|
+ HADOOP-6919. New metrics2 framework. (Luke Lu via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-6920. Metrics instrumentation to move new metrics2 framework.
|
|
|
+ (Luke Lu via suresh)
|
|
|
+
|
|
|
+ HADOOP-7214. Add Common functionality necessary to provide an equivalent
|
|
|
+ of /usr/bin/groups for Hadoop. (Aaron T. Myers via todd)
|
|
|
+
|
|
|
+ HADOOP-6832. Add an authentication plugin using a configurable static user
|
|
|
+ for the web UI. (Owen O'Malley and Todd Lipcon via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-7144. Expose JMX metrics via JSON servlet. (Robert Joseph Evans via
|
|
|
+ cdouglas)
|
|
|
+
|
|
|
+ IMPROVEMENTS
|
|
|
+
|
|
|
+ HADOOP-7042. Updates to test-patch.sh to include failed test names and
|
|
|
+ improve other messaging. (nigel)
|
|
|
+
|
|
|
+ HADOOP-7001. Configuration changes can occur via the Reconfigurable
|
|
|
+ interface. (Patrick Kling via dhruba)
|
|
|
+
|
|
|
+ HADOOP-6764. Add number of reader threads and queue length as
|
|
|
+ configuration parameters in RPC.getServer. (Dmytro Molkov via hairong)
|
|
|
+
|
|
|
+ HADOOP-7049. TestReconfiguration should be junit v4.
|
|
|
+ (Patrick Kling via eli)
|
|
|
+
|
|
|
+ HADOOP-7054 Change NN LoadGenerator to use FileContext APIs
|
|
|
+ (Sanjay Radia)
|
|
|
+
|
|
|
+ HADOOP-7060. A more elegant FileSystem#listCorruptFileBlocks API.
|
|
|
+ (Patrick Kling via hairong)
|
|
|
+
|
|
|
+ HADOOP-7058. Expose number of bytes in FSOutputSummer buffer to
|
|
|
+ implementatins. (Todd Lipcon via hairong)
|
|
|
+
|
|
|
+ HADOOP-7061. unprecise javadoc for CompressionCodec. (Jingguo Yao via eli)
|
|
|
+
|
|
|
+ HADOOP-7059. Remove "unused" warning in native code. (Noah Watkins via eli)
|
|
|
+
|
|
|
+ HADOOP-6864. Provide a JNI-based implementation of
|
|
|
+ ShellBasedUnixGroupsNetgroupMapping
|
|
|
+ (implementation of GroupMappingServiceProvider) (Erik Seffl via boryas)
|
|
|
+
|
|
|
+ HADOOP-7078. Improve javadocs for RawComparator interface.
|
|
|
+ (Harsh J Chouraria via todd)
|
|
|
+
|
|
|
+ HADOOP-6995. Allow wildcards to be used in ProxyUsers configurations.
|
|
|
+ (todd)
|
|
|
+
|
|
|
+ HADOOP-6376. Add a comment header to conf/slaves that specifies the file
|
|
|
+ format. (Kay Kay via todd)
|
|
|
+
|
|
|
+ HADOOP-7151. Document need for stable hashCode() in WritableComparable.
|
|
|
+ (Dmitriy V. Ryaboy via todd)
|
|
|
+
|
|
|
+ HADOOP-7112. Issue a warning when GenericOptionsParser libjars are not on
|
|
|
+ local filesystem. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-7114. FsShell should dump all exceptions at DEBUG level.
|
|
|
+ (todd via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-7159. RPC server should log the client hostname when read exception
|
|
|
+ happened. (Scott Chen via todd)
|
|
|
+
|
|
|
+ HADOOP-7167. Allow using a file to exclude certain tests from build. (todd)
|
|
|
+
|
|
|
+ HADOOP-7133. Batch the calls in DataStorage to FileUtil.createHardLink().
|
|
|
+ (Matt Foley via jghoman)
|
|
|
+
|
|
|
+ HADOOP-7166. Add DaemonFactory to common. (Erik Steffl & jitendra)
|
|
|
+
|
|
|
+ HADOOP-7175. Add isEnabled() to Trash. (Daryn Sharp via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7180. Better support on CommandFormat on the API and exceptions.
|
|
|
+ (Daryn Sharp via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7202. Improve shell Command base class. (Daryn Sharp via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7224. Add CommandFactory to shell. (Daryn Sharp via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7014. Generalize CLITest structure and interfaces to facilitate
|
|
|
+ upstream adoption (e.g. for web testing). (cos)
|
|
|
+
|
|
|
+ HADOOP-7230. Move "fs -help" shell command tests from HDFS to COMMOM; see
|
|
|
+ also HDFS-1844. (Daryn Sharp via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7233. Refactor ls to conform to new FsCommand class. (Daryn Sharp
|
|
|
+ via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7235. Refactor the tail command to conform to new FsCommand class.
|
|
|
+ (Daryn Sharp via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7179. Federation: Improve HDFS startup scripts. (Erik Steffl
|
|
|
+ and Tanping Wang via suresh)
|
|
|
+
|
|
|
+ HADOOP-7227. Remove protocol version check at proxy creation in Hadoop
|
|
|
+ RPC. (jitendra)
|
|
|
+
|
|
|
+ HADOOP-7236. Refactor the mkdir command to conform to new FsCommand class.
|
|
|
+ (Daryn Sharp via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7250. Refactor the setrep command to conform to new FsCommand class.
|
|
|
+ (Daryn Sharp via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7249. Refactor the chmod/chown/chgrp command to conform to new
|
|
|
+ FsCommand class. (Daryn Sharp via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7251. Refactor the getmerge command to conform to new FsCommand
|
|
|
+ class. (Daryn Sharp via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7265. Keep track of relative paths in PathData. (Daryn Sharp
|
|
|
+ via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7238. Refactor the cat and text commands to conform to new FsCommand
|
|
|
+ class. (Daryn Sharp via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7271. Standardize shell command error messages. (Daryn Sharp
|
|
|
+ via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7272. Remove unnecessary security related info logs. (suresh)
|
|
|
+
|
|
|
+ HADOOP-7275. Refactor the stat command to conform to new FsCommand
|
|
|
+ class. (Daryn Sharp via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7237. Refactor the touchz command to conform to new FsCommand
|
|
|
+ class. (Daryn Sharp via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7267. Refactor the rm/rmr/expunge commands to conform to new
|
|
|
+ FsCommand class. (Daryn Sharp via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7285. Refactor the test command to conform to new FsCommand
|
|
|
+ class. (Daryn Sharp via todd)
|
|
|
+
|
|
|
+ HADOOP-7289. In ivy.xml, test conf should not extend common conf.
|
|
|
+ (Eric Yang via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7291. Update Hudson job not to run test-contrib. (Nigel Daley via eli)
|
|
|
+
|
|
|
+ HADOOP-7286. Refactor the du/dus/df commands to conform to new FsCommand
|
|
|
+ class. (Daryn Sharp via todd)
|
|
|
+
|
|
|
+ HADOOP-7301. FSDataInputStream should expose a getWrappedStream method.
|
|
|
+ (Jonathan Hsieh via eli)
|
|
|
+
|
|
|
+ HADOOP-7306. Start metrics system even if config files are missing
|
|
|
+ (Luke Lu via todd)
|
|
|
+
|
|
|
+ HADOOP-7302. webinterface.private.actions should be renamed and moved to
|
|
|
+ the MapReduce project. (Ari Rabkin via todd)
|
|
|
+
|
|
|
+ HADOOP-7329. Improve help message for "df" to include "-h" flag.
|
|
|
+ (Xie Xianshan via todd)
|
|
|
+
|
|
|
+ HADOOP-7320. Refactor the copy and move commands to conform to new
|
|
|
+ FsCommand class. (Daryn Sharp via todd)
|
|
|
+
|
|
|
+ HADOOP-7312. Update value of hadoop.common.configuration.version.
|
|
|
+ (Harsh J Chouraria via todd)
|
|
|
+
|
|
|
+ HADOOP-7337. Change PureJavaCrc32 annotations to public stable. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7331. Make hadoop-daemon.sh return exit code 1 if daemon processes
|
|
|
+ did not get started. (Tanping Wang via todd)
|
|
|
+
|
|
|
+ HADOOP-7316. Add public javadocs to FSDataInputStream and
|
|
|
+ FSDataOutputStream. (eli)
|
|
|
+
|
|
|
+ HADOOP-7323. Add capability to resolve compression codec based on codec
|
|
|
+ name. (Alejandro Abdelnur via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-1886. Undocumented parameters in FilesSystem. (Frank Conrad via eli)
|
|
|
+
|
|
|
+ HADOOP-7375. Add resolvePath method to FileContext. (Sanjay Radia via eli)
|
|
|
+
|
|
|
+ HADOOP-7383. HDFS needs to export protobuf library dependency in pom.
|
|
|
+ (todd via eli)
|
|
|
+
|
|
|
+ HADOOP-7374. Don't add tools.jar to the classpath when running Hadoop.
|
|
|
+ (eli)
|
|
|
+
|
|
|
+ OPTIMIZATIONS
|
|
|
+
|
|
|
+ HADOOP-7333. Performance improvement in PureJavaCrc32. (Eric Caspole
|
|
|
+ via todd)
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-7015. RawLocalFileSystem#listStatus does not deal with a directory
|
|
|
+ whose entries are changing (e.g. in a multi-thread or multi-process
|
|
|
+ environment). (Sanjay Radia via eli)
|
|
|
+
|
|
|
+ HADOOP-7045. TestDU fails on systems with local file systems with
|
|
|
+ extended attributes. (eli)
|
|
|
+
|
|
|
+ HADOOP-6939. Inconsistent lock ordering in
|
|
|
+ AbstractDelegationTokenSecretManager. (Todd Lipcon via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-7129. Fix typo in method name getProtocolSigature (todd)
|
|
|
+
|
|
|
+ HADOOP-7048. Wrong description of Block-Compressed SequenceFile Format in
|
|
|
+ SequenceFile's javadoc. (Jingguo Yao via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-7153. MapWritable violates contract of Map interface for equals()
|
|
|
+ and hashCode(). (Nicholas Telford via todd)
|
|
|
+
|
|
|
+ HADOOP-6754. DefaultCodec.createOutputStream() leaks memory.
|
|
|
+ (Aaron Kimball via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-7098. Tasktracker property not set in conf/hadoop-env.sh.
|
|
|
+ (Bernd Fondermann via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-7131. Exceptions thrown by Text methods should include the causing
|
|
|
+ exception. (Uma Maheswara Rao G via todd)
|
|
|
+
|
|
|
+ HADOOP-6912. Guard against NPE when calling UGI.isLoginKeytabBased().
|
|
|
+ (Kan Zhang via jitendra)
|
|
|
+
|
|
|
+ HADOOP-7204. remove local unused fs variable from CmdHandler
|
|
|
+ and FsShellPermissions.changePermissions (boryas)
|
|
|
+
|
|
|
+ HADOOP-7210. Chown command is not working from FSShell
|
|
|
+ (Uma Maheswara Rao G via todd)
|
|
|
+
|
|
|
+ HADOOP-7215. RPC clients must use network interface corresponding to
|
|
|
+ the host in the client's kerberos principal key. (suresh)
|
|
|
+
|
|
|
+ HADOOP-7019. Refactor build targets to enable faster cross project dev
|
|
|
+ cycles. (Luke Lu via cos)
|
|
|
+
|
|
|
+ HADOOP-7216. Add FsCommand.runAll() with deprecated annotation for the
|
|
|
+ transition of Command base class improvement. (Daryn Sharp via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7207. fs member of FSShell is not really needed (boryas)
|
|
|
+
|
|
|
+ HADOOP-7223. FileContext createFlag combinations are not clearly defined.
|
|
|
+ (suresh)
|
|
|
+
|
|
|
+ HADOOP-7231. Fix synopsis for -count. (Daryn Sharp via eli).
|
|
|
+
|
|
|
+ HADOOP-7261. Disable IPV6 for junit tests. (suresh)
|
|
|
+
|
|
|
+ HADOOP-7268. FileContext.getLocalFSFileContext() behavior needs to be fixed
|
|
|
+ w.r.t tokens. (jitendra)
|
|
|
+
|
|
|
+ HADOOP-7290. Unit test failure in TestUserGroupInformation.testGetServerSideGroups. (Trevor Robison via eli)
|
|
|
+
|
|
|
+ HADOOP-7292. Fix racy test case TestSinkQueue. (Luke Lu via todd)
|
|
|
+
|
|
|
+ HADOOP-7282. ipc.Server.getRemoteIp() may return null. (John George
|
|
|
+ via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7208. Fix implementation of equals() and hashCode() in
|
|
|
+ StandardSocketFactory. (Uma Maheswara Rao G via todd)
|
|
|
+
|
|
|
+ HADOOP-7336. TestFileContextResolveAfs will fail with default
|
|
|
+ test.build.data property. (jitendra)
|
|
|
+
|
|
|
+ HADOOP-7284 Trash and shell's rm does not work for viewfs (Sanjay Radia)
|
|
|
+
|
|
|
+ HADOOP-7341. Fix options parsing in CommandFormat (Daryn Sharp via todd)
|
|
|
+
|
|
|
+ HADOOP-7353. Cleanup FsShell and prevent masking of RTE stack traces.
|
|
|
+ (Daryn Sharp via todd)
|
|
|
+
|
|
|
+ HADOOP-7356. RPM packages broke bin/hadoop script in developer environment.
|
|
|
+ (Eric Yang via todd)
|
|
|
+
|
|
|
+Release 0.22.0 - Unreleased
|
|
|
+
|
|
|
+ INCOMPATIBLE CHANGES
|
|
|
+
|
|
|
+ HADOOP-7137. Remove hod contrib. (nigel via eli)
|
|
|
+
|
|
|
+ NEW FEATURES
|
|
|
+
|
|
|
+ HADOOP-6791. Refresh for proxy superuser config
|
|
|
+ (common part for HDFS-1096) (boryas)
|
|
|
+
|
|
|
+ HADOOP-6581. Add authenticated TokenIdentifiers to UGI so that
|
|
|
+ they can be used for authorization (Kan Zhang and Jitendra Pandey
|
|
|
+ via jghoman)
|
|
|
+
|
|
|
+ HADOOP-6584. Provide Kerberized SSL encryption for webservices.
|
|
|
+ (jghoman and Kan Zhang via jghoman)
|
|
|
+
|
|
|
+ HADOOP-6853. Common component of HDFS-1045. (jghoman)
|
|
|
+
|
|
|
+ HADOOP-6859 - Introduce additional statistics to FileSystem to track
|
|
|
+ file system operations (suresh)
|
|
|
+
|
|
|
+ HADOOP-6870. Add a new API getFiles to FileSystem and FileContext that
|
|
|
+ lists all files under the input path or the subtree rooted at the
|
|
|
+ input path if recursive is true. Block locations are returned together
|
|
|
+ with each file's status. (hairong)
|
|
|
+
|
|
|
+ HADOOP-6888. Add a new FileSystem API closeAllForUGI(..) for closing all
|
|
|
+ file systems associated with a particular UGI. (Devaraj Das and Kan Zhang
|
|
|
+ via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6892. Common component of HDFS-1150 (Verify datanodes' identities
|
|
|
+ to clients in secure clusters) (jghoman)
|
|
|
+
|
|
|
+ HADOOP-6889. Make RPC to have an option to timeout. (hairong)
|
|
|
+
|
|
|
+ HADOOP-6996. Allow CodecFactory to return a codec object given a codec'
|
|
|
+ class name. (hairong)
|
|
|
+
|
|
|
+ HADOOP-7013. Add boolean field isCorrupt to BlockLocation.
|
|
|
+ (Patrick Kling via hairong)
|
|
|
+
|
|
|
+ HADOOP-6978. Adds support for NativeIO using JNI.
|
|
|
+ (Todd Lipcon, Devaraj Das & Owen O'Malley via ddas)
|
|
|
+
|
|
|
+ HADOOP-7134. configure files that are generated as part of the released
|
|
|
+ tarball need to have executable bit set. (Roman Shaposhnik via cos)
|
|
|
+
|
|
|
+ IMPROVEMENTS
|
|
|
+
|
|
|
+ HADOOP-6644. util.Shell getGROUPS_FOR_USER_COMMAND method name
|
|
|
+ - should use common naming convention (boryas)
|
|
|
+
|
|
|
+ HADOOP-6778. add isRunning() method to
|
|
|
+ AbstractDelegationTokenSecretManager (for HDFS-1044) (boryas)
|
|
|
+
|
|
|
+ HADOOP-6633. normalize property names for JT/NN kerberos principal
|
|
|
+ names in configuration (boryas)
|
|
|
+
|
|
|
+ HADOOP-6627. "Bad Connection to FS" message in FSShell should print
|
|
|
+ message from the exception (boryas)
|
|
|
+
|
|
|
+ HADOOP-6600. mechanism for authorization check for inter-server
|
|
|
+ protocols. (boryas)
|
|
|
+
|
|
|
+ HADOOP-6623. Add StringUtils.split for non-escaped single-character
|
|
|
+ separator. (Todd Lipcon via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6761. The Trash Emptier has the ability to run more frequently.
|
|
|
+ (Dmytro Molkov via dhruba)
|
|
|
+
|
|
|
+ HADOOP-6714. Resolve compressed files using CodecFactory in FsShell::text.
|
|
|
+ (Patrick Angeles via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6661. User document for UserGroupInformation.doAs.
|
|
|
+ (Jitendra Pandey via jghoman)
|
|
|
+
|
|
|
+ HADOOP-6674. Makes use of the SASL authentication options in the
|
|
|
+ SASL RPC. (Jitendra Pandey via ddas)
|
|
|
+
|
|
|
+ HADOOP-6526. Need mapping from long principal names to local OS
|
|
|
+ user names. (boryas)
|
|
|
+
|
|
|
+ HADOOP-6814. Adds an API in UserGroupInformation to get the real
|
|
|
+ authentication method of a passed UGI. (Jitendra Pandey via ddas)
|
|
|
+
|
|
|
+ HADOOP-6756. Documentation for common configuration keys.
|
|
|
+ (Erik Steffl via shv)
|
|
|
+
|
|
|
+ HADOOP-6835. Add support for concatenated gzip input. (Greg Roelofs via
|
|
|
+ cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6845. Renames the TokenStorage class to Credentials.
|
|
|
+ (Jitendra Pandey via ddas)
|
|
|
+
|
|
|
+ HADOOP-6826. FileStatus needs unit tests. (Rodrigo Schmidt via Eli
|
|
|
+ Collins)
|
|
|
+
|
|
|
+ HADOOP-6905. add buildDTServiceName method to SecurityUtil
|
|
|
+ (as part of MAPREDUCE-1718) (boryas)
|
|
|
+
|
|
|
+ HADOOP-6632. Adds support for using different keytabs for different
|
|
|
+ servers in a Hadoop cluster. In the earier implementation, all servers
|
|
|
+ of a certain type (like TaskTracker), would have the same keytab and the
|
|
|
+ same principal. Now the principal name is a pattern that has _HOST in it.
|
|
|
+ (Kan Zhang & Jitendra Pandey via ddas)
|
|
|
+
|
|
|
+ HADOOP-6861. Adds new non-static methods in Credentials to read and
|
|
|
+ write token storage file. (Jitendra Pandey & Owen O'Malley via ddas)
|
|
|
+
|
|
|
+ HADOOP-6877. Common part of HDFS-1178 (NameNode servlets should communicate
|
|
|
+ with NameNode directrly). (Kan Zhang via jghoman)
|
|
|
+
|
|
|
+ HADOOP-6475. Adding some javadoc to Server.RpcMetrics, UGI.
|
|
|
+ (Jitendra Pandey and borya via jghoman)
|
|
|
+
|
|
|
+ HADOOP-6656. Adds a thread in the UserGroupInformation to renew TGTs
|
|
|
+ periodically. (Owen O'Malley and ddas via ddas)
|
|
|
+
|
|
|
+ HADOOP-6890. Improve listFiles API introduced by HADOOP-6870. (hairong)
|
|
|
+
|
|
|
+ HADOOP-6862. Adds api to add/remove user and group to AccessControlList
|
|
|
+ (amareshwari)
|
|
|
+
|
|
|
+ HADOOP-6911. doc update for DelegationTokenFetcher (boryas)
|
|
|
+
|
|
|
+ HADOOP-6900. Make the iterator returned by FileSystem#listLocatedStatus to
|
|
|
+ throw IOException rather than RuntimeException when there is an IO error
|
|
|
+ fetching the next file. (hairong)
|
|
|
+
|
|
|
+ HADOOP-6905. Better logging messages when a delegation token is invalid.
|
|
|
+ (Kan Zhang via jghoman)
|
|
|
+
|
|
|
+ HADOOP-6693. Add metrics to track kerberol login activity. (suresh)
|
|
|
+
|
|
|
+ HADOOP-6803. Add native gzip read/write coverage to TestCodec.
|
|
|
+ (Eli Collins via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6950. Suggest that HADOOP_CLASSPATH should be preserved in
|
|
|
+ hadoop-env.sh.template. (Philip Zeyliger via Eli Collins)
|
|
|
+
|
|
|
+ HADOOP-6922. Make AccessControlList a writable and update documentation
|
|
|
+ for Job ACLs. (Ravi Gummadi via vinodkv)
|
|
|
+
|
|
|
+ HADOOP-6965. Introduces checks for whether the original tgt is valid
|
|
|
+ in the reloginFromKeytab method.
|
|
|
+
|
|
|
+ HADOOP-6856. Simplify constructors for SequenceFile, and MapFile. (omalley)
|
|
|
+
|
|
|
+ HADOOP-6987. Use JUnit Rule to optionally fail test cases that run more
|
|
|
+ than 10 seconds (jghoman)
|
|
|
+
|
|
|
+ HADOOP-7005. Update test-patch.sh to remove callback to Hudson. (nigel)
|
|
|
+
|
|
|
+ HADOOP-6985. Suggest that HADOOP_OPTS be preserved in
|
|
|
+ hadoop-env.sh.template. (Ramkumar Vadali via cutting)
|
|
|
+
|
|
|
+ HADOOP-7007. Update the hudson-test-patch ant target to work with the
|
|
|
+ latest test-patch.sh script (gkesavan)
|
|
|
+
|
|
|
+ HADOOP-7010. Typo in FileSystem.java. (Jingguo Yao via eli)
|
|
|
+
|
|
|
+ HADOOP-7009. MD5Hash provides a public factory method that creates an
|
|
|
+ instance of thread local MessageDigest. (hairong)
|
|
|
+
|
|
|
+ HADOOP-7008. Enable test-patch.sh to have a configured number of
|
|
|
+ acceptable findbugs and javadoc warnings. (nigel and gkesavan)
|
|
|
+
|
|
|
+ HADOOP-6818. Provides a JNI implementation of group resolution. (ddas)
|
|
|
+
|
|
|
+ HADOOP-6943. The GroupMappingServiceProvider interface should be public.
|
|
|
+ (Aaron T. Myers via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-4675. Current Ganglia metrics implementation is incompatible with
|
|
|
+ Ganglia 3.1. (Brian Bockelman via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6977. Herriot daemon clients should vend statistics (cos)
|
|
|
+
|
|
|
+ HADOOP-7024. Create a test method for adding file systems during tests.
|
|
|
+ (Kan Zhang via jghoman)
|
|
|
+
|
|
|
+ HADOOP-6903. Make AbstractFSileSystem methods and some FileContext methods
|
|
|
+ to be public. (Sanjay Radia)
|
|
|
+
|
|
|
+ HADOOP-7034. Add TestPath tests to cover dot, dot dot, and slash
|
|
|
+ normalization. (eli)
|
|
|
+
|
|
|
+ HADOOP-7032. Assert type constraints in the FileStatus constructor. (eli)
|
|
|
+
|
|
|
+ HADOOP-6562. FileContextSymlinkBaseTest should use FileContextTestHelper.
|
|
|
+ (eli)
|
|
|
+
|
|
|
+ HADOOP-7028. ant eclipse does not include requisite ant.jar in the
|
|
|
+ classpath. (Patrick Angeles via eli)
|
|
|
+
|
|
|
+ HADOOP-6298. Add copyBytes to Text and BytesWritable. (omalley)
|
|
|
+
|
|
|
+ HADOOP-6578. Configuration should trim whitespace around a lot of value
|
|
|
+ types. (Michele Catasta via eli)
|
|
|
+
|
|
|
+ HADOOP-6811. Remove EC2 bash scripts. They are replaced by Apache Whirr
|
|
|
+ (incubating, http://incubator.apache.org/whirr). (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-7102. Remove "fs.ramfs.impl" field from core-deafult.xml (shv)
|
|
|
+
|
|
|
+ HADOOP-7104. Remove unnecessary DNS reverse lookups from RPC layer
|
|
|
+ (Kan Zhang via todd)
|
|
|
+
|
|
|
+ HADOOP-6056. Use java.net.preferIPv4Stack to force IPv4.
|
|
|
+ (Michele Catasta via shv)
|
|
|
+
|
|
|
+ HADOOP-7110. Implement chmod with JNI. (todd)
|
|
|
+
|
|
|
+ HADOOP-6812. Change documentation for correct placement of configuration
|
|
|
+ variables: mapreduce.reduce.input.buffer.percent,
|
|
|
+ mapreduce.task.io.sort.factor, mapreduce.task.io.sort.mb
|
|
|
+ (Chris Douglas via shv)
|
|
|
+
|
|
|
+ HADOOP-6436. Remove auto-generated native build files. (rvs via eli)
|
|
|
+
|
|
|
+ HADOOP-6970. SecurityAuth.audit should be generated under /build. (boryas)
|
|
|
+
|
|
|
+ HADOOP-7154. Should set MALLOC_ARENA_MAX in hadoop-env.sh (todd)
|
|
|
+
|
|
|
+ HADOOP-7187. Fix socket leak in GangliaContext. (Uma Maheswara Rao G
|
|
|
+ via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7241. fix typo of command 'hadoop fs -help tail'.
|
|
|
+ (Wei Yongjun via eli)
|
|
|
+
|
|
|
+ HADOOP-7244. Documentation change for updated configuration keys.
|
|
|
+ (tomwhite via eli)
|
|
|
+
|
|
|
+ HADOOP-7189. Add ability to enable 'debug' property in JAAS configuration.
|
|
|
+ (Ted Yu via todd)
|
|
|
+
|
|
|
+ HADOOP-7192. Update fs -stat docs to reflect the format features. (Harsh
|
|
|
+ J Chouraria via todd)
|
|
|
+
|
|
|
+ HADOOP-7355 Add audience and stability annotations to HttpServer class
|
|
|
+ (stack)
|
|
|
+
|
|
|
+ HADOOP-7346. Send back nicer error message to clients using outdated IPC
|
|
|
+ version. (todd)
|
|
|
+
|
|
|
+ HADOOP-7335. Force entropy to come from non-true random for tests.
|
|
|
+ (todd via eli)
|
|
|
+
|
|
|
+ HADOOP-7325. The hadoop command should not accept class names starting with
|
|
|
+ a hyphen. (Brock Noland via todd)
|
|
|
+
|
|
|
+ OPTIMIZATIONS
|
|
|
+
|
|
|
+ HADOOP-6884. Add LOG.isDebugEnabled() guard for each LOG.debug(..).
|
|
|
+ (Erik Steffl via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6683. ZlibCompressor does not fully utilize the buffer.
|
|
|
+ (Kang Xiao via eli)
|
|
|
+
|
|
|
+ HADOOP-6949. Reduce RPC packet size of primitive arrays using
|
|
|
+ ArrayPrimitiveWritable instead of ObjectWritable. (Matt Foley via suresh)
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-6638. try to relogin in a case of failed RPC connection (expired
|
|
|
+ tgt) only in case the subject is loginUser or proxyUgi.realUser. (boryas)
|
|
|
+
|
|
|
+ HADOOP-6781. security audit log shouldn't have exception in it. (boryas)
|
|
|
+
|
|
|
+ HADOOP-6612. Protocols RefreshUserToGroupMappingsProtocol and
|
|
|
+ RefreshAuthorizationPolicyProtocol will fail with security enabled (boryas)
|
|
|
+
|
|
|
+ HADOOP-6764. Remove verbose logging from the Groups class. (Boris Shkolnik)
|
|
|
+
|
|
|
+ HADOOP-6730. Bug in FileContext#copy and provide base class for
|
|
|
+ FileContext tests. (Ravi Phulari via jghoman)
|
|
|
+
|
|
|
+ HADOOP-6669. Respect compression configuration when creating DefaultCodec
|
|
|
+ instances. (Koji Noguchi via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6747. TestNetUtils fails on Mac OS X. (Todd Lipcon via jghoman)
|
|
|
+
|
|
|
+ HADOOP-6787. Factor out glob pattern code from FileContext and
|
|
|
+ Filesystem. Also fix bugs identified in HADOOP-6618 and make the
|
|
|
+ glob pattern code less restrictive and more POSIX standard
|
|
|
+ compliant. (Luke Lu via eli)
|
|
|
+
|
|
|
+ HADOOP-6649. login object in UGI should be inside the subject (jnp via
|
|
|
+ boryas)
|
|
|
+
|
|
|
+ HADOOP-6687. user object in the subject in UGI should be reused in case
|
|
|
+ of a relogin. (jnp via boryas)
|
|
|
+
|
|
|
+ HADOOP-6603. Provide workaround for issue with Kerberos not resolving
|
|
|
+ cross-realm principal (Kan Zhang and Jitendra Pandey via jghoman)
|
|
|
+
|
|
|
+ HADOOP-6620. NPE if renewer is passed as null in getDelegationToken.
|
|
|
+ (Jitendra Pandey via jghoman)
|
|
|
+
|
|
|
+ HADOOP-6613. Moves the RPC version check ahead of the AuthMethod check.
|
|
|
+ (Kan Zhang via ddas)
|
|
|
+
|
|
|
+ HADOOP-6682. NetUtils:normalizeHostName does not process hostnames starting
|
|
|
+ with [a-f] correctly. (jghoman)
|
|
|
+
|
|
|
+ HADOOP-6652. Removes the unnecessary cache from
|
|
|
+ ShellBasedUnixGroupsMapping. (ddas)
|
|
|
+
|
|
|
+ HADOOP-6815. refreshSuperUserGroupsConfiguration should use server side
|
|
|
+ configuration for the refresh (boryas)
|
|
|
+
|
|
|
+ HADOOP-6648. Adds a check for null tokens in Credentials.addToken api.
|
|
|
+ (ddas)
|
|
|
+
|
|
|
+ HADOOP-6647. balancer fails with "is not authorized for protocol
|
|
|
+ interface NamenodeProtocol" in secure environment (boryas)
|
|
|
+
|
|
|
+ HADOOP-6834. TFile.append compares initial key against null lastKey
|
|
|
+ (hong tang via mahadev)
|
|
|
+
|
|
|
+ HADOOP-6670. Use the UserGroupInformation's Subject as the criteria for
|
|
|
+ equals and hashCode. (Owen O'Malley and Kan Zhang via ddas)
|
|
|
+
|
|
|
+ HADOOP-6536. Fixes FileUtil.fullyDelete() not to delete the contents of
|
|
|
+ the sym-linked directory. (Ravi Gummadi via amareshwari)
|
|
|
+
|
|
|
+ HADOOP-6873. using delegation token over hftp for long
|
|
|
+ running clients (boryas)
|
|
|
+
|
|
|
+ HADOOP-6706. Improves the sasl failure handling due to expired tickets,
|
|
|
+ and other server detected failures. (Jitendra Pandey and ddas via ddas)
|
|
|
+
|
|
|
+ HADOOP-6715. Fixes AccessControlList.toString() to return a descriptive
|
|
|
+ String representation of the ACL. (Ravi Gummadi via amareshwari)
|
|
|
+
|
|
|
+ HADOOP-6885. Fix java doc warnings in Groups and
|
|
|
+ RefreshUserMappingsProtocol. (Eli Collins via jghoman)
|
|
|
+
|
|
|
+ HADOOP-6482. GenericOptionsParser constructor that takes Options and
|
|
|
+ String[] ignores options. (Eli Collins via jghoman)
|
|
|
+
|
|
|
+ HADOOP-6906. FileContext copy() utility doesn't work with recursive
|
|
|
+ copying of directories. (vinod k v via mahadev)
|
|
|
+
|
|
|
+ HADOOP-6453. Hadoop wrapper script shouldn't ignore an existing
|
|
|
+ JAVA_LIBRARY_PATH. (Chad Metcalf via jghoman)
|
|
|
+
|
|
|
+ HADOOP-6932. Namenode start (init) fails because of invalid kerberos
|
|
|
+ key, even when security set to "simple" (boryas)
|
|
|
+
|
|
|
+ HADOOP-6913. Circular initialization between UserGroupInformation and
|
|
|
+ KerberosName (Kan Zhang via boryas)
|
|
|
+
|
|
|
+ HADOOP-6907. Rpc client doesn't use the per-connection conf to figure
|
|
|
+ out server's Kerberos principal (Kan Zhang via hairong)
|
|
|
+
|
|
|
+ HADOOP-6938. ConnectionId.getRemotePrincipal() should check if security
|
|
|
+ is enabled. (Kan Zhang via hairong)
|
|
|
+
|
|
|
+ HADOOP-6930. AvroRpcEngine doesn't work with generated Avro code.
|
|
|
+ (sharad)
|
|
|
+
|
|
|
+ HADOOP-6940. RawLocalFileSystem's markSupported method misnamed
|
|
|
+ markSupport. (Tom White via eli).
|
|
|
+
|
|
|
+ HADOOP-6951. Distinct minicluster services (e.g. NN and JT) overwrite each
|
|
|
+ other's service policies. (Aaron T. Myers via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6879. Provide SSH based (Jsch) remote execution API for system
|
|
|
+ tests (cos)
|
|
|
+
|
|
|
+ HADOOP-6989. Correct the parameter for SetFile to set the value type
|
|
|
+ for SetFile to be NullWritable instead of the key. (cdouglas via omalley)
|
|
|
+
|
|
|
+ HADOOP-6984. Combine the compress kind and the codec in the same option
|
|
|
+ for SequenceFiles. (cdouglas via omalley)
|
|
|
+
|
|
|
+ HADOOP-6933. TestListFiles is flaky. (Todd Lipcon via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6947. Kerberos relogin should set refreshKrb5Config to true.
|
|
|
+ (Todd Lipcon via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-7006. Fix 'fs -getmerge' command to not be a no-op.
|
|
|
+ (Chris Nauroth via cutting)
|
|
|
+
|
|
|
+ HADOOP-6663. BlockDecompressorStream get EOF exception when decompressing
|
|
|
+ the file compressed from empty file. (Kang Xiao via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6991. Fix SequenceFile::Reader to honor file lengths and call
|
|
|
+ openFile (cdouglas via omalley)
|
|
|
+
|
|
|
+ HADOOP-7011. Fix KerberosName.main() to not throw an NPE.
|
|
|
+ (Aaron T. Myers via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6975. Integer overflow in S3InputStream for blocks > 2GB.
|
|
|
+ (Patrick Kling via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6758. MapFile.fix does not allow index interval definition.
|
|
|
+ (Gianmarco De Francisci Morales via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6926. SocketInputStream incorrectly implements read().
|
|
|
+ (Todd Lipcon via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6899 RawLocalFileSystem#setWorkingDir() does not work for relative names
|
|
|
+ (Sanjay Radia)
|
|
|
+
|
|
|
+ HADOOP-6496. HttpServer sends wrong content-type for CSS files
|
|
|
+ (and others). (Todd Lipcon via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-7057. IOUtils.readFully and IOUtils.skipFully have typo in
|
|
|
+ exception creation's message. (cos)
|
|
|
+
|
|
|
+ HADOOP-7038. saveVersion script includes an additional \r while running
|
|
|
+ whoami under windows. (Wang Xu via cos)
|
|
|
+
|
|
|
+ HADOOP-7082. Configuration.writeXML should not hold lock while outputting
|
|
|
+ (todd)
|
|
|
+
|
|
|
+ HADOOP-7070. JAAS configuration should delegate unknown application names
|
|
|
+ to pre-existing configuration. (todd)
|
|
|
+
|
|
|
+ HADOOP-7087. SequenceFile.createWriter ignores FileSystem parameter (todd)
|
|
|
+
|
|
|
+ HADOOP-7091. reloginFromKeytab() should happen even if TGT can't be found.
|
|
|
+ (Kan Zhang via jghoman)
|
|
|
+
|
|
|
+ HADOOP-7100. Fix build to not refer to contrib/ec2 removed by HADOOP-6811
|
|
|
+ (todd)
|
|
|
+
|
|
|
+ HADOOP-7097. JAVA_LIBRARY_PATH missing base directory. (Noah Watkins via
|
|
|
+ todd)
|
|
|
+
|
|
|
+ HADOOP-7093. Servlets should default to text/plain (todd)
|
|
|
+
|
|
|
+ HADOOP-7101. UserGroupInformation.getCurrentUser() fails when called from
|
|
|
+ non-Hadoop JAAS context. (todd)
|
|
|
+
|
|
|
+ HADOOP-7089. Fix link resolution logic in hadoop-config.sh. (eli)
|
|
|
+
|
|
|
+ HADOOP-7046. Fix Findbugs warning in Configuration. (Po Cheung via shv)
|
|
|
+
|
|
|
+ HADOOP-7118. Fix NPE in Configuration.writeXml (todd)
|
|
|
+
|
|
|
+ HADOOP-7122. Fix thread leak when shell commands time out. (todd)
|
|
|
+
|
|
|
+ HADOOP-7126. Fix file permission setting for RawLocalFileSystem on Windows.
|
|
|
+ (Po Cheung via shv)
|
|
|
+
|
|
|
+ HADOOP-6642. Fix javac, javadoc, findbugs warnings related to security work.
|
|
|
+ (Chris Douglas, Po Cheung via shv)
|
|
|
+
|
|
|
+ HADOOP-7140. IPC Reader threads do not stop when server stops (todd)
|
|
|
+
|
|
|
+ HADOOP-7094. hadoop.css got lost during project split (cos)
|
|
|
+
|
|
|
+ HADOOP-7145. Configuration.getLocalPath should trim whitespace from
|
|
|
+ the provided directories. (todd)
|
|
|
+
|
|
|
+ HADOOP-7156. Workaround for unsafe implementations of getpwuid_r (todd)
|
|
|
+
|
|
|
+ HADOOP-6898. FileSystem.copyToLocal creates files with 777 permissions.
|
|
|
+ (Aaron T. Myers via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-7229. Do not default to an absolute path for kinit in Kerberos
|
|
|
+ auto-renewal thread. (Aaron T. Myers via todd)
|
|
|
+
|
|
|
+ HADOOP-7172. SecureIO should not check owner on non-secure
|
|
|
+ clusters that have no native support. (todd via eli)
|
|
|
+
|
|
|
+ HADOOP-7184. Remove deprecated config local.cache.size from
|
|
|
+ core-default.xml (todd)
|
|
|
+
|
|
|
+ HADOOP-7245. FsConfig should use constants in CommonConfigurationKeys.
|
|
|
+ (tomwhite via eli)
|
|
|
+
|
|
|
+ HADOOP-7068. Ivy resolve force mode should be turned off by default.
|
|
|
+ (Luke Lu via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-7296. The FsPermission(FsPermission) constructor does not use the
|
|
|
+ sticky bit. (Siddharth Seth via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-7300. Configuration methods that return collections are inconsistent
|
|
|
+ about mutability. (todd)
|
|
|
+
|
|
|
+ HADOOP-7305. Eclipse project classpath should include tools.jar from JDK.
|
|
|
+ (Niels Basjes via todd)
|
|
|
+
|
|
|
+ HADOOP-7318. MD5Hash factory should reset the digester it returns.
|
|
|
+ (todd via eli)
|
|
|
+
|
|
|
+ HADOOP-7287. Configuration deprecation mechanism doesn't work properly for
|
|
|
+ GenericOptionsParser and Tools. (Aaron T. Myers via todd)
|
|
|
+
|
|
|
+ HADOOP-7146. RPC server leaks file descriptors (todd)
|
|
|
+
|
|
|
+ HADOOP-7276. Hadoop native builds fail on ARM due to -m32 (Trevor Robinson
|
|
|
+ via eli)
|
|
|
+
|
|
|
+ HADOOP-7121. Exceptions while serializing IPC call responses are not
|
|
|
+ handled well. (todd)
|
|
|
+
|
|
|
+ HADOOP-7351 Regression: HttpServer#getWebAppsPath used to be protected
|
|
|
+ so subclasses could supply alternate webapps path but it was made private
|
|
|
+ by HADOOP-6461 (Stack)
|
|
|
+
|
|
|
+ HADOOP-7349. HADOOP-7121 accidentally disabled some tests in TestIPC.
|
|
|
+ (todd)
|
|
|
+
|
|
|
+Release 0.21.1 - Unreleased
|
|
|
+
|
|
|
+ IMPROVEMENTS
|
|
|
+
|
|
|
+ HADOOP-6934. Test for ByteWritable comparator.
|
|
|
+ (Johannes Zillmann via Eli Collins)
|
|
|
+
|
|
|
+ HADOOP-6786. test-patch needs to verify Herriot integrity (cos)
|
|
|
+
|
|
|
+ HADOOP-7177. CodecPool should report which compressor it is using.
|
|
|
+ (Allen Wittenauer via eli)
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-6925. BZip2Codec incorrectly implements read().
|
|
|
+ (Todd Lipcon via Eli Collins)
|
|
|
+
|
|
|
+ HADOOP-6833. IPC leaks call parameters when exceptions thrown.
|
|
|
+ (Todd Lipcon via Eli Collins)
|
|
|
+
|
|
|
+ HADOOP-6971. Clover build doesn't generate per-test coverage (cos)
|
|
|
+
|
|
|
+ HADOOP-6993. Broken link on cluster setup page of docs. (eli)
|
|
|
+
|
|
|
+ HADOOP-6944. [Herriot] Implement a functionality for getting proxy users
|
|
|
+ definitions like groups and hosts. (Vinay Thota via cos)
|
|
|
+
|
|
|
+ HADOOP-6954. Sources JARs are not correctly published to the Maven
|
|
|
+ repository. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-7052. misspelling of threshold in conf/log4j.properties.
|
|
|
+ (Jingguo Yao via eli)
|
|
|
+
|
|
|
+ HADOOP-7053. wrong FSNamesystem Audit logging setting in
|
|
|
+ conf/log4j.properties. (Jingguo Yao via eli)
|
|
|
+
|
|
|
+ HADOOP-7120. Fix a syntax error in test-patch.sh. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7162. Rmove a duplicated call FileSystem.listStatus(..) in FsShell.
|
|
|
+ (Alexey Diomin via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7117. Remove fs.checkpoint.* from core-default.xml and replace
|
|
|
+ fs.checkpoint.* with dfs.namenode.checkpoint.* in documentations.
|
|
|
+ (Harsh J Chouraria via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7193. Correct the "fs -touchz" command help message.
|
|
|
+ (Uma Maheswara Rao G via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7174. Null is displayed in the "fs -copyToLocal" command.
|
|
|
+ (Uma Maheswara Rao G via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7194. Fix resource leak in IOUtils.copyBytes(..).
|
|
|
+ (Devaraj K via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-7183. WritableComparator.get should not cache comparator objects.
|
|
|
+ (tomwhite via eli)
|
|
|
+
|
|
|
+Release 0.21.0 - 2010-08-13
|
|
|
+
|
|
|
+ INCOMPATIBLE CHANGES
|
|
|
+
|
|
|
+ HADOOP-4895. Remove deprecated methods DFSClient.getHints(..) and
|
|
|
+ DFSClient.isDirectory(..). (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4941. Remove deprecated FileSystem methods: getBlockSize(Path f),
|
|
|
+ getLength(Path f) and getReplication(Path src). (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4648. Remove obsolete, deprecated InMemoryFileSystem and
|
|
|
+ ChecksumDistributedFileSystem. (cdouglas via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4940. Remove a deprecated method FileSystem.delete(Path f). (Enis
|
|
|
+ Soztutar via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4010. Change semantics for LineRecordReader to read an additional
|
|
|
+ line per split- rather than moving back one character in the stream- to
|
|
|
+ work with splittable compression codecs. (Abdul Qadeer via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5094. Show hostname and separate live/dead datanodes in DFSAdmin
|
|
|
+ report. (Jakob Homan via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4942. Remove deprecated FileSystem methods getName() and
|
|
|
+ getNamed(String name, Configuration conf). (Jakob Homan via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5486. Removes the CLASSPATH string from the command line and instead
|
|
|
+ exports it in the environment. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2827. Remove deprecated NetUtils::getServerAddress. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5681. Change examples RandomWriter and RandomTextWriter to
|
|
|
+ use new mapreduce API. (Amareshwari Sriramadasu via sharad)
|
|
|
+
|
|
|
+ HADOOP-5680. Change org.apache.hadoop.examples.SleepJob to use new
|
|
|
+ mapreduce api. (Amareshwari Sriramadasu via sharad)
|
|
|
+
|
|
|
+ HADOOP-5699. Change org.apache.hadoop.examples.PiEstimator to use
|
|
|
+ new mapreduce api. (Amareshwari Sriramadasu via sharad)
|
|
|
+
|
|
|
+ HADOOP-5720. Introduces new task types - JOB_SETUP, JOB_CLEANUP
|
|
|
+ and TASK_CLEANUP. Removes the isMap methods from TaskID/TaskAttemptID
|
|
|
+ classes. (ddas)
|
|
|
+
|
|
|
+ HADOOP-5668. Change TotalOrderPartitioner to use new API. (Amareshwari
|
|
|
+ Sriramadasu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5738. Split "waiting_tasks" JobTracker metric into waiting maps and
|
|
|
+ waiting reduces. (Sreekanth Ramakrishnan via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5679. Resolve findbugs warnings in core/streaming/pipes/examples.
|
|
|
+ (Jothi Padmanabhan via sharad)
|
|
|
+
|
|
|
+ HADOOP-4359. Support for data access authorization checking on Datanodes.
|
|
|
+ (Kan Zhang via rangadi)
|
|
|
+
|
|
|
+ HADOOP-5690. Change org.apache.hadoop.examples.DBCountPageView to use
|
|
|
+ new mapreduce api. (Amareshwari Sriramadasu via sharad)
|
|
|
+
|
|
|
+ HADOOP-5694. Change org.apache.hadoop.examples.dancing to use new
|
|
|
+ mapreduce api. (Amareshwari Sriramadasu via sharad)
|
|
|
+
|
|
|
+ HADOOP-5696. Change org.apache.hadoop.examples.Sort to use new
|
|
|
+ mapreduce api. (Amareshwari Sriramadasu via sharad)
|
|
|
+
|
|
|
+ HADOOP-5698. Change org.apache.hadoop.examples.MultiFileWordCount to
|
|
|
+ use new mapreduce api. (Amareshwari Sriramadasu via sharad)
|
|
|
+
|
|
|
+ HADOOP-5913. Provide ability to an administrator to stop and start
|
|
|
+ job queues. (Rahul Kumar Singh and Hemanth Yamijala via yhemanth)
|
|
|
+
|
|
|
+ MAPREDUCE-711. Removed Distributed Cache from Common, to move it
|
|
|
+ under Map/Reduce. (Vinod Kumar Vavilapalli via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-6201. Change FileSystem::listStatus contract to throw
|
|
|
+ FileNotFoundException if the directory does not exist, rather than letting
|
|
|
+ this be implementation-specific. (Jakob Homan via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6230. Moved process tree and memory calculator related classes
|
|
|
+ from Common to Map/Reduce. (Vinod Kumar Vavilapalli via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-6203. FsShell rm/rmr error message indicates exceeding Trash quota
|
|
|
+ and suggests using -skpTrash, when moving to trash fails.
|
|
|
+ (Boris Shkolnik via suresh)
|
|
|
+
|
|
|
+ HADOOP-6303. Eclipse .classpath template has outdated jar files and is
|
|
|
+ missing some new ones. (cos)
|
|
|
+
|
|
|
+ HADOOP-6396. Fix uninformative exception message when unable to parse
|
|
|
+ umask. (jghoman)
|
|
|
+
|
|
|
+ HADOOP-6299. Reimplement the UserGroupInformation to use the OS
|
|
|
+ specific and Kerberos JAAS login. (omalley)
|
|
|
+
|
|
|
+ HADOOP-6686. Remove redundant exception class name from the exception
|
|
|
+ message for the exceptions thrown at RPC client. (suresh)
|
|
|
+
|
|
|
+ HADOOP-6701. Fix incorrect exit codes returned from chmod, chown and chgrp
|
|
|
+ commands from FsShell. (Ravi Phulari via suresh)
|
|
|
+
|
|
|
+ NEW FEATURES
|
|
|
+
|
|
|
+ HADOOP-6332. Large-scale Automated Test Framework. (sharad, Sreekanth
|
|
|
+ Ramakrishnan, at all via cos)
|
|
|
+
|
|
|
+ HADOOP-4268. Change fsck to use ClientProtocol methods so that the
|
|
|
+ corresponding permission requirement for running the ClientProtocol
|
|
|
+ methods will be enforced. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-3953. Implement sticky bit for directories in HDFS. (Jakob Homan
|
|
|
+ via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4368. Implement df in FsShell to show the status of a FileSystem.
|
|
|
+ (Craig Macdonald via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-3741. Add a web ui to the SecondaryNameNode for showing its status.
|
|
|
+ (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5018. Add pipelined writers to Chukwa. (Ari Rabkin via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5052. Add an example computing exact digits of pi using the
|
|
|
+ Bailey-Borwein-Plouffe algorithm. (Tsz Wo (Nicholas), SZE via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4927. Adds a generic wrapper around outputformat to allow creation of
|
|
|
+ output on demand (Jothi Padmanabhan via ddas)
|
|
|
+
|
|
|
+ HADOOP-5144. Add a new DFSAdmin command for changing the setting of restore
|
|
|
+ failed storage replicas in namenode. (Boris Shkolnik via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5258. Add a new DFSAdmin command to print a tree of the rack and
|
|
|
+ datanode topology as seen by the namenode. (Jakob Homan via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4756. A command line tool to access JMX properties on NameNode
|
|
|
+ and DataNode. (Boris Shkolnik via rangadi)
|
|
|
+
|
|
|
+ HADOOP-4539. Introduce backup node and checkpoint node. (shv)
|
|
|
+
|
|
|
+ HADOOP-5363. Add support for proxying connections to multiple clusters with
|
|
|
+ different versions to hdfsproxy. (Zhiyong Zhang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5528. Add a configurable hash partitioner operating on ranges of
|
|
|
+ BinaryComparable keys. (Klaas Bosteels via shv)
|
|
|
+
|
|
|
+ HADOOP-5257. HDFS servers may start and stop external components through
|
|
|
+ a plugin interface. (Carlos Valiente via dhruba)
|
|
|
+
|
|
|
+ HADOOP-5450. Add application-specific data types to streaming's typed bytes
|
|
|
+ interface. (Klaas Bosteels via omalley)
|
|
|
+
|
|
|
+ HADOOP-5518. Add contrib/mrunit, a MapReduce unit test framework.
|
|
|
+ (Aaron Kimball via cutting)
|
|
|
+
|
|
|
+ HADOOP-5469. Add /metrics servlet to daemons, providing metrics
|
|
|
+ over HTTP as either text or JSON. (Philip Zeyliger via cutting)
|
|
|
+
|
|
|
+ HADOOP-5467. Introduce offline fsimage image viewer. (Jakob Homan via shv)
|
|
|
+
|
|
|
+ HADOOP-5752. Add a new hdfs image processor, Delimited, to oiv. (Jakob
|
|
|
+ Homan via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5266. Adds the capability to do mark/reset of the reduce values
|
|
|
+ iterator in the Context object API. (Jothi Padmanabhan via ddas)
|
|
|
+
|
|
|
+ HADOOP-5745. Allow setting the default value of maxRunningJobs for all
|
|
|
+ pools. (dhruba via matei)
|
|
|
+
|
|
|
+ HADOOP-5643. Adds a way to decommission TaskTrackers while the JobTracker
|
|
|
+ is running. (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-4829. Allow FileSystem shutdown hook to be disabled.
|
|
|
+ (Todd Lipcon via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-5815. Sqoop: A database import tool for Hadoop.
|
|
|
+ (Aaron Kimball via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-4861. Add disk usage with human-readable size (-duh).
|
|
|
+ (Todd Lipcon via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-5844. Use mysqldump when connecting to local mysql instance in Sqoop.
|
|
|
+ (Aaron Kimball via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-5976. Add a new command, classpath, to the hadoop script. (Owen
|
|
|
+ O'Malley and Gary Murry via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6120. Add support for Avro specific and reflect data.
|
|
|
+ (sharad via cutting)
|
|
|
+
|
|
|
+ HADOOP-6226. Moves BoundedByteArrayOutputStream from the tfile package to
|
|
|
+ the io package and makes it available to other users (MAPREDUCE-318).
|
|
|
+ (Jothi Padmanabhan via ddas)
|
|
|
+
|
|
|
+ HADOOP-6105. Adds support for automatically handling deprecation of
|
|
|
+ configuration keys. (V.V.Chaitanya Krishna via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-6235. Adds new method to FileSystem for clients to get server
|
|
|
+ defaults. (Kan Zhang via suresh)
|
|
|
+
|
|
|
+ HADOOP-6234. Add new option dfs.umaskmode to set umask in configuration
|
|
|
+ to use octal or symbolic instead of decimal. (Jakob Homan via suresh)
|
|
|
+
|
|
|
+ HADOOP-5073. Add annotation mechanism for interface classification.
|
|
|
+ (Jakob Homan via suresh)
|
|
|
+
|
|
|
+ HADOOP-4012. Provide splitting support for bzip2 compressed files. (Abdul
|
|
|
+ Qadeer via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6246. Add backward compatibility support to use deprecated decimal
|
|
|
+ umask from old configuration. (Jakob Homan via suresh)
|
|
|
+
|
|
|
+ HADOOP-4952. Add new improved file system interface FileContext for the
|
|
|
+ application writer (Sanjay Radia via suresh)
|
|
|
+
|
|
|
+ HADOOP-6170. Add facility to tunnel Avro RPCs through Hadoop RPCs.
|
|
|
+ This permits one to take advantage of both Avro's RPC versioning
|
|
|
+ features and Hadoop's proven RPC scalability. (cutting)
|
|
|
+
|
|
|
+ HADOOP-6267. Permit building contrib modules located in external
|
|
|
+ source trees. (Todd Lipcon via cutting)
|
|
|
+
|
|
|
+ HADOOP-6240. Add new FileContext rename operation that posix compliant
|
|
|
+ that allows overwriting existing destination. (suresh)
|
|
|
+
|
|
|
+ HADOOP-6204. Implementing aspects development and fault injeciton
|
|
|
+ framework for Hadoop (cos)
|
|
|
+
|
|
|
+ HADOOP-6313. Implement Syncable interface in FSDataOutputStream to expose
|
|
|
+ flush APIs to application users. (Hairong Kuang via suresh)
|
|
|
+
|
|
|
+ HADOOP-6284. Add a new parameter, HADOOP_JAVA_PLATFORM_OPTS, to
|
|
|
+ hadoop-config.sh so that it allows setting java command options for
|
|
|
+ JAVA_PLATFORM. (Koji Noguchi via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6337. Updates FilterInitializer class to be more visible,
|
|
|
+ and the init of the class is made to take a Configuration argument.
|
|
|
+ (Jakob Homan via ddas)
|
|
|
+
|
|
|
+ Hadoop-6223. Add new file system interface AbstractFileSystem with
|
|
|
+ implementation of some file systems that delegate to old FileSystem.
|
|
|
+ (Sanjay Radia via suresh)
|
|
|
+
|
|
|
+ HADOOP-6433. Introduce asychronous deletion of files via a pool of
|
|
|
+ threads. This can be used to delete files in the Distributed
|
|
|
+ Cache. (Zheng Shao via dhruba)
|
|
|
+
|
|
|
+ HADOOP-6415. Adds a common token interface for both job token and
|
|
|
+ delegation token. (Kan Zhang via ddas)
|
|
|
+
|
|
|
+ HADOOP-6408. Add a /conf servlet to dump running configuration.
|
|
|
+ (Todd Lipcon via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6520. Adds APIs to read/write Token and secret keys. Also
|
|
|
+ adds the automatic loading of tokens into UserGroupInformation
|
|
|
+ upon login. The tokens are read from a file specified in the
|
|
|
+ environment variable. (ddas)
|
|
|
+
|
|
|
+ HADOOP-6419. Adds SASL based authentication to RPC.
|
|
|
+ (Kan Zhang via ddas)
|
|
|
+
|
|
|
+ HADOOP-6510. Adds a way for superusers to impersonate other users
|
|
|
+ in a secure environment. (Jitendra Nath Pandey via ddas)
|
|
|
+
|
|
|
+ HADOOP-6421. Adds Symbolic links to FileContext, AbstractFileSystem.
|
|
|
+ It also adds a limited implementation for the local file system
|
|
|
+ (RawLocalFs) that allows local symlinks. (Eli Collins via Sanjay Radia)
|
|
|
+
|
|
|
+ HADOOP-6577. Add hidden configuration option "ipc.server.max.response.size"
|
|
|
+ to change the default 1 MB, the maximum size when large IPC handler
|
|
|
+ response buffer is reset. (suresh)
|
|
|
+
|
|
|
+ HADOOP-6568. Adds authorization for the default servlets.
|
|
|
+ (Vinod Kumar Vavilapalli via ddas)
|
|
|
+
|
|
|
+ HADOOP-6586. Log authentication and authorization failures and successes
|
|
|
+ for RPC (boryas)
|
|
|
+
|
|
|
+ HADOOP-6580. UGI should contain authentication method. (jnp via boryas)
|
|
|
+
|
|
|
+ HADOOP-6657. Add a capitalization method to StringUtils for MAPREDUCE-1545.
|
|
|
+ (Luke Lu via Steve Loughran)
|
|
|
+
|
|
|
+ HADOOP-6692. Add FileContext#listStatus that returns an iterator.
|
|
|
+ (hairong)
|
|
|
+
|
|
|
+ HADOOP-6869. Functionality to create file or folder on a remote daemon
|
|
|
+ side (Vinay Thota via cos)
|
|
|
+
|
|
|
+ IMPROVEMENTS
|
|
|
+
|
|
|
+ HADOOP-6798. Align Ivy version for all Hadoop subprojects. (cos)
|
|
|
+
|
|
|
+ HADOOP-6777. Implement a functionality for suspend and resume a process.
|
|
|
+ (Vinay Thota via cos)
|
|
|
+
|
|
|
+ HADOOP-6772. Utilities for system tests specific. (Vinay Thota via cos)
|
|
|
+
|
|
|
+ HADOOP-6771. Herriot's artifact id for Maven deployment should be set to
|
|
|
+ hadoop-core-instrumented (cos)
|
|
|
+
|
|
|
+ HADOOP-6752. Remote cluster control functionality needs JavaDocs
|
|
|
+ improvement (Balaji Rajagopalan via cos).
|
|
|
+
|
|
|
+ HADOOP-4565. Added CombineFileInputFormat to use data locality information
|
|
|
+ to create splits. (dhruba via zshao)
|
|
|
+
|
|
|
+ HADOOP-4936. Improvements to TestSafeMode. (shv)
|
|
|
+
|
|
|
+ HADOOP-4985. Remove unnecessary "throw IOException" declarations in
|
|
|
+ FSDirectory related methods. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5017. Change NameNode.namesystem declaration to private. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4794. Add branch information from the source version control into
|
|
|
+ the version information that is compiled into Hadoop. (cdouglas via
|
|
|
+ omalley)
|
|
|
+
|
|
|
+ HADOOP-5070. Increment copyright year to 2009, remove assertions of ASF
|
|
|
+ copyright to licensed files. (Tsz Wo (Nicholas), SZE via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5037. Deprecate static FSNamesystem.getFSNamesystem(). (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5088. Include releaseaudit target as part of developer test-patch
|
|
|
+ target. (Giridharan Kesavan via nigel)
|
|
|
+
|
|
|
+ HADOOP-2721. Uses setsid when creating new tasks so that subprocesses of
|
|
|
+ this process will be within this new session (and this process will be
|
|
|
+ the process leader for all the subprocesses). Killing the process leader,
|
|
|
+ or the main Java task in Hadoop's case, kills the entire subtree of
|
|
|
+ processes. (Ravi Gummadi via ddas)
|
|
|
+
|
|
|
+ HADOOP-5097. Remove static variable JspHelper.fsn, a static reference to
|
|
|
+ a non-singleton FSNamesystem object. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-3327. Improves handling of READ_TIMEOUT during map output copying.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-5124. Choose datanodes randomly instead of starting from the first
|
|
|
+ datanode for providing fairness. (hairong via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4930. Implement a Linux native executable that can be used to
|
|
|
+ launch tasks as users. (Sreekanth Ramakrishnan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5122. Fix format of fs.default.name value in libhdfs test conf.
|
|
|
+ (Craig Macdonald via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-5038. Direct daemon trace to debug log instead of stdout. (Jerome
|
|
|
+ Boulon via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5101. Improve packaging by adding 'all-jars' target building core,
|
|
|
+ tools, and example jars. Let findbugs depend on this rather than the 'tar'
|
|
|
+ target. (Giridharan Kesavan via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4868. Splits the hadoop script into three parts - bin/hadoop,
|
|
|
+ bin/mapred and bin/hdfs. (Sharad Agarwal via ddas)
|
|
|
+
|
|
|
+ HADOOP-1722. Adds support for TypedBytes and RawBytes in Streaming.
|
|
|
+ (Klaas Bosteels via ddas)
|
|
|
+
|
|
|
+ HADOOP-4220. Changes the JobTracker restart tests so that they take much
|
|
|
+ less time. (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-4885. Try to restore failed name-node storage directories at
|
|
|
+ checkpoint time. (Boris Shkolnik via shv)
|
|
|
+
|
|
|
+ HADOOP-5209. Update year to 2009 for javadoc. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5279. Remove unnecessary targets from test-patch.sh.
|
|
|
+ (Giridharan Kesavan via nigel)
|
|
|
+
|
|
|
+ HADOOP-5120. Remove the use of FSNamesystem.getFSNamesystem() from
|
|
|
+ UpgradeManagerNamenode and UpgradeObjectNamenode. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5222. Add offset to datanode clienttrace. (Lei Xu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5240. Skip re-building javadoc when it is already
|
|
|
+ up-to-date. (Aaron Kimball via cutting)
|
|
|
+
|
|
|
+ HADOOP-5042. Add a cleanup stage to log rollover in Chukwa appender.
|
|
|
+ (Jerome Boulon via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5264. Removes redundant configuration object from the TaskTracker.
|
|
|
+ (Sharad Agarwal via ddas)
|
|
|
+
|
|
|
+ HADOOP-5232. Enable patch testing to occur on more than one host.
|
|
|
+ (Giri Kesavan via nigel)
|
|
|
+
|
|
|
+ HADOOP-4546. Fix DF reporting for AIX. (Bill Habermaas via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5023. Add Tomcat support to HdfsProxy. (Zhiyong Zhang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5317. Provide documentation for LazyOutput Feature.
|
|
|
+ (Jothi Padmanabhan via johan)
|
|
|
+
|
|
|
+ HADOOP-5455. Document rpc metrics context to the extent dfs, mapred, and
|
|
|
+ jvm contexts are documented. (Philip Zeyliger via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5358. Provide scripting functionality to the synthetic load
|
|
|
+ generator. (Jakob Homan via hairong)
|
|
|
+
|
|
|
+ HADOOP-5442. Paginate jobhistory display and added some search
|
|
|
+ capabilities. (Amar Kamat via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4842. Streaming now allows specifiying a command for the combiner.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-5196. avoiding unnecessary byte[] allocation in
|
|
|
+ SequenceFile.CompressedBytes and SequenceFile.UncompressedBytes.
|
|
|
+ (hong tang via mahadev)
|
|
|
+
|
|
|
+ HADOOP-4655. New method FileSystem.newInstance() that always returns
|
|
|
+ a newly allocated FileSystem object. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-4788. Set Fair scheduler to assign both a map and a reduce on each
|
|
|
+ heartbeat by default. (matei)
|
|
|
+
|
|
|
+ HADOOP-5491. In contrib/index, better control memory usage.
|
|
|
+ (Ning Li via cutting)
|
|
|
+
|
|
|
+ HADOOP-5423. Include option of preserving file metadata in
|
|
|
+ SequenceFile::sort. (Michael Tamm via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5331. Add support for KFS appends. (Sriram Rao via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4365. Make Configuration::getProps protected in support of
|
|
|
+ meaningful subclassing. (Steve Loughran via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2413. Remove the static variable FSNamesystem.fsNamesystemObject.
|
|
|
+ (Konstantin Shvachko via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4584. Improve datanode block reports and associated file system
|
|
|
+ scan to avoid interefering with normal datanode operations.
|
|
|
+ (Suresh Srinivas via rangadi)
|
|
|
+
|
|
|
+ HADOOP-5502. Documentation for backup and checkpoint nodes.
|
|
|
+ (Jakob Homan via shv)
|
|
|
+
|
|
|
+ HADOOP-5485. Mask actions in the fair scheduler's servlet UI based on
|
|
|
+ value of webinterface.private.actions.
|
|
|
+ (Vinod Kumar Vavilapalli via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5581. HDFS should throw FileNotFoundException when while opening
|
|
|
+ a file that does not exist. (Brian Bockelman via rangadi)
|
|
|
+
|
|
|
+ HADOOP-5509. PendingReplicationBlocks does not start monitor in the
|
|
|
+ constructor. (shv)
|
|
|
+
|
|
|
+ HADOOP-5494. Modify sorted map output merger to lazily read values,
|
|
|
+ rather than buffering at least one record for each segment. (Devaraj Das
|
|
|
+ via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5396. Provide ability to refresh queue ACLs in the JobTracker
|
|
|
+ without having to restart the daemon.
|
|
|
+ (Sreekanth Ramakrishnan and Vinod Kumar Vavilapalli via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-4490. Provide ability to run tasks as job owners.
|
|
|
+ (Sreekanth Ramakrishnan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5697. Change org.apache.hadoop.examples.Grep to use new
|
|
|
+ mapreduce api. (Amareshwari Sriramadasu via sharad)
|
|
|
+
|
|
|
+ HADOOP-5625. Add operation duration to clienttrace. (Lei Xu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5705. Improve TotalOrderPartitioner efficiency by updating the trie
|
|
|
+ construction. (Dick King via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5589. Eliminate source limit of 64 for map-side joins imposed by
|
|
|
+ TupleWritable encoding. (Jingkei Ly via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5734. Correct block placement policy description in HDFS
|
|
|
+ Design document. (Konstantin Boudnik via shv)
|
|
|
+
|
|
|
+ HADOOP-5657. Validate data in TestReduceFetch to improve merge test
|
|
|
+ coverage. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5613. Change S3Exception to checked exception.
|
|
|
+ (Andrew Hitchcock via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-5717. Create public enum class for the Framework counters in
|
|
|
+ org.apache.hadoop.mapreduce. (Amareshwari Sriramadasu via sharad)
|
|
|
+
|
|
|
+ HADOOP-5217. Split AllTestDriver for core, hdfs and mapred. (sharad)
|
|
|
+
|
|
|
+ HADOOP-5364. Add certificate expiration warning to HsftpFileSystem and HDFS
|
|
|
+ proxy. (Zhiyong Zhang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5733. Add map/reduce slot capacity and blacklisted capacity to
|
|
|
+ JobTracker metrics. (Sreekanth Ramakrishnan via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5596. Add EnumSetWritable. (He Yongqiang via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5727. Simplify hashcode for ID types. (Shevek via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5500. In DBOutputFormat, where field names are absent permit the
|
|
|
+ number of fields to be sufficient to construct the select query. (Enis
|
|
|
+ Soztutar via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5081. Split TestCLI into HDFS, Mapred and Core tests. (sharad)
|
|
|
+
|
|
|
+ HADOOP-5015. Separate block management code from FSNamesystem. (Suresh
|
|
|
+ Srinivas via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5080. Add new test cases to TestMRCLI and TestHDFSCLI
|
|
|
+ (V.Karthikeyan via nigel)
|
|
|
+
|
|
|
+ HADOOP-5135. Splits the tests into different directories based on the
|
|
|
+ package. Four new test targets have been defined - run-test-core,
|
|
|
+ run-test-mapred, run-test-hdfs and run-test-hdfs-with-mr.
|
|
|
+ (Sharad Agarwal via ddas)
|
|
|
+
|
|
|
+ HADOOP-5771. Implements unit tests for LinuxTaskController.
|
|
|
+ (Sreekanth Ramakrishnan and Vinod Kumar Vavilapalli via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5419. Provide a facility to query the Queue ACLs for the
|
|
|
+ current user.
|
|
|
+ (Rahul Kumar Singh via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5780. Improve per block message prited by "-metaSave" in HDFS.
|
|
|
+ (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-5823. Added a new class DeprecatedUTF8 to help with removing
|
|
|
+ UTF8 related javac warnings. These warnings are removed in
|
|
|
+ FSEditLog.java as a use case. (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-5824. Deprecate DataTransferProtocol.OP_READ_METADATA and remove
|
|
|
+ the corresponding unused codes. (Kan Zhang via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5721. Factor out EditLogFileInputStream and EditLogFileOutputStream
|
|
|
+ into independent classes. (Luca Telloli & Flavio Junqueira via shv)
|
|
|
+
|
|
|
+ HADOOP-5838. Fix a few javac warnings in HDFS. (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-5854. Fix a few "Inconsistent Synchronization" warnings in HDFS.
|
|
|
+ (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-5369. Small tweaks to reduce MapFile index size. (Ben Maurer
|
|
|
+ via sharad)
|
|
|
+
|
|
|
+ HADOOP-5858. Eliminate UTF8 and fix warnings in test/hdfs-with-mr package.
|
|
|
+ (shv)
|
|
|
+
|
|
|
+ HADOOP-5866. Move DeprecatedUTF8 from o.a.h.io to o.a.h.hdfs since it may
|
|
|
+ not be used outside hdfs. (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-5857. Move normal java methods from hdfs .jsp files to .java files.
|
|
|
+ (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5873. Remove deprecated methods randomDataNode() and
|
|
|
+ getDatanodeByIndex(..) in FSNamesystem. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5572. Improves the progress reporting for the sort phase for both
|
|
|
+ maps and reduces. (Ravi Gummadi via ddas)
|
|
|
+
|
|
|
+ HADOOP-5839. Fix EC2 scripts to allow remote job submission.
|
|
|
+ (Joydeep Sen Sarma via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-5877. Fix javac warnings in TestHDFSServerPorts, TestCheckpoint,
|
|
|
+ TestNameEditsConfig, TestStartup and TestStorageRestore.
|
|
|
+ (Jakob Homan via shv)
|
|
|
+
|
|
|
+ HADOOP-5438. Provide a single FileSystem method to create or
|
|
|
+ open-for-append to a file. (He Yongqiang via dhruba)
|
|
|
+
|
|
|
+ HADOOP-5472. Change DistCp to support globbing of input paths. (Dhruba
|
|
|
+ Borthakur and Rodrigo Schmidt via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5175. Don't unpack libjars on classpath. (Todd Lipcon via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-5620. Add an option to DistCp for preserving modification and access
|
|
|
+ times. (Rodrigo Schmidt via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5664. Change map serialization so a lock is obtained only where
|
|
|
+ contention is possible, rather than for each write. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5896. Remove the dependency of GenericOptionsParser on
|
|
|
+ Option.withArgPattern. (Giridharan Kesavan and Sharad Agarwal via
|
|
|
+ sharad)
|
|
|
+
|
|
|
+ HADOOP-5784. Makes the number of heartbeats that should arrive a second
|
|
|
+ at the JobTracker configurable. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-5955. Changes TestFileOuputFormat so that is uses LOCAL_MR
|
|
|
+ instead of CLUSTER_MR. (Jothi Padmanabhan via das)
|
|
|
+
|
|
|
+ HADOOP-5948. Changes TestJavaSerialization to use LocalJobRunner
|
|
|
+ instead of MiniMR/DFS cluster. (Jothi Padmanabhan via das)
|
|
|
+
|
|
|
+ HADOOP-2838. Add mapred.child.env to pass environment variables to
|
|
|
+ tasktracker's child processes. (Amar Kamat via sharad)
|
|
|
+
|
|
|
+ HADOOP-5961. DataNode process understand generic hadoop command line
|
|
|
+ options (like -Ddfs.property=value). (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-5938. Change org.apache.hadoop.mapred.jobcontrol to use new
|
|
|
+ api. (Amareshwari Sriramadasu via sharad)
|
|
|
+
|
|
|
+ HADOOP-2141. Improves the speculative execution heuristic. The heuristic
|
|
|
+ is currently based on the progress-rates of tasks and the expected time
|
|
|
+ to complete. Also, statistics about trackers are collected, and speculative
|
|
|
+ tasks are not given to the ones deduced to be slow.
|
|
|
+ (Andy Konwinski and ddas)
|
|
|
+
|
|
|
+ HADOOP-5952. Change "-1 tests included" wording in test-patch.sh.
|
|
|
+ (Gary Murry via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6106. Provides an option in ShellCommandExecutor to timeout
|
|
|
+ commands that do not complete within a certain amount of time.
|
|
|
+ (Sreekanth Ramakrishnan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5925. EC2 scripts should exit on error. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6109. Change Text to grow its internal buffer exponentially, rather
|
|
|
+ than the max of the current length and the proposed length to improve
|
|
|
+ performance reading large values. (thushara wijeratna via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2366. Support trimmed strings in Configuration. (Michele Catasta
|
|
|
+ via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6099. The RPC module can be configured to not send period pings.
|
|
|
+ The default behaviour of sending periodic pings remain unchanged. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-6142. Update documentation and use of harchives for relative paths
|
|
|
+ added in MAPREDUCE-739. (Mahadev Konar via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6148. Implement a fast, pure Java CRC32 calculator which outperforms
|
|
|
+ java.util.zip.CRC32. (Todd Lipcon and Scott Carey via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6146. Upgrade to JetS3t version 0.7.1. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6161. Add get/setEnum methods to Configuration. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6160. Fix releaseaudit target to run on specific directories.
|
|
|
+ (gkesavan)
|
|
|
+
|
|
|
+ HADOOP-6169. Removing deprecated method calls in TFile. (hong tang via
|
|
|
+ mahadev)
|
|
|
+
|
|
|
+ HADOOP-6176. Add a couple package private methods to AccessTokenHandler
|
|
|
+ for testing. (Kan Zhang via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6182. Fix ReleaseAudit warnings (Giridharan Kesavan and Lee Tucker
|
|
|
+ via gkesavan)
|
|
|
+
|
|
|
+ HADOOP-6173. Change src/native/packageNativeHadoop.sh to package all
|
|
|
+ native library files. (Hong Tang via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6184. Provide an API to dump Configuration in a JSON format.
|
|
|
+ (V.V.Chaitanya Krishna via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-6224. Add a method to WritableUtils performing a bounded read of an
|
|
|
+ encoded String. (Jothi Padmanabhan via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6133. Add a caching layer to Configuration::getClassByName to
|
|
|
+ alleviate a performance regression introduced in a compatibility layer.
|
|
|
+ (Todd Lipcon via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6252. Provide a method to determine if a deprecated key is set in
|
|
|
+ config file. (Jakob Homan via suresh)
|
|
|
+
|
|
|
+ HADOOP-5879. Read compression level and strategy from Configuration for
|
|
|
+ gzip compression. (He Yongqiang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6216. Support comments in host files. (Ravi Phulari and Dmytro
|
|
|
+ Molkov via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6217. Update documentation for project split. (Corinne Chandel via
|
|
|
+ omalley)
|
|
|
+
|
|
|
+ HADOOP-6268. Add ivy jar to .gitignore. (Todd Lipcon via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6270. Support deleteOnExit in FileContext. (Suresh Srinivas via
|
|
|
+ szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6233. Rename configuration keys towards API standardization and
|
|
|
+ backward compatibility. (Jithendra Pandey via suresh)
|
|
|
+
|
|
|
+ HADOOP-6260. Add additional unit tests for FileContext util methods.
|
|
|
+ (Gary Murry via suresh).
|
|
|
+
|
|
|
+ HADOOP-6309. Change build.xml to run tests with java asserts. (Eli
|
|
|
+ Collins via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6326. Hundson runs should check for AspectJ warnings and report
|
|
|
+ failure if any is present (cos)
|
|
|
+
|
|
|
+ HADOOP-6329. Add build-fi directory to the ignore lists. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5107. Use Maven ant tasks to publish the subproject jars.
|
|
|
+ (Giridharan Kesavan via omalley)
|
|
|
+
|
|
|
+ HADOOP-6343. Log unexpected throwable object caught in RPC. (Jitendra Nath
|
|
|
+ Pandey via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6367. Removes Access Token implementation from common.
|
|
|
+ (Kan Zhang via ddas)
|
|
|
+
|
|
|
+ HADOOP-6395. Upgrade some libraries to be consistent across common, hdfs,
|
|
|
+ and mapreduce. (omalley)
|
|
|
+
|
|
|
+ HADOOP-6398. Build is broken after HADOOP-6395 patch has been applied (cos)
|
|
|
+
|
|
|
+ HADOOP-6413. Move TestReflectionUtils to Common. (Todd Lipcon via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6283. Improve the exception messages thrown by
|
|
|
+ FileUtil$HardLink.getLinkCount(..). (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6279. Add Runtime::maxMemory to JVM metrics. (Todd Lipcon via
|
|
|
+ cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6305. Unify build property names to facilitate cross-projects
|
|
|
+ modifications (cos)
|
|
|
+
|
|
|
+ HADOOP-6312. Remove unnecessary debug logging in Configuration constructor.
|
|
|
+ (Aaron Kimball via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6366. Reduce ivy console output to ovservable level (cos)
|
|
|
+
|
|
|
+ HADOOP-6400. Log errors getting Unix UGI. (Todd Lipcon via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6346. Add support for specifying unpack pattern regex to
|
|
|
+ RunJar.unJar. (Todd Lipcon via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6422. Make RPC backend plugable, protocol-by-protocol, to
|
|
|
+ ease evolution towards Avro. (cutting)
|
|
|
+
|
|
|
+ HADOOP-5958. Use JDK 1.6 File APIs in DF.java wherever possible.
|
|
|
+ (Aaron Kimball via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6222. Core doesn't have TestCommonCLI facility. (cos)
|
|
|
+
|
|
|
+ HADOOP-6394. Add a helper class to simplify FileContext related tests and
|
|
|
+ improve code reusability. (Jitendra Nath Pandey via suresh)
|
|
|
+
|
|
|
+ HADOOP-4656. Add a user to groups mapping service. (boryas, acmurthy)
|
|
|
+
|
|
|
+ HADOOP-6435. Make RPC.waitForProxy with timeout public. (Steve Loughran
|
|
|
+ via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6472. add tokenCache option to GenericOptionsParser for passing
|
|
|
+ file with secret keys to a map reduce job. (boryas)
|
|
|
+
|
|
|
+ HADOOP-3205. Read multiple chunks directly from FSInputChecker subclass
|
|
|
+ into user buffers. (Todd Lipcon via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6479. TestUTF8 assertions could fail with better text.
|
|
|
+ (Steve Loughran via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6155. Deprecate RecordIO anticipating Avro. (Tom White via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6492. Make some Avro serialization APIs public.
|
|
|
+ (Aaron Kimball via cutting)
|
|
|
+
|
|
|
+ HADOOP-6497. Add an adapter for Avro's SeekableInput interface, so
|
|
|
+ that Avro can read FileSystem data.
|
|
|
+ (Aaron Kimball via cutting)
|
|
|
+
|
|
|
+ HADOOP-6495. Identifier should be serialized after the password is
|
|
|
+ created In Token constructor (jnp via boryas)
|
|
|
+
|
|
|
+ HADOOP-6518. Makes the UGI honor the env var KRB5CCNAME.
|
|
|
+ (Owen O'Malley via ddas)
|
|
|
+
|
|
|
+ HADOOP-6531. Enhance FileUtil with an API to delete all contents of a
|
|
|
+ directory. (Amareshwari Sriramadasu via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-6547. Move DelegationToken into Common, so that it can be used by
|
|
|
+ MapReduce also. (devaraj via omalley)
|
|
|
+
|
|
|
+ HADOOP-6552. Puts renewTGT=true and useTicketCache=true for the keytab
|
|
|
+ kerberos options. (ddas)
|
|
|
+
|
|
|
+ HADOOP-6534. Trim whitespace from directory lists initializing
|
|
|
+ LocalDirAllocator. (Todd Lipcon via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6559. Makes the RPC client automatically re-login when the SASL
|
|
|
+ connection setup fails. This is applicable only to keytab based logins.
|
|
|
+ (Devaraj Das)
|
|
|
+
|
|
|
+ HADOOP-6551. Delegation token renewing and cancelling should provide
|
|
|
+ meaningful exceptions when there are failures instead of returning
|
|
|
+ false. (omalley)
|
|
|
+
|
|
|
+ HADOOP-6583. Captures authentication and authorization metrics. (ddas)
|
|
|
+
|
|
|
+ HADOOP-6543. Allows secure clients to talk to unsecure clusters.
|
|
|
+ (Kan Zhang via ddas)
|
|
|
+
|
|
|
+ HADOOP-6579. Provide a mechanism for encoding/decoding Tokens from
|
|
|
+ a url-safe string and change the commons-code library to 1.4. (omalley)
|
|
|
+
|
|
|
+ HADOOP-6596. Add a version field to the AbstractDelegationTokenIdentifier's
|
|
|
+ serialized value. (omalley)
|
|
|
+
|
|
|
+ HADOOP-6573. Support for persistent delegation tokens.
|
|
|
+ (Jitendra Pandey via shv)
|
|
|
+
|
|
|
+ HADOOP-6594. Provide a fetchdt tool via bin/hdfs. (jhoman via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-6589. Provide better error messages when RPC authentication fails.
|
|
|
+ (Kan Zhang via omalley)
|
|
|
+
|
|
|
+ HADOOP-6599 Split existing RpcMetrics into RpcMetrics & RpcDetailedMetrics.
|
|
|
+ (Suresh Srinivas via Sanjay Radia)
|
|
|
+
|
|
|
+ HADOOP-6537 Declare more detailed exceptions in FileContext and
|
|
|
+ AbstractFileSystem (Suresh Srinivas via Sanjay Radia)
|
|
|
+
|
|
|
+ HADOOP-6486. fix common classes to work with Avro 1.3 reflection.
|
|
|
+ (cutting via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6591. HarFileSystem can handle paths with the whitespace characters.
|
|
|
+ (Rodrigo Schmidt via dhruba)
|
|
|
+
|
|
|
+ HADOOP-6407. Have a way to automatically update Eclipse .classpath file
|
|
|
+ when new libs are added to the classpath through Ivy. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-3659. Patch to allow hadoop native to compile on Mac OS X.
|
|
|
+ (Colin Evans and Allen Wittenauer via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6471. StringBuffer -> StringBuilder - conversion of references
|
|
|
+ as necessary. (Kay Kay via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6646. Move HarfileSystem out of Hadoop Common. (mahadev)
|
|
|
+
|
|
|
+ HADOOP-6566. Add methods supporting, enforcing narrower permissions on
|
|
|
+ local daemon directories. (Arun Murthy and Luke Lu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6705. Fix to work with 1.5 version of jiracli
|
|
|
+ (Giridharan Kesavan)
|
|
|
+
|
|
|
+ HADOOP-6658. Exclude Private elements from generated Javadoc. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6635. Install/deploy source jars to Maven repo.
|
|
|
+ (Patrick Angeles via jghoman)
|
|
|
+
|
|
|
+ HADOOP-6717. Log levels in o.a.h.security.Groups too high
|
|
|
+ (Todd Lipcon via jghoman)
|
|
|
+
|
|
|
+ HADOOP-6667. RPC.waitForProxy should retry through NoRouteToHostException.
|
|
|
+ (Todd Lipcon via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6677. InterfaceAudience.LimitedPrivate should take a string not an
|
|
|
+ enum. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-678. Remove FileContext#isFile, isDirectory, and exists.
|
|
|
+ (Eli Collins via hairong)
|
|
|
+
|
|
|
+ HADOOP-6515. Make maximum number of http threads configurable.
|
|
|
+ (Scott Chen via zshao)
|
|
|
+
|
|
|
+ HADOOP-6563. Add more symlink tests to cover intermediate symlinks
|
|
|
+ in paths. (Eli Collins via suresh)
|
|
|
+
|
|
|
+ HADOOP-6585. Add FileStatus#isDirectory and isFile. (Eli Collins via
|
|
|
+ tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6738. Move cluster_setup.xml from MapReduce to Common.
|
|
|
+ (Tom White via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6794. Move configuration and script files post split. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6403. Deprecate EC2 bash scripts. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6769. Add an API in FileSystem to get FileSystem instances based
|
|
|
+ on users(ddas via boryas)
|
|
|
+
|
|
|
+ HADOOP-6813. Add a new newInstance method in FileSystem that takes
|
|
|
+ a "user" as argument (ddas via boryas)
|
|
|
+
|
|
|
+ HADOOP-6668. Apply audience and stability annotations to classes in
|
|
|
+ common. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6821. Document changes to memory monitoring. (Hemanth Yamijala
|
|
|
+ via tomwhite)
|
|
|
+
|
|
|
+ OPTIMIZATIONS
|
|
|
+
|
|
|
+ HADOOP-5595. NameNode does not need to run a replicator to choose a
|
|
|
+ random DataNode. (hairong)
|
|
|
+
|
|
|
+ HADOOP-5603. Improve NameNode's block placement performance. (hairong)
|
|
|
+
|
|
|
+ HADOOP-5638. More improvement on block placement performance. (hairong)
|
|
|
+
|
|
|
+ HADOOP-6180. NameNode slowed down when many files with same filename
|
|
|
+ were moved to Trash. (Boris Shkolnik via hairong)
|
|
|
+
|
|
|
+ HADOOP-6166. Further improve the performance of the pure-Java CRC32
|
|
|
+ implementation. (Tsz Wo (Nicholas), SZE via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6271. Add recursive and non recursive create and mkdir to
|
|
|
+ FileContext. (Sanjay Radia via suresh)
|
|
|
+
|
|
|
+ HADOOP-6261. Add URI based tests for FileContext.
|
|
|
+ (Ravi Pulari via suresh).
|
|
|
+
|
|
|
+ HADOOP-6307. Add a new SequenceFile.Reader constructor in order to support
|
|
|
+ reading on un-closed file. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6467. Improve the performance on HarFileSystem.listStatus(..).
|
|
|
+ (mahadev via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6569. FsShell#cat should avoid calling unecessary getFileStatus
|
|
|
+ before opening a file to read. (hairong)
|
|
|
+
|
|
|
+ HADOOP-6689. Add directory renaming test to existing FileContext tests.
|
|
|
+ (Eli Collins via suresh)
|
|
|
+
|
|
|
+ HADOOP-6713. The RPC server Listener thread is a scalability bottleneck.
|
|
|
+ (Dmytro Molkov via hairong)
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-6748. Removes hadoop.cluster.administrators, cluster administrators
|
|
|
+ acl is passed as parameter in constructor. (amareshwari)
|
|
|
+
|
|
|
+ HADOOP-6828. Herrior uses old way of accessing logs directories (Sreekanth
|
|
|
+ Ramakrishnan via cos)
|
|
|
+
|
|
|
+ HADOOP-6788. [Herriot] Exception exclusion functionality is not working
|
|
|
+ correctly. (Vinay Thota via cos)
|
|
|
+
|
|
|
+ HADOOP-6773. Ivy folder contains redundant files (cos)
|
|
|
+
|
|
|
+ HADOOP-5379. CBZip2InputStream to throw IOException on data crc error.
|
|
|
+ (Rodrigo Schmidt via zshao)
|
|
|
+
|
|
|
+ HADOOP-5326. Fixes CBZip2OutputStream data corruption problem.
|
|
|
+ (Rodrigo Schmidt via zshao)
|
|
|
+
|
|
|
+ HADOOP-4963. Fixes a logging to do with getting the location of
|
|
|
+ map output file. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2337. Trash should close FileSystem on exit and should not start
|
|
|
+ emtying thread if disabled. (shv)
|
|
|
+
|
|
|
+ HADOOP-5072. Fix failure in TestCodec because testSequenceFileGzipCodec
|
|
|
+ won't pass without native gzip codec. (Zheng Shao via dhruba)
|
|
|
+
|
|
|
+ HADOOP-5050. TestDFSShell.testFilePermissions should not assume umask
|
|
|
+ setting. (Jakob Homan via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4975. Set classloader for nested mapred.join configs. (Jingkei Ly
|
|
|
+ via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5078. Remove invalid AMI kernel in EC2 scripts. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-5045. FileSystem.isDirectory() should not be deprecated. (Suresh
|
|
|
+ Srinivas via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4960. Use datasource time, rather than system time, during metrics
|
|
|
+ demux. (Eric Yang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5032. Export conf dir set in config script. (Eric Yang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5176. Fix a typo in TestDFSIO. (Ravi Phulari via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4859. Distinguish daily rolling output dir by adding a timestamp.
|
|
|
+ (Jerome Boulon via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4959. Correct system metric collection from top on Redhat 5.1. (Eric
|
|
|
+ Yang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5039. Fix log rolling regex to process only the relevant
|
|
|
+ subdirectories. (Jerome Boulon via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5095. Update Chukwa watchdog to accept config parameter. (Jerome
|
|
|
+ Boulon via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5147. Correct reference to agent list in Chukwa bin scripts. (Ari
|
|
|
+ Rabkin via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5148. Fix logic disabling watchdog timer in Chukwa daemon scripts.
|
|
|
+ (Ari Rabkin via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5100. Append, rather than truncate, when creating log4j metrics in
|
|
|
+ Chukwa. (Jerome Boulon via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5204. Fix broken trunk compilation on Hudson by letting
|
|
|
+ task-controller be an independent target in build.xml.
|
|
|
+ (Sreekanth Ramakrishnan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5212. Fix the path translation problem introduced by HADOOP-4868
|
|
|
+ running on cygwin. (Sharad Agarwal via omalley)
|
|
|
+
|
|
|
+ HADOOP-5226. Add license headers to html and jsp files. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5172. Disable misbehaving Chukwa unit test until it can be fixed.
|
|
|
+ (Jerome Boulon via nigel)
|
|
|
+
|
|
|
+ HADOOP-4933. Fixes a ConcurrentModificationException problem that shows up
|
|
|
+ when the history viewer is accessed concurrently.
|
|
|
+ (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-5253. Remove duplicate call to cn-docs target.
|
|
|
+ (Giri Kesavan via nigel)
|
|
|
+
|
|
|
+ HADOOP-5251. Fix classpath for contrib unit tests to include clover jar.
|
|
|
+ (nigel)
|
|
|
+
|
|
|
+ HADOOP-5206. Synchronize "unprotected*" methods of FSDirectory on the root.
|
|
|
+ (Jakob Homan via shv)
|
|
|
+
|
|
|
+ HADOOP-5292. Fix NPE in KFS::getBlockLocations. (Sriram Rao via lohit)
|
|
|
+
|
|
|
+ HADOOP-5219. Adds a new property io.seqfile.local.dir for use by
|
|
|
+ SequenceFile, which earlier used mapred.local.dir. (Sharad Agarwal
|
|
|
+ via ddas)
|
|
|
+
|
|
|
+ HADOOP-5300. Fix ant javadoc-dev target and the typo in the class name
|
|
|
+ NameNodeActivtyMBean. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5218. libhdfs unit test failed because it was unable to
|
|
|
+ start namenode/datanode. Fixed. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-5273. Add license header to TestJobInProgress.java. (Jakob Homan
|
|
|
+ via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5229. Remove duplicate version variables in build files
|
|
|
+ (Stefan Groschupf via johan)
|
|
|
+
|
|
|
+ HADOOP-5383. Avoid building an unused string in NameNode's
|
|
|
+ verifyReplication(). (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-5347. Create a job output directory for the bbp examples. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5341. Make hadoop-daemon scripts backwards compatible with the
|
|
|
+ changes in HADOOP-4868. (Sharad Agarwal via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5456. Fix javadoc links to ClientProtocol#restoreFailedStorage(..).
|
|
|
+ (Boris Shkolnik via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5458. Remove leftover Chukwa entries from build, etc. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5386. Modify hdfsproxy unit test to start on a random port,
|
|
|
+ implement clover instrumentation. (Zhiyong Zhang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5511. Add Apache License to EditLogBackupOutputStream. (shv)
|
|
|
+
|
|
|
+ HADOOP-5507. Fix JMXGet javadoc warnings. (Boris Shkolnik via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5191. Accessing HDFS with any ip or hostname should work as long
|
|
|
+ as it points to the interface NameNode is listening on. (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-5561. Add javadoc.maxmemory parameter to build, preventing OOM
|
|
|
+ exceptions from javadoc-dev. (Jakob Homan via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5149. Modify HistoryViewer to ignore unfamiliar files in the log
|
|
|
+ directory. (Hong Tang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5477. Fix rare failure in TestCLI for hosts returning variations of
|
|
|
+ 'localhost'. (Jakob Homan via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5194. Disables setsid for tasks run on cygwin.
|
|
|
+ (Ravi Gummadi via ddas)
|
|
|
+
|
|
|
+ HADOOP-5322. Fix misleading/outdated comments in JobInProgress.
|
|
|
+ (Amareshwari Sriramadasu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5198. Fixes a problem to do with the task PID file being absent and
|
|
|
+ the JvmManager trying to look for it. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-5464. DFSClient did not treat write timeout of 0 properly.
|
|
|
+ (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-4045. Fix processing of IO errors in EditsLog.
|
|
|
+ (Boris Shkolnik via shv)
|
|
|
+
|
|
|
+ HADOOP-5462. Fixed a double free bug in the task-controller
|
|
|
+ executable. (Sreekanth Ramakrishnan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5652. Fix a bug where in-memory segments are incorrectly retained in
|
|
|
+ memory. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5533. Recovery duration shown on the jobtracker webpage is
|
|
|
+ inaccurate. (Amar Kamat via sharad)
|
|
|
+
|
|
|
+ HADOOP-5647. Fix TestJobHistory to not depend on /tmp. (Ravi Gummadi
|
|
|
+ via sharad)
|
|
|
+
|
|
|
+ HADOOP-5661. Fixes some findbugs warnings in o.a.h.mapred* packages and
|
|
|
+ supresses a bunch of them. (Jothi Padmanabhan via ddas)
|
|
|
+
|
|
|
+ HADOOP-5704. Fix compilation problems in TestFairScheduler and
|
|
|
+ TestCapacityScheduler. (Chris Douglas via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5650. Fix safemode messages in the Namenode log. (Suresh Srinivas
|
|
|
+ via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5488. Removes the pidfile management for the Task JVM from the
|
|
|
+ framework and instead passes the PID back and forth between the
|
|
|
+ TaskTracker and the Task processes. (Ravi Gummadi via ddas)
|
|
|
+
|
|
|
+ HADOOP-5658. Fix Eclipse templates. (Philip Zeyliger via shv)
|
|
|
+
|
|
|
+ HADOOP-5709. Remove redundant synchronization added in HADOOP-5661. (Jothi
|
|
|
+ Padmanabhan via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5715. Add conf/mapred-queue-acls.xml to the ignore lists.
|
|
|
+ (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5592. Fix typo in Streaming doc in reference to GzipCodec.
|
|
|
+ (Corinne Chandel via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-5656. Counter for S3N Read Bytes does not work. (Ian Nowland
|
|
|
+ via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-5406. Fix JNI binding for ZlibCompressor::setDictionary. (Lars
|
|
|
+ Francke via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3426. Fix/provide handling when DNS lookup fails on the loopback
|
|
|
+ address. Also cache the result of the lookup. (Steve Loughran via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5476. Close the underlying InputStream in SequenceFile::Reader when
|
|
|
+ the constructor throws an exception. (Michael Tamm via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5675. Do not launch a job if DistCp has no work to do. (Tsz Wo
|
|
|
+ (Nicholas), SZE via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5737. Fixes a problem in the way the JobTracker used to talk to
|
|
|
+ other daemons like the NameNode to get the job's files. Also adds APIs
|
|
|
+ in the JobTracker to get the FileSystem objects as per the JobTracker's
|
|
|
+ configuration. (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-5648. Not able to generate gridmix.jar on the already compiled
|
|
|
+ version of hadoop. (gkesavan)
|
|
|
+
|
|
|
+ HADOOP-5808. Fix import never used javac warnings in hdfs. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5203. TT's version build is too restrictive. (Rick Cox via sharad)
|
|
|
+
|
|
|
+ HADOOP-5818. Revert the renaming from FSNamesystem.checkSuperuserPrivilege
|
|
|
+ to checkAccess by HADOOP-5643. (Amar Kamat via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5820. Fix findbugs warnings for http related codes in hdfs.
|
|
|
+ (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5822. Fix javac warnings in several dfs tests related to unncessary
|
|
|
+ casts. (Jakob Homan via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5842. Fix a few javac warnings under packages fs and util.
|
|
|
+ (Hairong Kuang via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5845. Build successful despite test failure on test-core target.
|
|
|
+ (sharad)
|
|
|
+
|
|
|
+ HADOOP-5314. Prevent unnecessary saving of the file system image during
|
|
|
+ name-node startup. (Jakob Homan via shv)
|
|
|
+
|
|
|
+ HADOOP-5855. Fix javac warnings for DisallowedDatanodeException and
|
|
|
+ UnsupportedActionException. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5582. Fixes a problem in Hadoop Vaidya to do with reading
|
|
|
+ counters from job history files. (Suhas Gogate via ddas)
|
|
|
+
|
|
|
+ HADOOP-5829. Fix javac warnings found in ReplicationTargetChooser,
|
|
|
+ FSImage, Checkpointer, SecondaryNameNode and a few other hdfs classes.
|
|
|
+ (Suresh Srinivas via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5835. Fix findbugs warnings found in Block, DataNode, NameNode and
|
|
|
+ a few other hdfs classes. (Suresh Srinivas via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5853. Undeprecate HttpServer.addInternalServlet method. (Suresh
|
|
|
+ Srinivas via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5801. Fixes the problem: If the hosts file is changed across restart
|
|
|
+ then it should be refreshed upon recovery so that the excluded hosts are
|
|
|
+ lost and the maps are re-executed. (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-5841. Resolve findbugs warnings in DistributedFileSystem,
|
|
|
+ DatanodeInfo, BlocksMap, DataNodeDescriptor. (Jakob Homan via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5878. Fix import and Serializable javac warnings found in hdfs jsp.
|
|
|
+ (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5782. Revert a few formatting changes introduced in HADOOP-5015.
|
|
|
+ (Suresh Srinivas via rangadi)
|
|
|
+
|
|
|
+ HADOOP-5687. NameNode throws NPE if fs.default.name is the default value.
|
|
|
+ (Philip Zeyliger via shv)
|
|
|
+
|
|
|
+ HADOOP-5867. Fix javac warnings found in NNBench and NNBenchWithoutMR.
|
|
|
+ (Konstantin Boudnik via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5728. Fixed FSEditLog.printStatistics IndexOutOfBoundsException.
|
|
|
+ (Wang Xu via johan)
|
|
|
+
|
|
|
+ HADOOP-5847. Fixed failing Streaming unit tests (gkesavan)
|
|
|
+
|
|
|
+ HADOOP-5252. Streaming overrides -inputformat option (Klaas Bosteels
|
|
|
+ via sharad)
|
|
|
+
|
|
|
+ HADOOP-5710. Counter MAP_INPUT_BYTES missing from new mapreduce api.
|
|
|
+ (Amareshwari Sriramadasu via sharad)
|
|
|
+
|
|
|
+ HADOOP-5809. Fix job submission, broken by errant directory creation.
|
|
|
+ (Sreekanth Ramakrishnan and Jothi Padmanabhan via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5635. Change distributed cache to work with other distributed file
|
|
|
+ systems. (Andrew Hitchcock via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-5856. Fix "unsafe multithreaded use of DateFormat" findbugs warning
|
|
|
+ in DataBlockScanner. (Kan Zhang via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4864. Fixes a problem to do with -libjars with multiple jars when
|
|
|
+ client and cluster reside on different OSs. (Amareshwari Sriramadasu via
|
|
|
+ ddas)
|
|
|
+
|
|
|
+ HADOOP-5623. Fixes a problem to do with status messages getting overwritten
|
|
|
+ in streaming jobs. (Rick Cox and Jothi Padmanabhan via ddas)
|
|
|
+
|
|
|
+ HADOOP-5895. Fixes computation of count of merged bytes for logging.
|
|
|
+ (Ravi Gummadi via ddas)
|
|
|
+
|
|
|
+ HADOOP-5805. problem using top level s3 buckets as input/output
|
|
|
+ directories. (Ian Nowland via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-5940. trunk eclipse-plugin build fails while trying to copy
|
|
|
+ commons-cli jar from the lib dir (Giridharan Kesavan via gkesavan)
|
|
|
+
|
|
|
+ HADOOP-5864. Fix DMI and OBL findbugs in packages hdfs and metrics.
|
|
|
+ (hairong)
|
|
|
+
|
|
|
+ HADOOP-5935. Fix Hudson's release audit warnings link is broken.
|
|
|
+ (Giridharan Kesavan via gkesavan)
|
|
|
+
|
|
|
+ HADOOP-5947. Delete empty TestCombineFileInputFormat.java
|
|
|
+
|
|
|
+ HADOOP-5899. Move a log message in FSEditLog to the right place for
|
|
|
+ avoiding unnecessary log. (Suresh Srinivas via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5944. Add Apache license header to BlockManager.java. (Suresh
|
|
|
+ Srinivas via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5891. SecondaryNamenode is able to converse with the NameNode
|
|
|
+ even when the default value of dfs.http.address is not overridden.
|
|
|
+ (Todd Lipcon via dhruba)
|
|
|
+
|
|
|
+ HADOOP-5953. The isDirectory(..) and isFile(..) methods in KosmosFileSystem
|
|
|
+ should not be deprecated. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5954. Fix javac warnings in TestFileCreation, TestSmallBlock,
|
|
|
+ TestFileStatus, TestDFSShellGenericOptions, TestSeekBug and
|
|
|
+ TestDFSStartupVersions. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5956. Fix ivy dependency in hdfsproxy and capacity-scheduler.
|
|
|
+ (Giridharan Kesavan via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5836. Bug in S3N handling of directory markers using an object with
|
|
|
+ a trailing "/" causes jobs to fail. (Ian Nowland via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-5861. s3n files are not getting split by default. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-5762. Fix a problem that DistCp does not copy empty directory.
|
|
|
+ (Rodrigo Schmidt via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5859. Fix "wait() or sleep() with locks held" findbugs warnings in
|
|
|
+ DFSClient. (Kan Zhang via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5457. Fix to continue to run builds even if contrib test fails
|
|
|
+ (Giridharan Kesavan via gkesavan)
|
|
|
+
|
|
|
+ HADOOP-5963. Remove an unnecessary exception catch in NNBench. (Boris
|
|
|
+ Shkolnik via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5989. Fix streaming test failure. (gkesavan)
|
|
|
+
|
|
|
+ HADOOP-5981. Fix a bug in HADOOP-2838 in parsing mapred.child.env.
|
|
|
+ (Amar Kamat via sharad)
|
|
|
+
|
|
|
+ HADOOP-5420. Fix LinuxTaskController to kill tasks using the process
|
|
|
+ groups they are launched with.
|
|
|
+ (Sreekanth Ramakrishnan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-6031. Remove @author tags from Java source files. (Ravi Phulari
|
|
|
+ via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5980. Fix LinuxTaskController so tasks get passed
|
|
|
+ LD_LIBRARY_PATH and other environment variables.
|
|
|
+ (Sreekanth Ramakrishnan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-4041. IsolationRunner does not work as documented.
|
|
|
+ (Philip Zeyliger via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6004. Fixes BlockLocation deserialization. (Jakob Homan via
|
|
|
+ szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6079. Serialize proxySource as DatanodeInfo in DataTransferProtocol.
|
|
|
+ (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6096. Fix Eclipse project and classpath files following project
|
|
|
+ split. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6122. The great than operator in test-patch.sh should be "-gt" but
|
|
|
+ not ">". (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6114. Fix javadoc documentation for FileStatus.getLen.
|
|
|
+ (Dmitry Rzhevskiy via dhruba)
|
|
|
+
|
|
|
+ HADOOP-6131. A sysproperty should not be set unless the property
|
|
|
+ is set on the ant command line in build.xml (hong tang via mahadev)
|
|
|
+
|
|
|
+ HADOOP-6137. Fix project specific test-patch requirements
|
|
|
+ (Giridharan Kesavan)
|
|
|
+
|
|
|
+ HADOOP-6138. Eliminate the deprecated warnings introduced by H-5438.
|
|
|
+ (He Yongqiang via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6132. RPC client create an extra connection because of incorrect
|
|
|
+ key for connection cache. (Kan Zhang via rangadi)
|
|
|
+
|
|
|
+ HADOOP-6123. Add missing classpaths in hadoop-config.sh. (Sharad Agarwal
|
|
|
+ via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6172. Fix jar file names in hadoop-config.sh and include
|
|
|
+ ${build.src} as a part of the source list in build.xml. (Hong Tang via
|
|
|
+ szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6124. Fix javac warning detection in test-patch.sh. (Giridharan
|
|
|
+ Kesavan via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6177. FSInputChecker.getPos() would return position greater
|
|
|
+ than the file size. (Hong Tang via hairong)
|
|
|
+
|
|
|
+ HADOOP-6188. TestTrash uses java.io.File api but not hadoop FileSystem api.
|
|
|
+ (Boris Shkolnik via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6192. Fix Shell.getUlimitMemoryCommand to not rely on Map-Reduce
|
|
|
+ specific configs. (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-6103. Clones the classloader as part of Configuration clone.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-6152. Fix classpath variables in bin/hadoop-config.sh and some
|
|
|
+ other scripts. (Aaron Kimball via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6215. fix GenericOptionParser to deal with -D with '=' in the
|
|
|
+ value. (Amar Kamat via sharad)
|
|
|
+
|
|
|
+ HADOOP-6227. Fix Configuration to allow final parameters to be set to null
|
|
|
+ and prevent them from being overridden.
|
|
|
+ (Amareshwari Sriramadasu via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-6199. Move io.map.skip.index property to core-default from mapred.
|
|
|
+ (Amareshwari Sriramadasu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6229. Attempt to make a directory under an existing file on
|
|
|
+ LocalFileSystem should throw an Exception. (Boris Shkolnik via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6243. Fix a NullPointerException in processing deprecated keys.
|
|
|
+ (Sreekanth Ramakrishnan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-6009. S3N listStatus incorrectly returns null instead of empty
|
|
|
+ array when called on empty root. (Ian Nowland via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6181. Fix .eclipse.templates/.classpath for avro and jets3t jar
|
|
|
+ files. (Carlos Valiente via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6196. Fix a bug in SequenceFile.Reader where syncing within the
|
|
|
+ header would cause the reader to read the sync marker as a record. (Jay
|
|
|
+ Booth via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6250. Modify test-patch to delete copied XML files before running
|
|
|
+ patch build. (Rahul Kumar Singh via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-6257. Two TestFileSystem classes are confusing
|
|
|
+ hadoop-hdfs-hdfwithmr. (Philip Zeyliger via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6151. Added a input filter to all of the http servlets that quotes
|
|
|
+ html characters in the parameters, to prevent cross site scripting
|
|
|
+ attacks. (omalley)
|
|
|
+
|
|
|
+ HADOOP-6274. Fix TestLocalFSFileContextMainOperations test failure.
|
|
|
+ (Gary Murry via suresh).
|
|
|
+
|
|
|
+ HADOOP-6281. Avoid null pointer exceptions when the jsps don't have
|
|
|
+ paramaters (omalley)
|
|
|
+
|
|
|
+ HADOOP-6285. Fix the result type of the getParameterMap method in the
|
|
|
+ HttpServer.QuotingInputFilter. (omalley)
|
|
|
+
|
|
|
+ HADOOP-6286. Fix bugs in related to URI handling in glob methods in
|
|
|
+ FileContext. (Boris Shkolnik via suresh)
|
|
|
+
|
|
|
+ HADOOP-6292. Update native libraries guide. (Corinne Chandel via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6327. FileContext tests should not use /tmp and should clean up
|
|
|
+ files. (Sanjay Radia via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6318. Upgrade to Avro 1.2.0. (cutting)
|
|
|
+
|
|
|
+ HADOOP-6334. Fix GenericOptionsParser to understand URI for -files,
|
|
|
+ -libjars and -archives options and fix Path to support URI with fragment.
|
|
|
+ (Amareshwari Sriramadasu via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6344. Fix rm and rmr immediately delete files rather than sending
|
|
|
+ to trash, if a user is over-quota. (Jakob Homan via suresh)
|
|
|
+
|
|
|
+ HADOOP-6347. run-test-core-fault-inject runs a test case twice if
|
|
|
+ -Dtestcase is set (cos)
|
|
|
+
|
|
|
+ HADOOP-6375. Sync documentation for FsShell du with its implementation.
|
|
|
+ (Todd Lipcon via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6441. Protect web ui from cross site scripting attacks (XSS) on
|
|
|
+ the host http header and using encoded utf-7. (omalley)
|
|
|
+
|
|
|
+ HADOOP-6451. Fix build to run contrib unit tests. (Tom White via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6374. JUnit tests should never depend on anything in conf.
|
|
|
+ (Anatoli Fomenko via cos)
|
|
|
+
|
|
|
+ HADOOP-6290. Prevent duplicate slf4j-simple jar via Avro's classpath.
|
|
|
+ (Owen O'Malley via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6293. Fix FsShell -text to work on filesystems other than the
|
|
|
+ default. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6341. Fix test-patch.sh for checkTests function. (gkesavan)
|
|
|
+
|
|
|
+ HADOOP-6314. Fix "fs -help" for the "-count" commond. (Ravi Phulari via
|
|
|
+ szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6405. Update Eclipse configuration to match changes to Ivy
|
|
|
+ configuration (Edwin Chan via cos)
|
|
|
+
|
|
|
+ HADOOP-6411. Remove deprecated file src/test/hadoop-site.xml. (cos)
|
|
|
+
|
|
|
+ HADOOP-6386. NameNode's HttpServer can't instantiate InetSocketAddress:
|
|
|
+ IllegalArgumentException is thrown (cos)
|
|
|
+
|
|
|
+ HADOOP-6254. Slow reads cause s3n to fail with SocketTimeoutException.
|
|
|
+ (Andrew Hitchcock via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6428. HttpServer sleeps with negative values. (cos)
|
|
|
+
|
|
|
+ HADOOP-6414. Add command line help for -expunge command.
|
|
|
+ (Ravi Phulari via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6391. Classpath should not be part of command line arguments.
|
|
|
+ (Cristian Ivascu via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6462. Target "compile" does not exist in contrib/cloud. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6402. testConf.xsl is not well-formed XML. (Steve Loughran
|
|
|
+ via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6489. Fix 3 findbugs warnings. (Erik Steffl via suresh)
|
|
|
+
|
|
|
+ HADOOP-6517. Fix UserGroupInformation so that tokens are saved/retrieved
|
|
|
+ to/from the embedded Subject (Owen O'Malley & Kan Zhang via ddas)
|
|
|
+
|
|
|
+ HADOOP-6538. Sets hadoop.security.authentication to simple by default.
|
|
|
+ (ddas)
|
|
|
+
|
|
|
+ HADOOP-6540. Contrib unit tests have invalid XML for core-site, etc.
|
|
|
+ (Aaron Kimball via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6521. User specified umask using deprecated dfs.umask must override
|
|
|
+ server configured using new dfs.umaskmode for backward compatibility.
|
|
|
+ (suresh)
|
|
|
+
|
|
|
+ HADOOP-6522. Fix decoding of codepoint zero in UTF8. (cutting)
|
|
|
+
|
|
|
+ HADOOP-6505. Use tr rather than sed to effect literal substitution in the
|
|
|
+ build script. (Allen Wittenauer via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6548. Replace mortbay imports with commons logging. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6560. Handle invalid har:// uri in HarFileSystem. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6549. TestDoAsEffectiveUser should use ip address of the host
|
|
|
+ for superuser ip check(jnp via boryas)
|
|
|
+
|
|
|
+ HADOOP-6570. RPC#stopProxy throws NPE if getProxyEngine(proxy) returns
|
|
|
+ null. (hairong)
|
|
|
+
|
|
|
+ HADOOP-6558. Return null in HarFileSystem.getFileChecksum(..) since no
|
|
|
+ checksum algorithm is implemented. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6572. Makes sure that SASL encryption and push to responder
|
|
|
+ queue for the RPC response happens atomically. (Kan Zhang via ddas)
|
|
|
+
|
|
|
+ HADOOP-6545. Changes the Key for the FileSystem cache to be UGI (ddas)
|
|
|
+
|
|
|
+ HADOOP-6609. Fixed deadlock in RPC by replacing shared static
|
|
|
+ DataOutputBuffer in the UTF8 class with a thread local variable. (omalley)
|
|
|
+
|
|
|
+ HADOOP-6504. Invalid example in the documentation of
|
|
|
+ org.apache.hadoop.util.Tool. (Benoit Sigoure via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6546. BloomMapFile can return false negatives. (Clark Jefcoat
|
|
|
+ via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6593. TextRecordInputStream doesn't close SequenceFile.Reader.
|
|
|
+ (Chase Bradford via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6175. Incorrect version compilation with es_ES.ISO8859-15 locale
|
|
|
+ on Solaris 10. (Urko Benito via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6645. Bugs on listStatus for HarFileSystem (rodrigo via mahadev)
|
|
|
+
|
|
|
+ HADOOP-6645. Re: Bugs on listStatus for HarFileSystem (rodrigo via
|
|
|
+ mahadev)
|
|
|
+
|
|
|
+ HADOOP-6654. Fix code example in WritableComparable javadoc. (Tom White
|
|
|
+ via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6640. FileSystem.get() does RPC retries within a static
|
|
|
+ synchronized block. (hairong)
|
|
|
+
|
|
|
+ HADOOP-6691. TestFileSystemCaching sometimes hangs. (hairong)
|
|
|
+
|
|
|
+ HADOOP-6507. Hadoop Common Docs - delete 3 doc files that do not belong
|
|
|
+ under Common. (Corinne Chandel via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6439. Fixes handling of deprecated keys to follow order in which
|
|
|
+ keys are defined. (V.V.Chaitanya Krishna via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-6690. FilterFileSystem correctly handles setTimes call.
|
|
|
+ (Rodrigo Schmidt via dhruba)
|
|
|
+
|
|
|
+ HADOOP-6703. Prevent renaming a file, directory or symbolic link to
|
|
|
+ itself. (Eli Collins via suresh)
|
|
|
+
|
|
|
+ HADOOP-6710. Symbolic umask for file creation is not conformant with posix.
|
|
|
+ (suresh)
|
|
|
+
|
|
|
+ HADOOP-6719. Insert all missing methods in FilterFs.
|
|
|
+ (Rodrigo Schmidt via dhruba)
|
|
|
+
|
|
|
+ HADOOP-6724. IPC doesn't properly handle IOEs thrown by socket factory.
|
|
|
+ (Todd Lipcon via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6722. NetUtils.connect should check that it hasn't connected a socket
|
|
|
+ to itself. (Todd Lipcon via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6634. Fix AccessControlList to use short names to verify access
|
|
|
+ control. (Vinod Kumar Vavilapalli via sharad)
|
|
|
+
|
|
|
+ HADOOP-6709. Re-instate deprecated FileSystem methods that were removed
|
|
|
+ after 0.20. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6630. hadoop-config.sh fails to get executed if hadoop wrapper
|
|
|
+ scripts are in path. (Allen Wittenauer via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6742. Add methods HADOOP-6709 from to TestFilterFileSystem.
|
|
|
+ (Eli Collins via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6727. Remove UnresolvedLinkException from public FileContext APIs.
|
|
|
+ (Eli Collins via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6631. Fix FileUtil.fullyDelete() to continue deleting other files
|
|
|
+ despite failure at any level. (Contributed by Ravi Gummadi and
|
|
|
+ Vinod Kumar Vavilapalli)
|
|
|
+
|
|
|
+ HADOOP-6723. Unchecked exceptions thrown in IPC Connection should not
|
|
|
+ orphan clients. (Todd Lipcon via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6404. Rename the generated artifacts to common instead of core.
|
|
|
+ (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6461. Webapps aren't located correctly post-split.
|
|
|
+ (Todd Lipcon and Steve Loughran via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6826. Revert FileSystem create method that takes CreateFlags.
|
|
|
+ (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6800. Harmonize JAR library versions. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-6847. Problem staging 0.21.0 artifacts to Apache Nexus Maven
|
|
|
+ Repository (Giridharan Kesavan via cos)
|
|
|
+
|
|
|
+ HADOOP-6819. [Herriot] Shell command for getting the new exceptions in
|
|
|
+ the logs returning exitcode 1 after executing successfully. (Vinay Thota
|
|
|
+ via cos)
|
|
|
+
|
|
|
+ HADOOP-6839. [Herriot] Implement a functionality for getting the user list
|
|
|
+ for creating proxy users. (Vinay Thota via cos)
|
|
|
+
|
|
|
+ HADOOP-6836. [Herriot]: Generic method for adding/modifying the attributes
|
|
|
+ for new configuration. (Vinay Thota via cos)
|
|
|
+
|
|
|
+ HADOOP-6860. 'compile-fault-inject' should never be called directly.
|
|
|
+ (Konstantin Boudnik)
|
|
|
+
|
|
|
+ HADOOP-6790. Instrumented (Herriot) build uses too wide mask to include
|
|
|
+ aspect files. (Konstantin Boudnik)
|
|
|
+
|
|
|
+ HADOOP-6875. [Herriot] Cleanup of temp. configurations is needed upon
|
|
|
+ restart of a cluster (Vinay Thota via cos)
|
|
|
+
|
|
|
+Release 0.20.3 - Unreleased
|
|
|
+
|
|
|
+ NEW FEATURES
|
|
|
+
|
|
|
+ HADOOP-6637. Benchmark for establishing RPC session. (shv)
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-6760. WebServer shouldn't increase port number in case of negative
|
|
|
+ port setting caused by Jetty's race (cos)
|
|
|
+
|
|
|
+ HADOOP-6881. Make WritableComparator intialize classes when
|
|
|
+ looking for their raw comparator, as classes often register raw
|
|
|
+ comparators in initializers, which are no longer automatically run
|
|
|
+ in Java 6 when a class is referenced. (cutting via omalley)
|
|
|
+
|
|
|
+ HADOOP-7072. Remove java5 dependencies from build. (cos)
|
|
|
+
|
|
|
+Release 0.20.204.0 - Unreleased
|
|
|
+
|
|
|
+ NEW FEATURES
|
|
|
+
|
|
|
+ HADOOP-6255. Create RPM and Debian packages for common. Changes deployment
|
|
|
+ layout to be consistent across the binary tgz, rpm, and deb. Adds setup
|
|
|
+ scripts for easy one node cluster configuration and user creation.
|
|
|
+ (Eric Yang via omalley)
|
|
|
+
|
|
|
+Release 0.20.203.0 - 2011-5-11
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-7258. The Gzip codec should not return null decompressors. (omalley)
|
|
|
+
|
|
|
+Release 0.20.2 - 2010-2-16
|
|
|
+
|
|
|
+ NEW FEATURES
|
|
|
+
|
|
|
+ HADOOP-6218. Adds a feature where TFile can be split by Record
|
|
|
+ Sequence number. (Hong Tang and Raghu Angadi via ddas)
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-6231. Allow caching of filesystem instances to be disabled on a
|
|
|
+ per-instance basis. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-5759. Fix for IllegalArgumentException when CombineFileInputFormat
|
|
|
+ is used as job InputFormat. (Amareshwari Sriramadasu via dhruba)
|
|
|
+
|
|
|
+ HADOOP-6097. Fix Path conversion in makeQualified and reset LineReader byte
|
|
|
+ count at the start of each block in Hadoop archives. (Ben Slusky, Tom
|
|
|
+ White, and Mahadev Konar via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6269. Fix threading issue with defaultResource in Configuration.
|
|
|
+ (Sreekanth Ramakrishnan via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6460. Reinitializes buffers used for serializing responses in ipc
|
|
|
+ server on exceeding maximum response size to free up Java heap. (suresh)
|
|
|
+
|
|
|
+ HADOOP-6315. Avoid incorrect use of BuiltInflater/BuiltInDeflater in
|
|
|
+ GzipCodec. (Aaron Kimball via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-6498. IPC client bug may cause rpc call hang. (Ruyue Ma and
|
|
|
+ hairong via hairong)
|
|
|
+
|
|
|
+ IMPROVEMENTS
|
|
|
+
|
|
|
+ HADOOP-5611. Fix C++ libraries to build on Debian Lenny. (Todd Lipcon
|
|
|
+ via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-5612. Some c++ scripts are not chmodded before ant execution.
|
|
|
+ (Todd Lipcon via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-1849. Add undocumented configuration parameter for per handler
|
|
|
+ call queue size in IPC Server. (shv)
|
|
|
+
|
|
|
+Release 0.20.1 - 2009-09-01
|
|
|
+
|
|
|
+ INCOMPATIBLE CHANGES
|
|
|
+
|
|
|
+ HADOOP-5726. Remove pre-emption from capacity scheduler code base.
|
|
|
+ (Rahul Kumar Singh via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5881. Simplify memory monitoring and scheduling related
|
|
|
+ configuration. (Vinod Kumar Vavilapalli via yhemanth)
|
|
|
+
|
|
|
+ NEW FEATURES
|
|
|
+
|
|
|
+ HADOOP-6080. Introduce -skipTrash option to rm and rmr.
|
|
|
+ (Jakob Homan via shv)
|
|
|
+
|
|
|
+ HADOOP-3315. Add a new, binary file foramt, TFile. (Hong Tang via cdouglas)
|
|
|
+
|
|
|
+ IMPROVEMENTS
|
|
|
+
|
|
|
+ HADOOP-5711. Change Namenode file close log to info. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5736. Update the capacity scheduler documentation for features
|
|
|
+ like memory based scheduling, job initialization and removal of pre-emption.
|
|
|
+ (Sreekanth Ramakrishnan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5714. Add a metric for NameNode getFileInfo operation. (Jakob Homan
|
|
|
+ via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4372. Improves the way history filenames are obtained and manipulated.
|
|
|
+ (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-5897. Add name-node metrics to capture java heap usage.
|
|
|
+ (Suresh Srinivas via shv)
|
|
|
+
|
|
|
+ OPTIMIZATIONS
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-5691. Makes org.apache.hadoop.mapreduce.Reducer concrete class
|
|
|
+ instead of abstract. (Amareshwari Sriramadasu via sharad)
|
|
|
+
|
|
|
+ HADOOP-5646. Fixes a problem in TestQueueCapacities.
|
|
|
+ (Vinod Kumar Vavilapalli via ddas)
|
|
|
+
|
|
|
+ HADOOP-5655. TestMRServerPorts fails on java.net.BindException. (Devaraj
|
|
|
+ Das via hairong)
|
|
|
+
|
|
|
+ HADOOP-5654. TestReplicationPolicy.<init> fails on java.net.BindException.
|
|
|
+ (hairong)
|
|
|
+
|
|
|
+ HADOOP-5688. Fix HftpFileSystem checksum path construction. (Tsz Wo
|
|
|
+ (Nicholas) Sze via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4674. Fix fs help messages for -test, -text, -tail, -stat
|
|
|
+ and -touchz options. (Ravi Phulari via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5718. Remove the check for the default queue in capacity scheduler.
|
|
|
+ (Sreekanth Ramakrishnan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5719. Remove jobs that failed initialization from the waiting queue
|
|
|
+ in the capacity scheduler. (Sreekanth Ramakrishnan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-4744. Attaching another fix to the jetty port issue. The TaskTracker
|
|
|
+ kills itself if it ever discovers that the port to which jetty is actually
|
|
|
+ bound is invalid (-1). (ddas)
|
|
|
+
|
|
|
+ HADOOP-5349. Fixes a problem in LocalDirAllocator to check for the return
|
|
|
+ path value that is returned for the case where the file we want to write
|
|
|
+ is of an unknown size. (Vinod Kumar Vavilapalli via ddas)
|
|
|
+
|
|
|
+ HADOOP-5636. Prevents a job from going to RUNNING state after it has been
|
|
|
+ KILLED (this used to happen when the SetupTask would come back with a
|
|
|
+ success after the job has been killed). (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-5641. Fix a NullPointerException in capacity scheduler's memory
|
|
|
+ based scheduling code when jobs get retired. (yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5828. Use absolute path for mapred.local.dir of JobTracker in
|
|
|
+ MiniMRCluster. (yhemanth)
|
|
|
+
|
|
|
+ HADOOP-4981. Fix capacity scheduler to schedule speculative tasks
|
|
|
+ correctly in the presence of High RAM jobs.
|
|
|
+ (Sreekanth Ramakrishnan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5210. Solves a problem in the progress report of the reduce task.
|
|
|
+ (Ravi Gummadi via ddas)
|
|
|
+
|
|
|
+ HADOOP-5850. Fixes a problem to do with not being able to jobs with
|
|
|
+ 0 maps/reduces. (Vinod K V via ddas)
|
|
|
+
|
|
|
+ HADOOP-4626. Correct the API links in hdfs forrest doc so that they
|
|
|
+ point to the same version of hadoop. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5883. Fixed tasktracker memory monitoring to account for
|
|
|
+ momentary spurts in memory usage due to java's fork() model.
|
|
|
+ (yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5539. Fixes a problem to do with not preserving intermediate
|
|
|
+ output compression for merged data.
|
|
|
+ (Jothi Padmanabhan and Billy Pearson via ddas)
|
|
|
+
|
|
|
+ HADOOP-5932. Fixes a problem in capacity scheduler in computing
|
|
|
+ available memory on a tasktracker.
|
|
|
+ (Vinod Kumar Vavilapalli via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5908. Fixes a problem to do with ArithmeticException in the
|
|
|
+ JobTracker when there are jobs with 0 maps. (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-5924. Fixes a corner case problem to do with job recovery with
|
|
|
+ empty history files. Also, after a JT restart, sends KillTaskAction to
|
|
|
+ tasks that report back but the corresponding job hasn't been initialized
|
|
|
+ yet. (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-5882. Fixes a reducer progress update problem for new mapreduce
|
|
|
+ api. (Amareshwari Sriramadasu via sharad)
|
|
|
+
|
|
|
+ HADOOP-5746. Fixes a corner case problem in Streaming, where if an exception
|
|
|
+ happens in MROutputThread after the last call to the map/reduce method, the
|
|
|
+ exception goes undetected. (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-5884. Fixes accounting in capacity scheduler so that high RAM jobs
|
|
|
+ take more slots. (Vinod Kumar Vavilapalli via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5937. Correct a safemode message in FSNamesystem. (Ravi Phulari
|
|
|
+ via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5869. Fix bug in assignment of setup / cleanup task that was
|
|
|
+ causing TestQueueCapacities to fail.
|
|
|
+ (Sreekanth Ramakrishnan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5921. Fixes a problem in the JobTracker where it sometimes never used
|
|
|
+ to come up due to a system file creation on JobTracker's system-dir failing.
|
|
|
+ This problem would sometimes show up only when the FS for the system-dir
|
|
|
+ (usually HDFS) is started at nearly the same time as the JobTracker.
|
|
|
+ (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-5920. Fixes a testcase failure for TestJobHistory.
|
|
|
+ (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-6139. Fix the FsShell help messages for rm and rmr. (Jakob Homan
|
|
|
+ via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6145. Fix FsShell rm/rmr error messages when there is a FNFE.
|
|
|
+ (Jakob Homan via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-6150. Users should be able to instantiate comparator using TFile
|
|
|
+ API. (Hong Tang via rangadi)
|
|
|
+
|
|
|
+Release 0.20.0 - 2009-04-15
|
|
|
+
|
|
|
+ INCOMPATIBLE CHANGES
|
|
|
+
|
|
|
+ HADOOP-4210. Fix findbugs warnings for equals implementations of mapred ID
|
|
|
+ classes. Removed public, static ID::read and ID::forName; made ID an
|
|
|
+ abstract class. (Suresh Srinivas via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4253. Fix various warnings generated by findbugs.
|
|
|
+ Following deprecated methods in RawLocalFileSystem are removed:
|
|
|
+ public String getName()
|
|
|
+ public void lock(Path p, boolean shared)
|
|
|
+ public void release(Path p)
|
|
|
+ (Suresh Srinivas via johan)
|
|
|
+
|
|
|
+ HADOOP-4618. Move http server from FSNamesystem into NameNode.
|
|
|
+ FSNamesystem.getNameNodeInfoPort() is removed.
|
|
|
+ FSNamesystem.getDFSNameNodeMachine() and FSNamesystem.getDFSNameNodePort()
|
|
|
+ replaced by FSNamesystem.getDFSNameNodeAddress().
|
|
|
+ NameNode(bindAddress, conf) is removed.
|
|
|
+ (shv)
|
|
|
+
|
|
|
+ HADOOP-4567. GetFileBlockLocations returns the NetworkTopology
|
|
|
+ information of the machines where the blocks reside. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-4435. The JobTracker WebUI displays the amount of heap memory
|
|
|
+ in use. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-4628. Move Hive into a standalone subproject. (omalley)
|
|
|
+
|
|
|
+ HADOOP-4188. Removes task's dependency on concrete filesystems.
|
|
|
+ (Sharad Agarwal via ddas)
|
|
|
+
|
|
|
+ HADOOP-1650. Upgrade to Jetty 6. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3986. Remove static Configuration from JobClient. (Amareshwari
|
|
|
+ Sriramadasu via cdouglas)
|
|
|
+ JobClient::setCommandLineConfig is removed
|
|
|
+ JobClient::getCommandLineConfig is removed
|
|
|
+ JobShell, TestJobShell classes are removed
|
|
|
+
|
|
|
+ HADOOP-4422. S3 file systems should not create bucket.
|
|
|
+ (David Phillips via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-4035. Support memory based scheduling in capacity scheduler.
|
|
|
+ (Vinod Kumar Vavilapalli via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-3497. Fix bug in overly restrictive file globbing with a
|
|
|
+ PathFilter. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-4445. Replace running task counts with running task
|
|
|
+ percentage in capacity scheduler UI. (Sreekanth Ramakrishnan via
|
|
|
+ yhemanth)
|
|
|
+
|
|
|
+ HADOOP-4631. Splits the configuration into three parts - one for core,
|
|
|
+ one for mapred and the last one for HDFS. (Sharad Agarwal via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3344. Fix libhdfs build to use autoconf and build the same
|
|
|
+ architecture (32 vs 64 bit) of the JVM running Ant. The libraries for
|
|
|
+ pipes, utils, and libhdfs are now all in c++/<os_osarch_jvmdatamodel>/lib.
|
|
|
+ (Giridharan Kesavan via nigel)
|
|
|
+
|
|
|
+ HADOOP-4874. Remove LZO codec because of licensing issues. (omalley)
|
|
|
+
|
|
|
+ HADOOP-4970. The full path name of a file is preserved inside Trash.
|
|
|
+ (Prasad Chakka via dhruba)
|
|
|
+
|
|
|
+ HADOOP-4103. NameNode keeps a count of missing blocks. It warns on
|
|
|
+ WebUI if there are such blocks. '-report' and '-metaSave' have extra
|
|
|
+ info to track such blocks. (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-4783. Change permissions on history files on the jobtracker
|
|
|
+ to be only group readable instead of world readable.
|
|
|
+ (Amareshwari Sriramadasu via yhemanth)
|
|
|
+
|
|
|
+ NEW FEATURES
|
|
|
+
|
|
|
+ HADOOP-4575. Add a proxy service for relaying HsftpFileSystem requests.
|
|
|
+ Includes client authentication via user certificates and config-based
|
|
|
+ access control. (Kan Zhang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4661. Add DistCh, a new tool for distributed ch{mod,own,grp}.
|
|
|
+ (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4709. Add several new features and bug fixes to Chukwa.
|
|
|
+ Added Hadoop Infrastructure Care Center (UI for visualize data collected
|
|
|
+ by Chukwa)
|
|
|
+ Added FileAdaptor for streaming small file in one chunk
|
|
|
+ Added compression to archive and demux output
|
|
|
+ Added unit tests and validation for agent, collector, and demux map
|
|
|
+ reduce job
|
|
|
+ Added database loader for loading demux output (sequence file) to jdbc
|
|
|
+ connected database
|
|
|
+ Added algorithm to distribute collector load more evenly
|
|
|
+ (Jerome Boulon, Eric Yang, Andy Konwinski, Ariel Rabkin via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4179. Add Vaidya tool to analyze map/reduce job logs for performanc
|
|
|
+ problems. (Suhas Gogate via omalley)
|
|
|
+
|
|
|
+ HADOOP-4029. Add NameNode storage information to the dfshealth page and
|
|
|
+ move DataNode information to a separated page. (Boris Shkolnik via
|
|
|
+ szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4348. Add service-level authorization for Hadoop. (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4826. Introduce admin command saveNamespace. (shv)
|
|
|
+
|
|
|
+ HADOOP-3063 BloomMapFile - fail-fast version of MapFile for sparsely
|
|
|
+ populated key space (Andrzej Bialecki via stack)
|
|
|
+
|
|
|
+ HADOOP-1230. Add new map/reduce API and deprecate the old one. Generally,
|
|
|
+ the old code should work without problem. The new api is in
|
|
|
+ org.apache.hadoop.mapreduce and the old classes in org.apache.hadoop.mapred
|
|
|
+ are deprecated. Differences in the new API:
|
|
|
+ 1. All of the methods take Context objects that allow us to add new
|
|
|
+ methods without breaking compatability.
|
|
|
+ 2. Mapper and Reducer now have a "run" method that is called once and
|
|
|
+ contains the control loop for the task, which lets applications
|
|
|
+ replace it.
|
|
|
+ 3. Mapper and Reducer by default are Identity Mapper and Reducer.
|
|
|
+ 4. The FileOutputFormats use part-r-00000 for the output of reduce 0 and
|
|
|
+ part-m-00000 for the output of map 0.
|
|
|
+ 5. The reduce grouping comparator now uses the raw compare instead of
|
|
|
+ object compare.
|
|
|
+ 6. The number of maps in FileInputFormat is controlled by min and max
|
|
|
+ split size rather than min size and the desired number of maps.
|
|
|
+ (omalley)
|
|
|
+
|
|
|
+ HADOOP-3305. Use Ivy to manage dependencies. (Giridharan Kesavan
|
|
|
+ and Steve Loughran via cutting)
|
|
|
+
|
|
|
+ IMPROVEMENTS
|
|
|
+
|
|
|
+ HADOOP-4749. Added a new counter REDUCE_INPUT_BYTES. (Yongqiang He via
|
|
|
+ zshao)
|
|
|
+
|
|
|
+ HADOOP-4234. Fix KFS "glue" layer to allow applications to interface
|
|
|
+ with multiple KFS metaservers. (Sriram Rao via lohit)
|
|
|
+
|
|
|
+ HADOOP-4245. Update to latest version of KFS "glue" library jar.
|
|
|
+ (Sriram Rao via lohit)
|
|
|
+
|
|
|
+ HADOOP-4244. Change test-patch.sh to check Eclipse classpath no matter
|
|
|
+ it is run by Hudson or not. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-3180. Add name of missing class to WritableName.getClass
|
|
|
+ IOException. (Pete Wyckoff via omalley)
|
|
|
+
|
|
|
+ HADOOP-4178. Make the capacity scheduler's default values configurable.
|
|
|
+ (Sreekanth Ramakrishnan via omalley)
|
|
|
+
|
|
|
+ HADOOP-4262. Generate better error message when client exception has null
|
|
|
+ message. (stevel via omalley)
|
|
|
+
|
|
|
+ HADOOP-4226. Refactor and document LineReader to make it more readily
|
|
|
+ understandable. (Yuri Pradkin via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4238. When listing jobs, if scheduling information isn't available
|
|
|
+ print NA instead of empty output. (Sreekanth Ramakrishnan via johan)
|
|
|
+
|
|
|
+ HADOOP-4284. Support filters that apply to all requests, or global filters,
|
|
|
+ to HttpServer. (Kan Zhang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4276. Improve the hashing functions and deserialization of the
|
|
|
+ mapred ID classes. (omalley)
|
|
|
+
|
|
|
+ HADOOP-4485. Add a compile-native ant task, as a shorthand. (enis)
|
|
|
+
|
|
|
+ HADOOP-4454. Allow # comments in slaves file. (Rama Ramasamy via omalley)
|
|
|
+
|
|
|
+ HADOOP-3461. Remove hdfs.StringBytesWritable. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4437. Use Halton sequence instead of java.util.Random in
|
|
|
+ PiEstimator. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4572. Change INode and its sub-classes to package private.
|
|
|
+ (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4187. Does a runtime lookup for JobConf/JobConfigurable, and if
|
|
|
+ found, invokes the appropriate configure method. (Sharad Agarwal via ddas)
|
|
|
+
|
|
|
+ HADOOP-4453. Improve ssl configuration and handling in HsftpFileSystem,
|
|
|
+ particularly when used with DistCp. (Kan Zhang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4583. Several code optimizations in HDFS. (Suresh Srinivas via
|
|
|
+ szetszwo)
|
|
|
+
|
|
|
+ HADOOP-3923. Remove org.apache.hadoop.mapred.StatusHttpServer. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4622. Explicitly specify interpretor for non-native
|
|
|
+ pipes binaries. (Fredrik Hedberg via johan)
|
|
|
+
|
|
|
+ HADOOP-4505. Add a unit test to test faulty setup task and cleanup
|
|
|
+ task killing the job. (Amareshwari Sriramadasu via johan)
|
|
|
+
|
|
|
+ HADOOP-4608. Don't print a stack trace when the example driver gets an
|
|
|
+ unknown program to run. (Edward Yoon via omalley)
|
|
|
+
|
|
|
+ HADOOP-4645. Package HdfsProxy contrib project without the extra level
|
|
|
+ of directories. (Kan Zhang via omalley)
|
|
|
+
|
|
|
+ HADOOP-4126. Allow access to HDFS web UI on EC2 (tomwhite via omalley)
|
|
|
+
|
|
|
+ HADOOP-4612. Removes RunJar's dependency on JobClient.
|
|
|
+ (Sharad Agarwal via ddas)
|
|
|
+
|
|
|
+ HADOOP-4185. Adds setVerifyChecksum() method to FileSystem.
|
|
|
+ (Sharad Agarwal via ddas)
|
|
|
+
|
|
|
+ HADOOP-4523. Prevent too many tasks scheduled on a node from bringing
|
|
|
+ it down by monitoring for cumulative memory usage across tasks.
|
|
|
+ (Vinod Kumar Vavilapalli via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-4640. Adds an input format that can split lzo compressed
|
|
|
+ text files. (johan)
|
|
|
+
|
|
|
+ HADOOP-4666. Launch reduces only after a few maps have run in the
|
|
|
+ Fair Scheduler. (Matei Zaharia via johan)
|
|
|
+
|
|
|
+ HADOOP-4339. Remove redundant calls from FileSystem/FsShell when
|
|
|
+ generating/processing ContentSummary. (David Phillips via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2774. Add counters tracking records spilled to disk in MapTask and
|
|
|
+ ReduceTask. (Ravi Gummadi via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4513. Initialize jobs asynchronously in the capacity scheduler.
|
|
|
+ (Sreekanth Ramakrishnan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-4649. Improve abstraction for spill indices. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3770. Add gridmix2, an iteration on the gridmix benchmark. (Runping
|
|
|
+ Qi via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4708. Add support for dfsadmin commands in TestCLI. (Boris Shkolnik
|
|
|
+ via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4758. Add a splitter for metrics contexts to support more than one
|
|
|
+ type of collector. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4722. Add tests for dfsadmin quota error messages. (Boris Shkolnik
|
|
|
+ via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4690. fuse-dfs - create source file/function + utils + config +
|
|
|
+ main source files. (pete wyckoff via mahadev)
|
|
|
+
|
|
|
+ HADOOP-3750. Fix and enforce module dependencies. (Sharad Agarwal via
|
|
|
+ tomwhite)
|
|
|
+
|
|
|
+ HADOOP-4747. Speed up FsShell::ls by removing redundant calls to the
|
|
|
+ filesystem. (David Phillips via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4305. Improves the blacklisting strategy, whereby, tasktrackers
|
|
|
+ that are blacklisted are not given tasks to run from other jobs, subject
|
|
|
+ to the following conditions (all must be met):
|
|
|
+ 1) The TaskTracker has been blacklisted by at least 4 jobs (configurable)
|
|
|
+ 2) The TaskTracker has been blacklisted 50% more number of times than
|
|
|
+ the average (configurable)
|
|
|
+ 3) The cluster has less than 50% trackers blacklisted
|
|
|
+ Once in 24 hours, a TaskTracker blacklisted for all jobs is given a chance.
|
|
|
+ Restarting the TaskTracker moves it out of the blacklist.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-4688. Modify the MiniMRDFSSort unit test to spill multiple times,
|
|
|
+ exercising the map-side merge code. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4737. Adds the KILLED notification when jobs get killed.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-4728. Add a test exercising different namenode configurations.
|
|
|
+ (Boris Shkolnik via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4807. Adds JobClient commands to get the active/blacklisted tracker
|
|
|
+ names. Also adds commands to display running/completed task attempt IDs.
|
|
|
+ (ddas)
|
|
|
+
|
|
|
+ HADOOP-4699. Remove checksum validation from map output servlet. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4838. Added a registry to automate metrics and mbeans management.
|
|
|
+ (Sanjay Radia via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-3136. Fixed the default scheduler to assign multiple tasks to each
|
|
|
+ tasktracker per heartbeat, when feasible. To ensure locality isn't hurt
|
|
|
+ too badly, the scheudler will not assign more than one off-switch task per
|
|
|
+ heartbeat. The heartbeat interval is also halved since the task-tracker is
|
|
|
+ fixed to no longer send out heartbeats on each task completion. A
|
|
|
+ slow-start for scheduling reduces is introduced to ensure that reduces
|
|
|
+ aren't started till sufficient number of maps are done, else reduces of
|
|
|
+ jobs whose maps aren't scheduled might swamp the cluster.
|
|
|
+ Configuration changes to mapred-default.xml:
|
|
|
+ add mapred.reduce.slowstart.completed.maps
|
|
|
+ (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4545. Add example and test case of secondary sort for the reduce.
|
|
|
+ (omalley)
|
|
|
+
|
|
|
+ HADOOP-4753. Refactor gridmix2 to reduce code duplication. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4909. Fix Javadoc and make some of the API more consistent in their
|
|
|
+ use of the JobContext instead of Configuration. (omalley)
|
|
|
+
|
|
|
+ HADOOP-4920. Stop storing Forrest output in Subversion. (cutting)
|
|
|
+
|
|
|
+ HADOOP-4948. Add parameters java5.home and forrest.home to the ant commands
|
|
|
+ in test-patch.sh. (Giridharan Kesavan via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4830. Add end-to-end test cases for testing queue capacities.
|
|
|
+ (Vinod Kumar Vavilapalli via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-4980. Improve code layout of capacity scheduler to make it
|
|
|
+ easier to fix some blocker bugs. (Vivek Ratan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-4916. Make user/location of Chukwa installation configurable by an
|
|
|
+ external properties file. (Eric Yang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4950. Make the CompressorStream, DecompressorStream,
|
|
|
+ BlockCompressorStream, and BlockDecompressorStream public to facilitate
|
|
|
+ non-Hadoop codecs. (omalley)
|
|
|
+
|
|
|
+ HADOOP-4843. Collect job history and configuration in Chukwa. (Eric Yang
|
|
|
+ via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5030. Build Chukwa RPM to install into configured directory. (Eric
|
|
|
+ Yang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4828. Updates documents to do with configuration (HADOOP-4631).
|
|
|
+ (Sharad Agarwal via ddas)
|
|
|
+
|
|
|
+ HADOOP-4939. Adds a test that would inject random failures for tasks in
|
|
|
+ large jobs and would also inject TaskTracker failures. (ddas)
|
|
|
+
|
|
|
+ HADOOP-4944. A configuration file can include other configuration
|
|
|
+ files. (Rama Ramasamy via dhruba)
|
|
|
+
|
|
|
+ HADOOP-4804. Provide Forrest documentation for the Fair Scheduler.
|
|
|
+ (Sreekanth Ramakrishnan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5248. A testcase that checks for the existence of job directory
|
|
|
+ after the job completes. Fails if it exists. (ddas)
|
|
|
+
|
|
|
+ HADOOP-4664. Introduces multiple job initialization threads, where the
|
|
|
+ number of threads are configurable via mapred.jobinit.threads.
|
|
|
+ (Matei Zaharia and Jothi Padmanabhan via ddas)
|
|
|
+
|
|
|
+ HADOOP-4191. Adds a testcase for JobHistory. (Ravi Gummadi via ddas)
|
|
|
+
|
|
|
+ HADOOP-5466. Change documenation CSS style for headers and code. (Corinne
|
|
|
+ Chandel via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5275. Add ivy directory and files to built tar.
|
|
|
+ (Giridharan Kesavan via nigel)
|
|
|
+
|
|
|
+ HADOOP-5468. Add sub-menus to forrest documentation and make some minor
|
|
|
+ edits. (Corinne Chandel via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5437. Fix TestMiniMRDFSSort to properly test jvm-reuse. (omalley)
|
|
|
+
|
|
|
+ HADOOP-5521. Removes dependency of TestJobInProgress on RESTART_COUNT
|
|
|
+ JobHistory tag. (Ravi Gummadi via ddas)
|
|
|
+
|
|
|
+ OPTIMIZATIONS
|
|
|
+
|
|
|
+ HADOOP-3293. Fixes FileInputFormat to do provide locations for splits
|
|
|
+ based on the rack/host that has the most number of bytes.
|
|
|
+ (Jothi Padmanabhan via ddas)
|
|
|
+
|
|
|
+ HADOOP-4683. Fixes Reduce shuffle scheduler to invoke
|
|
|
+ getMapCompletionEvents in a separate thread. (Jothi Padmanabhan
|
|
|
+ via ddas)
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-4204. Fix findbugs warnings related to unused variables, naive
|
|
|
+ Number subclass instantiation, Map iteration, and badly scoped inner
|
|
|
+ classes. (Suresh Srinivas via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4207. Update derby jar file to release 10.4.2 release.
|
|
|
+ (Prasad Chakka via dhruba)
|
|
|
+
|
|
|
+ HADOOP-4325. SocketInputStream.read() should return -1 in case EOF.
|
|
|
+ (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-4408. FsAction functions need not create new objects. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4440. TestJobInProgressListener tests for jobs killed in queued
|
|
|
+ state (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-4346. Implement blocking connect so that Hadoop is not affected
|
|
|
+ by selector problem with JDK default implementation. (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-4388. If there are invalid blocks in the transfer list, Datanode
|
|
|
+ should handle them and keep transferring the remaining blocks. (Suresh
|
|
|
+ Srinivas via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4587. Fix a typo in Mapper javadoc. (Koji Noguchi via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4530. In fsck, HttpServletResponse sendError fails with
|
|
|
+ IllegalStateException. (hairong)
|
|
|
+
|
|
|
+ HADOOP-4377. Fix a race condition in directory creation in
|
|
|
+ NativeS3FileSystem. (David Phillips via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4621. Fix javadoc warnings caused by duplicate jars. (Kan Zhang via
|
|
|
+ cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4566. Deploy new hive code to support more types.
|
|
|
+ (Zheng Shao via dhruba)
|
|
|
+
|
|
|
+ HADOOP-4571. Add chukwa conf files to svn:ignore list. (Eric Yang via
|
|
|
+ szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4589. Correct PiEstimator output messages and improve the code
|
|
|
+ readability. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4650. Correct a mismatch between the default value of
|
|
|
+ local.cache.size in the config and the source. (Jeff Hammerbacher via
|
|
|
+ cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4606. Fix cygpath error if the log directory does not exist.
|
|
|
+ (szetszwo via omalley)
|
|
|
+
|
|
|
+ HADOOP-4141. Fix bug in ScriptBasedMapping causing potential infinite
|
|
|
+ loop on misconfigured hadoop-site. (Aaron Kimball via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-4691. Correct a link in the javadoc of IndexedSortable. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4598. '-setrep' command skips under-replicated blocks. (hairong)
|
|
|
+
|
|
|
+ HADOOP-4429. Set defaults for user, group in UnixUserGroupInformation so
|
|
|
+ login fails more predictably when misconfigured. (Alex Loddengaard via
|
|
|
+ cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4676. Fix broken URL in blacklisted tasktrackers page. (Amareshwari
|
|
|
+ Sriramadasu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3422 Ganglia counter metrics are all reported with the metric
|
|
|
+ name "value", so the counter values can not be seen. (Jason Attributor
|
|
|
+ and Brian Bockelman via stack)
|
|
|
+
|
|
|
+ HADOOP-4704. Fix javadoc typos "the the". (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4677. Fix semantics of FileSystem::getBlockLocations to return
|
|
|
+ meaningful values. (Hong Tang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4669. Use correct operator when evaluating whether access time is
|
|
|
+ enabled (Dhruba Borthakur via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4732. Pass connection and read timeouts in the correct order when
|
|
|
+ setting up fetch in reduce. (Amareshwari Sriramadasu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4558. Fix capacity reclamation in capacity scheduler.
|
|
|
+ (Amar Kamat via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-4770. Fix rungridmix_2 script to work with RunJar. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4738. When using git, the saveVersion script will use only the
|
|
|
+ commit hash for the version and not the message, which requires escaping.
|
|
|
+ (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4576. Show pending job count instead of task count in the UI per
|
|
|
+ queue in capacity scheduler. (Sreekanth Ramakrishnan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-4623. Maintain running tasks even if speculative execution is off.
|
|
|
+ (Amar Kamat via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-4786. Fix broken compilation error in
|
|
|
+ TestTrackerBlacklistAcrossJobs. (yhemanth)
|
|
|
+
|
|
|
+ HADOOP-4785. Fixes theJobTracker heartbeat to not make two calls to
|
|
|
+ System.currentTimeMillis(). (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-4792. Add generated Chukwa configuration files to version control
|
|
|
+ ignore lists. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4796. Fix Chukwa test configuration, remove unused components. (Eric
|
|
|
+ Yang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4708. Add binaries missed in the initial checkin for Chukwa. (Eric
|
|
|
+ Yang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4805. Remove black list collector from Chukwa Agent HTTP Sender.
|
|
|
+ (Eric Yang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4837. Move HADOOP_CONF_DIR configuration to chukwa-env.sh (Jerome
|
|
|
+ Boulon via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4825. Use ps instead of jps for querying process status in Chukwa.
|
|
|
+ (Eric Yang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4844. Fixed javadoc for
|
|
|
+ org.apache.hadoop.fs.permission.AccessControlException to document that
|
|
|
+ it's deprecated in favour of
|
|
|
+ org.apache.hadoop.security.AccessControlException. (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4706. Close the underlying output stream in
|
|
|
+ IFileOutputStream::close. (Jothi Padmanabhan via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4855. Fixed command-specific help messages for refreshServiceAcl in
|
|
|
+ DFSAdmin and MRAdmin. (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4820. Remove unused method FSNamesystem::deleteInSafeMode. (Suresh
|
|
|
+ Srinivas via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4698. Lower io.sort.mb to 10 in the tests and raise the junit memory
|
|
|
+ limit to 512m from 256m. (Nigel Daley via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4860. Split TestFileTailingAdapters into three separate tests to
|
|
|
+ avoid contention. (Eric Yang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3921. Fixed clover (code coverage) target to work with JDK 6.
|
|
|
+ (tomwhite via nigel)
|
|
|
+
|
|
|
+ HADOOP-4845. Modify the reduce input byte counter to record only the
|
|
|
+ compressed size and add a human-readable label. (Yongqiang He via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4458. Add a test creating symlinks in the working directory.
|
|
|
+ (Amareshwari Sriramadasu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4879. Fix org.apache.hadoop.mapred.Counters to correctly define
|
|
|
+ Object.equals rather than depend on contentEquals api. (omalley via
|
|
|
+ acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4791. Fix rpm build process for Chukwa. (Eric Yang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4771. Correct initialization of the file count for directories
|
|
|
+ with quotas. (Ruyue Ma via shv)
|
|
|
+
|
|
|
+ HADOOP-4878. Fix eclipse plugin classpath file to point to ivy's resolved
|
|
|
+ lib directory and added the same to test-patch.sh. (Giridharan Kesavan via
|
|
|
+ acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4774. Fix default values of some capacity scheduler configuration
|
|
|
+ items which would otherwise not work on a fresh checkout.
|
|
|
+ (Sreekanth Ramakrishnan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-4876. Fix capacity scheduler reclamation by updating count of
|
|
|
+ pending tasks correctly. (Sreekanth Ramakrishnan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-4849. Documentation for Service Level Authorization implemented in
|
|
|
+ HADOOP-4348. (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4827. Replace Consolidator with Aggregator macros in Chukwa (Eric
|
|
|
+ Yang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4894. Correctly parse ps output in Chukwa jettyCollector.sh. (Ari
|
|
|
+ Rabkin via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4892. Close fds out of Chukwa ExecPlugin. (Ari Rabkin via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4889. Fix permissions in RPM packaging. (Eric Yang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4869. Fixes the TT-JT heartbeat to have an explicit flag for
|
|
|
+ restart apart from the initialContact flag that there was earlier.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-4716. Fixes ReduceTask.java to clear out the mapping between
|
|
|
+ hosts and MapOutputLocation upon a JT restart (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-4880. Removes an unnecessary testcase from TestJobTrackerRestart.
|
|
|
+ (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-4924. Fixes a race condition in TaskTracker re-init. (ddas)
|
|
|
+
|
|
|
+ HADOOP-4854. Read reclaim capacity interval from capacity scheduler
|
|
|
+ configuration. (Sreekanth Ramakrishnan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-4896. HDFS Fsck does not load HDFS configuration. (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-4956. Creates TaskStatus for failed tasks with an empty Counters
|
|
|
+ object instead of null. (ddas)
|
|
|
+
|
|
|
+ HADOOP-4979. Fix capacity scheduler to block cluster for failed high
|
|
|
+ RAM requirements across task types. (Vivek Ratan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-4949. Fix native compilation. (Chris Douglas via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4787. Fixes the testcase TestTrackerBlacklistAcrossJobs which was
|
|
|
+ earlier failing randomly. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-4914. Add description fields to Chukwa init.d scripts (Eric Yang via
|
|
|
+ cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4884. Make tool tip date format match standard HICC format. (Eric
|
|
|
+ Yang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4925. Make Chukwa sender properties configurable. (Ari Rabkin via
|
|
|
+ cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4947. Make Chukwa command parsing more forgiving of whitespace. (Ari
|
|
|
+ Rabkin via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5026. Make chukwa/bin scripts executable in repository. (Andy
|
|
|
+ Konwinski via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4977. Fix a deadlock between the reclaimCapacity and assignTasks
|
|
|
+ in capacity scheduler. (Vivek Ratan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-4988. Fix reclaim capacity to work even when there are queues with
|
|
|
+ no capacity. (Vivek Ratan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5065. Remove generic parameters from argument to
|
|
|
+ setIn/OutputFormatClass so that it works with SequenceIn/OutputFormat.
|
|
|
+ (cdouglas via omalley)
|
|
|
+
|
|
|
+ HADOOP-4818. Pass user config to instrumentation API. (Eric Yang via
|
|
|
+ cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4993. Fix Chukwa agent configuration and startup to make it both
|
|
|
+ more modular and testable. (Ari Rabkin via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5048. Fix capacity scheduler to correctly cleanup jobs that are
|
|
|
+ killed after initialization, but before running.
|
|
|
+ (Sreekanth Ramakrishnan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-4671. Mark loop control variables shared between threads as
|
|
|
+ volatile. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5079. HashFunction inadvertently destroys some randomness
|
|
|
+ (Jonathan Ellis via stack)
|
|
|
+
|
|
|
+ HADOOP-4999. A failure to write to FsEditsLog results in
|
|
|
+ IndexOutOfBounds exception. (Boris Shkolnik via rangadi)
|
|
|
+
|
|
|
+ HADOOP-5139. Catch IllegalArgumentException during metrics registration
|
|
|
+ in RPC. (Hairong Kuang via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5085. Copying a file to local with Crc throws an exception.
|
|
|
+ (hairong)
|
|
|
+
|
|
|
+ HADOOP-5211. Fix check for job completion in TestSetupAndCleanupFailure.
|
|
|
+ (enis)
|
|
|
+
|
|
|
+ HADOOP-5254. The Configuration class should be able to work with XML
|
|
|
+ parsers that do not support xmlinclude. (Steve Loughran via dhruba)
|
|
|
+
|
|
|
+ HADOOP-4692. Namenode in infinite loop for replicating/deleting corrupt
|
|
|
+ blocks. (hairong)
|
|
|
+
|
|
|
+ HADOOP-5255. Fix use of Math.abs to avoid overflow. (Jonathan Ellis via
|
|
|
+ cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5269. Fixes a problem to do with tasktracker holding on to
|
|
|
+ FAILED_UNCLEAN or KILLED_UNCLEAN tasks forever. (Amareshwari Sriramadasu
|
|
|
+ via ddas)
|
|
|
+
|
|
|
+ HADOOP-5214. Fixes a ConcurrentModificationException while the Fairshare
|
|
|
+ Scheduler accesses the tasktrackers stored by the JobTracker.
|
|
|
+ (Rahul Kumar Singh via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5233. Addresses the three issues - Race condition in updating
|
|
|
+ status, NPE in TaskTracker task localization when the conf file is missing
|
|
|
+ (HADOOP-5234) and NPE in handling KillTaskAction of a cleanup task
|
|
|
+ (HADOOP-5235). (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-5247. Introduces a broadcast of KillJobAction to all trackers when
|
|
|
+ a job finishes. This fixes a bunch of problems to do with NPE when a
|
|
|
+ completed job is not in memory and a tasktracker comes to the jobtracker
|
|
|
+ with a status report of a task belonging to that job. (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-5282. Fixed job history logs for task attempts that are
|
|
|
+ failed by the JobTracker, say due to lost task trackers. (Amar
|
|
|
+ Kamat via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5241. Fixes a bug in disk-space resource estimation. Makes
|
|
|
+ the estimation formula linear where blowUp =
|
|
|
+ Total-Output/Total-Input. (Sharad Agarwal via ddas)
|
|
|
+
|
|
|
+ HADOOP-5142. Fix MapWritable#putAll to store key/value classes.
|
|
|
+ (Do??acan G??ney via enis)
|
|
|
+
|
|
|
+ HADOOP-4744. Workaround for jetty6 returning -1 when getLocalPort
|
|
|
+ is invoked on the connector. The workaround patch retries a few
|
|
|
+ times before failing. (Jothi Padmanabhan via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5280. Adds a check to prevent a task state transition from
|
|
|
+ FAILED to any of UNASSIGNED, RUNNING, COMMIT_PENDING or
|
|
|
+ SUCCEEDED. (ddas)
|
|
|
+
|
|
|
+ HADOOP-5272. Fixes a problem to do with detecting whether an
|
|
|
+ attempt is the first attempt of a Task. This affects JobTracker
|
|
|
+ restart. (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-5306. Fixes a problem to do with logging/parsing the http port of a
|
|
|
+ lost tracker. Affects JobTracker restart. (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-5111. Fix Job::set* methods to work with generics. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5274. Fix gridmix2 dependency on wordcount example. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5145. Balancer sometimes runs out of memory after running
|
|
|
+ days or weeks. (hairong)
|
|
|
+
|
|
|
+ HADOOP-5338. Fix jobtracker restart to clear task completion
|
|
|
+ events cached by tasktrackers forcing them to fetch all events
|
|
|
+ afresh, thus avoiding missed task completion events on the
|
|
|
+ tasktrackers. (Amar Kamat via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-4695. Change TestGlobalFilter so that it allows a web page to be
|
|
|
+ filtered more than once for a single access. (Kan Zhang via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5298. Change TestServletFilter so that it allows a web page to be
|
|
|
+ filtered more than once for a single access. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5432. Disable ssl during unit tests in hdfsproxy, as it is unused
|
|
|
+ and causes failures. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5416. Correct the shell command "fs -test" forrest doc description.
|
|
|
+ (Ravi Phulari via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5327. Fixed job tracker to remove files from system directory on
|
|
|
+ ACL check failures and also check ACLs on restart.
|
|
|
+ (Amar Kamat via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5395. Change the exception message when a job is submitted to an
|
|
|
+ invalid queue. (Rahul Kumar Singh via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5276. Fixes a problem to do with updating the start time of
|
|
|
+ a task when the tracker that ran the task is lost. (Amar Kamat via
|
|
|
+ ddas)
|
|
|
+
|
|
|
+ HADOOP-5278. Fixes a problem to do with logging the finish time of
|
|
|
+ a task during recovery (after a JobTracker restart). (Amar Kamat
|
|
|
+ via ddas)
|
|
|
+
|
|
|
+ HADOOP-5490. Fixes a synchronization problem in the
|
|
|
+ EagerTaskInitializationListener class. (Jothi Padmanabhan via
|
|
|
+ ddas)
|
|
|
+
|
|
|
+ HADOOP-5493. The shuffle copier threads return the codecs back to
|
|
|
+ the pool when the shuffle completes. (Jothi Padmanabhan via ddas)
|
|
|
+
|
|
|
+ HADOOP-5414. Fixes IO exception while executing hadoop fs -touchz
|
|
|
+ fileName by making sure that lease renewal thread exits before dfs
|
|
|
+ client exits. (hairong)
|
|
|
+
|
|
|
+ HADOOP-5103. FileInputFormat now reuses the clusterMap network
|
|
|
+ topology object and that brings down the log messages in the
|
|
|
+ JobClient to do with NetworkTopology.add significantly. (Jothi
|
|
|
+ Padmanabhan via ddas)
|
|
|
+
|
|
|
+ HADOOP-5483. Fixes a problem in the Directory Cleanup Thread due to which
|
|
|
+ TestMiniMRWithDFS sometimes used to fail. (ddas)
|
|
|
+
|
|
|
+ HADOOP-5281. Prevent sharing incompatible ZlibCompressor instances between
|
|
|
+ GzipCodec and DefaultCodec. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5463. Balancer throws "Not a host:port pair" unless port is
|
|
|
+ specified in fs.default.name. (Stuart White via hairong)
|
|
|
+
|
|
|
+ HADOOP-5514. Fix JobTracker metrics and add metrics for wating, failed
|
|
|
+ tasks. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5516. Fix NullPointerException in TaskMemoryManagerThread
|
|
|
+ that comes when monitored processes disappear when the thread is
|
|
|
+ running. (Vinod Kumar Vavilapalli via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5382. Support combiners in the new context object API. (omalley)
|
|
|
+
|
|
|
+ HADOOP-5471. Fixes a problem to do with updating the log.index file in the
|
|
|
+ case where a cleanup task is run. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-5534. Fixed a deadlock in Fair scheduler's servlet.
|
|
|
+ (Rahul Kumar Singh via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5328. Fixes a problem in the renaming of job history files during
|
|
|
+ job recovery. (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-5417. Don't ignore InterruptedExceptions that happen when calling
|
|
|
+ into rpc. (omalley)
|
|
|
+
|
|
|
+ HADOOP-5320. Add a close() in TestMapReduceLocal. (Jothi Padmanabhan
|
|
|
+ via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5520. Fix a typo in disk quota help message. (Ravi Phulari
|
|
|
+ via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5519. Remove claims from mapred-default.xml that prime numbers
|
|
|
+ of tasks are helpful. (Owen O'Malley via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5484. TestRecoveryManager fails wtih FileAlreadyExistsException.
|
|
|
+ (Amar Kamat via hairong)
|
|
|
+
|
|
|
+ HADOOP-5564. Limit the JVM heap size in the java command for initializing
|
|
|
+ JAVA_PLATFORM. (Suresh Srinivas via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5565. Add API for failing/finalized jobs to the JT metrics
|
|
|
+ instrumentation. (Jerome Boulon via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5390. Remove duplicate jars from tarball, src from binary tarball
|
|
|
+ added by hdfsproxy. (Zhiyong Zhang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5066. Building binary tarball should not build docs/javadocs, copy
|
|
|
+ src, or run jdiff. (Giridharan Kesavan via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5459. Fix undetected CRC errors where intermediate output is closed
|
|
|
+ before it has been completely consumed. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5571. Remove widening primitive conversion in TupleWritable mask
|
|
|
+ manipulation. (Jingkei Ly via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5588. Remove an unnecessary call to listStatus(..) in
|
|
|
+ FileSystem.globStatusInternal(..). (Hairong Kuang via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5473. Solves a race condition in killing a task - the state is KILLED
|
|
|
+ if there is a user request pending to kill the task and the TT reported
|
|
|
+ the state as SUCCESS. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-5576. Fix LocalRunner to work with the new context object API in
|
|
|
+ mapreduce. (Tom White via omalley)
|
|
|
+
|
|
|
+ HADOOP-4374. Installs a shutdown hook in the Task JVM so that log.index is
|
|
|
+ updated before the JVM exits. Also makes the update to log.index atomic.
|
|
|
+ (Ravi Gummadi via ddas)
|
|
|
+
|
|
|
+ HADOOP-5577. Add a verbose flag to mapreduce.Job.waitForCompletion to get
|
|
|
+ the running job's information printed to the user's stdout as it runs.
|
|
|
+ (omalley)
|
|
|
+
|
|
|
+ HADOOP-5607. Fix NPE in TestCapacityScheduler. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5605. All the replicas incorrectly got marked as corrupt. (hairong)
|
|
|
+
|
|
|
+ HADOOP-5337. JobTracker, upon restart, now waits for the TaskTrackers to
|
|
|
+ join back before scheduling new tasks. This fixes race conditions associated
|
|
|
+ with greedy scheduling as was the case earlier. (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-5227. Fix distcp so -update and -delete can be meaningfully
|
|
|
+ combined. (Tsz Wo (Nicholas), SZE via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5305. Increase number of files and print debug messages in
|
|
|
+ TestCopyFiles. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5548. Add synchronization for JobTracker methods in RecoveryManager.
|
|
|
+ (Amareshwari Sriramadasu via sharad)
|
|
|
+
|
|
|
+ HADOOP-3810. NameNode seems unstable on a cluster with little space left.
|
|
|
+ (hairong)
|
|
|
+
|
|
|
+ HADOOP-5068. Fix NPE in TestCapacityScheduler. (Vinod Kumar Vavilapalli
|
|
|
+ via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5585. Clear FileSystem statistics between tasks when jvm-reuse
|
|
|
+ is enabled. (omalley)
|
|
|
+
|
|
|
+ HADOOP-5394. JobTracker might schedule 2 attempts of the same task
|
|
|
+ with the same attempt id across restarts. (Amar Kamat via sharad)
|
|
|
+
|
|
|
+ HADOOP-5645. After HADOOP-4920 we need a place to checkin
|
|
|
+ releasenotes.html. (nigel)
|
|
|
+
|
|
|
+Release 0.19.2 - 2009-06-30
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-5154. Fixes a deadlock in the fairshare scheduler.
|
|
|
+ (Matei Zaharia via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5146. Fixes a race condition that causes LocalDirAllocator to miss
|
|
|
+ files. (Devaraj Das via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-4638. Fixes job recovery to not crash the job tracker for problems
|
|
|
+ with a single job file. (Amar Kamat via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5384. Fix a problem that DataNodeCluster creates blocks with
|
|
|
+ generationStamp == 1. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5376. Fixes the code handling lost tasktrackers to set the task state
|
|
|
+ to KILLED_UNCLEAN only for relevant type of tasks.
|
|
|
+ (Amareshwari Sriramadasu via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-5285. Fixes the issues - (1) obtainTaskCleanupTask checks whether job is
|
|
|
+ inited before trying to lock the JobInProgress (2) Moves the CleanupQueue class
|
|
|
+ outside the TaskTracker and makes it a generic class that is used by the
|
|
|
+ JobTracker also for deleting the paths on the job's output fs. (3) Moves the
|
|
|
+ references to completedJobStore outside the block where the JobTracker is locked.
|
|
|
+ (ddas)
|
|
|
+
|
|
|
+ HADOOP-5392. Fixes a problem to do with JT crashing during recovery when
|
|
|
+ the job files are garbled. (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-5332. Appending to files is not allowed (by default) unless
|
|
|
+ dfs.support.append is set to true. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-5333. libhdfs supports appending to files. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-3998. Fix dfsclient exception when JVM is shutdown. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-5440. Fixes a problem to do with removing a taskId from the list
|
|
|
+ of taskIds that the TaskTracker's TaskMemoryManager manages.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-5446. Restore TaskTracker metrics. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5449. Fixes the history cleaner thread.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-5479. NameNode should not send empty block replication request to
|
|
|
+ DataNode. (hairong)
|
|
|
+
|
|
|
+ HADOOP-5259. Job with output hdfs:/user/<username>/outputpath (no
|
|
|
+ authority) fails with Wrong FS. (Doug Cutting via hairong)
|
|
|
+
|
|
|
+ HADOOP-5522. Documents the setup/cleanup tasks in the mapred tutorial.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-5549. ReplicationMonitor should schedule both replication and
|
|
|
+ deletion work in one iteration. (hairong)
|
|
|
+
|
|
|
+ HADOOP-5554. DataNodeCluster and CreateEditsLog should create blocks with
|
|
|
+ the same generation stamp value. (hairong via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5231. Clones the TaskStatus before passing it to the JobInProgress.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-4719. Fix documentation of 'ls' format for FsShell. (Ravi Phulari
|
|
|
+ via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5374. Fixes a NPE problem in getTasksToSave method.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-4780. Cache the size of directories in DistributedCache, avoiding
|
|
|
+ long delays in recalculating it. (He Yongqiang via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5551. Prevent directory destruction on file create.
|
|
|
+ (Brian Bockelman via shv)
|
|
|
+
|
|
|
+ HADOOP-5671. Fix FNF exceptions when copying from old versions of
|
|
|
+ HftpFileSystem. (Tsz Wo (Nicholas), SZE via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5213. Fix Null pointer exception caused when bzip2compression
|
|
|
+ was used and user closed a output stream without writing any data.
|
|
|
+ (Zheng Shao via dhruba)
|
|
|
+
|
|
|
+ HADOOP-5579. Set errno correctly in libhdfs for permission, quota, and FNF
|
|
|
+ conditions. (Brian Bockelman via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-5816. Fixes a problem in the KeyFieldBasedComparator to do with
|
|
|
+ ArrayIndexOutOfBounds exception. (He Yongqiang via ddas)
|
|
|
+
|
|
|
+ HADOOP-5951. Add Apache license header to StorageInfo.java. (Suresh
|
|
|
+ Srinivas via szetszwo)
|
|
|
+
|
|
|
+Release 0.19.1 - 2009-02-23
|
|
|
+
|
|
|
+ IMPROVEMENTS
|
|
|
+
|
|
|
+ HADOOP-4739. Fix spelling and grammar, improve phrasing of some sections in
|
|
|
+ mapred tutorial. (Vivek Ratan via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3894. DFSClient logging improvements. (Steve Loughran via shv)
|
|
|
+
|
|
|
+ HADOOP-5126. Remove empty file BlocksWithLocations.java (shv)
|
|
|
+
|
|
|
+ HADOOP-5127. Remove public methods in FSDirectory. (Jakob Homan via shv)
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-4697. Fix getBlockLocations in KosmosFileSystem to handle multiple
|
|
|
+ blocks correctly. (Sriram Rao via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4420. Add null checks for job, caused by invalid job IDs.
|
|
|
+ (Aaron Kimball via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-4632. Fix TestJobHistoryVersion to use test.build.dir instead of the
|
|
|
+ current workding directory for scratch space. (Amar Kamat via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4508. Fix FSDataOutputStream.getPos() for append. (dhruba via
|
|
|
+ szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4727. Fix a group checking bug in fill_stat_structure(...) in
|
|
|
+ fuse-dfs. (Brian Bockelman via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4836. Correct typos in mapred related documentation. (Jord? Polo
|
|
|
+ via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4821. Usage description in the Quotas guide documentations are
|
|
|
+ incorrect. (Boris Shkolnik via hairong)
|
|
|
+
|
|
|
+ HADOOP-4847. Moves the loading of OutputCommitter to the Task.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-4966. Marks completed setup tasks for removal.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-4982. TestFsck should run in Eclipse. (shv)
|
|
|
+
|
|
|
+ HADOOP-5008. TestReplication#testPendingReplicationRetry leaves an opened
|
|
|
+ fd unclosed. (hairong)
|
|
|
+
|
|
|
+ HADOOP-4906. Fix TaskTracker OOM by keeping a shallow copy of JobConf in
|
|
|
+ TaskTracker.TaskInProgress. (Sharad Agarwal via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4918. Fix bzip2 compression to work with Sequence Files.
|
|
|
+ (Zheng Shao via dhruba).
|
|
|
+
|
|
|
+ HADOOP-4965. TestFileAppend3 should close FileSystem. (shv)
|
|
|
+
|
|
|
+ HADOOP-4967. Fixes a race condition in the JvmManager to do with killing
|
|
|
+ tasks. (ddas)
|
|
|
+
|
|
|
+ HADOOP-5009. DataNode#shutdown sometimes leaves data block scanner
|
|
|
+ verification log unclosed. (hairong)
|
|
|
+
|
|
|
+ HADOOP-5086. Use the appropriate FileSystem for trash URIs. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4955. Make DBOutputFormat us column names from setOutput().
|
|
|
+ (Kevin Peterson via enis)
|
|
|
+
|
|
|
+ HADOOP-4862. Minor : HADOOP-3678 did not remove all the cases of
|
|
|
+ spurious IOExceptions logged by DataNode. (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-5034. NameNode should send both replication and deletion requests
|
|
|
+ to DataNode in one reply to a heartbeat. (hairong)
|
|
|
+
|
|
|
+ HADOOP-4759. Removes temporary output directory for failed and killed
|
|
|
+ tasks by launching special CLEANUP tasks for the same.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-5161. Accepted sockets do not get placed in
|
|
|
+ DataXceiverServer#childSockets. (hairong)
|
|
|
+
|
|
|
+ HADOOP-5193. Correct calculation of edits modification time. (shv)
|
|
|
+
|
|
|
+ HADOOP-4494. Allow libhdfs to append to files.
|
|
|
+ (Pete Wyckoff via dhruba)
|
|
|
+
|
|
|
+ HADOOP-5166. Fix JobTracker restart to work when ACLs are configured
|
|
|
+ for the JobTracker. (Amar Kamat via yhemanth).
|
|
|
+
|
|
|
+ HADOOP-5067. Fixes TaskInProgress.java to keep track of count of failed and
|
|
|
+ killed tasks correctly. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-4760. HDFS streams should not throw exceptions when closed twice.
|
|
|
+ (enis)
|
|
|
+
|
|
|
+Release 0.19.0 - 2008-11-18
|
|
|
+
|
|
|
+ INCOMPATIBLE CHANGES
|
|
|
+
|
|
|
+ HADOOP-3595. Remove deprecated methods for mapred.combine.once
|
|
|
+ functionality, which was necessary to providing backwards
|
|
|
+ compatible combiner semantics for 0.18. (cdouglas via omalley)
|
|
|
+
|
|
|
+ HADOOP-3667. Remove the following deprecated methods from JobConf:
|
|
|
+ addInputPath(Path)
|
|
|
+ getInputPaths()
|
|
|
+ getMapOutputCompressionType()
|
|
|
+ getOutputPath()
|
|
|
+ getSystemDir()
|
|
|
+ setInputPath(Path)
|
|
|
+ setMapOutputCompressionType(CompressionType style)
|
|
|
+ setOutputPath(Path)
|
|
|
+ (Amareshwari Sriramadasu via omalley)
|
|
|
+
|
|
|
+ HADOOP-3652. Remove deprecated class OutputFormatBase.
|
|
|
+ (Amareshwari Sriramadasu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2885. Break the hadoop.dfs package into separate packages under
|
|
|
+ hadoop.hdfs that reflect whether they are client, server, protocol,
|
|
|
+ etc. DistributedFileSystem and DFSClient have moved and are now
|
|
|
+ considered package private. (Sanjay Radia via omalley)
|
|
|
+
|
|
|
+ HADOOP-2325. Require Java 6. (cutting)
|
|
|
+
|
|
|
+ HADOOP-372. Add support for multiple input paths with a different
|
|
|
+ InputFormat and Mapper for each path. (Chris Smith via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-1700. Support appending to file in HDFS. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-3792. Make FsShell -test consistent with unix semantics, returning
|
|
|
+ zero for true and non-zero for false. (Ben Slusky via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3664. Remove the deprecated method InputFormat.validateInput,
|
|
|
+ which is no longer needed. (tomwhite via omalley)
|
|
|
+
|
|
|
+ HADOOP-3549. Give more meaningful errno's in libhdfs. In particular,
|
|
|
+ EACCES is returned for permission problems. (Ben Slusky via omalley)
|
|
|
+
|
|
|
+ HADOOP-4036. ResourceStatus was added to TaskTrackerStatus by HADOOP-3759,
|
|
|
+ so increment the InterTrackerProtocol version. (Hemanth Yamijala via
|
|
|
+ omalley)
|
|
|
+
|
|
|
+ HADOOP-3150. Moves task promotion to tasks. Defines a new interface for
|
|
|
+ committing output files. Moves job setup to jobclient, and moves jobcleanup
|
|
|
+ to a separate task. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3446. Keep map outputs in memory during the reduce. Remove
|
|
|
+ fs.inmemory.size.mb and replace with properties defining in memory map
|
|
|
+ output retention during the shuffle and reduce relative to maximum heap
|
|
|
+ usage. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3245. Adds the feature for supporting JobTracker restart. Running
|
|
|
+ jobs can be recovered from the history file. The history file format has
|
|
|
+ been modified to support recovery. The task attempt ID now has the
|
|
|
+ JobTracker start time to disinguish attempts of the same TIP across
|
|
|
+ restarts. (Amar Ramesh Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-4007. REMOVE DFSFileInfo - FileStatus is sufficient.
|
|
|
+ (Sanjay Radia via hairong)
|
|
|
+
|
|
|
+ HADOOP-3722. Fixed Hadoop Streaming and Hadoop Pipes to use the Tool
|
|
|
+ interface and GenericOptionsParser. (Enis Soztutar via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2816. Cluster summary at name node web reports the space
|
|
|
+ utilization as:
|
|
|
+ Configured Capacity: capacity of all the data directories - Reserved space
|
|
|
+ Present Capacity: Space available for dfs,i.e. remaining+used space
|
|
|
+ DFS Used%: DFS used space/Present Capacity
|
|
|
+ (Suresh Srinivas via hairong)
|
|
|
+
|
|
|
+ HADOOP-3938. Disk space quotas for HDFS. This is similar to namespace
|
|
|
+ quotas in 0.18. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-4293. Make Configuration Writable and remove unreleased
|
|
|
+ WritableJobConf. Configuration.write is renamed to writeXml. (omalley)
|
|
|
+
|
|
|
+ HADOOP-4281. Change dfsadmin to report available disk space in a format
|
|
|
+ consistent with the web interface as defined in HADOOP-2816. (Suresh
|
|
|
+ Srinivas via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4430. Further change the cluster summary at name node web that was
|
|
|
+ changed in HADOOP-2816:
|
|
|
+ Non DFS Used - This indicates the disk space taken by non DFS file from
|
|
|
+ the Configured capacity
|
|
|
+ DFS Used % - DFS Used % of Configured Capacity
|
|
|
+ DFS Remaining % - Remaing % Configured Capacity available for DFS use
|
|
|
+ DFS command line report reflects the same change. Config parameter
|
|
|
+ dfs.datanode.du.pct is no longer used and is removed from the
|
|
|
+ hadoop-default.xml. (Suresh Srinivas via hairong)
|
|
|
+
|
|
|
+ HADOOP-4116. Balancer should provide better resource management. (hairong)
|
|
|
+
|
|
|
+ HADOOP-4599. BlocksMap and BlockInfo made package private. (shv)
|
|
|
+
|
|
|
+ NEW FEATURES
|
|
|
+
|
|
|
+ HADOOP-3341. Allow streaming jobs to specify the field separator for map
|
|
|
+ and reduce input and output. The new configuration values are:
|
|
|
+ stream.map.input.field.separator
|
|
|
+ stream.map.output.field.separator
|
|
|
+ stream.reduce.input.field.separator
|
|
|
+ stream.reduce.output.field.separator
|
|
|
+ All of them default to "\t". (Zheng Shao via omalley)
|
|
|
+
|
|
|
+ HADOOP-3479. Defines the configuration file for the resource manager in
|
|
|
+ Hadoop. You can configure various parameters related to scheduling, such
|
|
|
+ as queues and queue properties here. The properties for a queue follow a
|
|
|
+ naming convention,such as, hadoop.rm.queue.queue-name.property-name.
|
|
|
+ (Hemanth Yamijala via ddas)
|
|
|
+
|
|
|
+ HADOOP-3149. Adds a way in which map/reducetasks can create multiple
|
|
|
+ outputs. (Alejandro Abdelnur via ddas)
|
|
|
+
|
|
|
+ HADOOP-3714. Add a new contrib, bash-tab-completion, which enables
|
|
|
+ bash tab completion for the bin/hadoop script. See the README file
|
|
|
+ in the contrib directory for the installation. (Chris Smith via enis)
|
|
|
+
|
|
|
+ HADOOP-3730. Adds a new JobConf constructor that disables loading
|
|
|
+ default configurations. (Alejandro Abdelnur via ddas)
|
|
|
+
|
|
|
+ HADOOP-3772. Add a new Hadoop Instrumentation api for the JobTracker and
|
|
|
+ the TaskTracker, refactor Hadoop Metrics as an implementation of the api.
|
|
|
+ (Ari Rabkin via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2302. Provides a comparator for numerical sorting of key fields.
|
|
|
+ (ddas)
|
|
|
+
|
|
|
+ HADOOP-153. Provides a way to skip bad records. (Sharad Agarwal via ddas)
|
|
|
+
|
|
|
+ HADOOP-657. Free disk space should be modelled and used by the scheduler
|
|
|
+ to make scheduling decisions. (Ari Rabkin via omalley)
|
|
|
+
|
|
|
+ HADOOP-3719. Initial checkin of Chukwa, which is a data collection and
|
|
|
+ analysis framework. (Jerome Boulon, Andy Konwinski, Ari Rabkin,
|
|
|
+ and Eric Yang)
|
|
|
+
|
|
|
+ HADOOP-3873. Add -filelimit and -sizelimit options to distcp to cap the
|
|
|
+ number of files/bytes copied in a particular run to support incremental
|
|
|
+ updates and mirroring. (TszWo (Nicholas), SZE via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3585. FailMon package for hardware failure monitoring and
|
|
|
+ analysis of anomalies. (Ioannis Koltsidas via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1480. Add counters to the C++ Pipes API. (acmurthy via omalley)
|
|
|
+
|
|
|
+ HADOOP-3854. Add support for pluggable servlet filters in the HttpServers.
|
|
|
+ (Tsz Wo (Nicholas) Sze via omalley)
|
|
|
+
|
|
|
+ HADOOP-3759. Provides ability to run memory intensive jobs without
|
|
|
+ affecting other running tasks on the nodes. (Hemanth Yamijala via ddas)
|
|
|
+
|
|
|
+ HADOOP-3746. Add a fair share scheduler. (Matei Zaharia via omalley)
|
|
|
+
|
|
|
+ HADOOP-3754. Add a thrift interface to access HDFS. (dhruba via omalley)
|
|
|
+
|
|
|
+ HADOOP-3828. Provides a way to write skipped records to DFS.
|
|
|
+ (Sharad Agarwal via ddas)
|
|
|
+
|
|
|
+ HADOOP-3948. Separate name-node edits and fsimage directories.
|
|
|
+ (Lohit Vijayarenu via shv)
|
|
|
+
|
|
|
+ HADOOP-3939. Add an option to DistCp to delete files at the destination
|
|
|
+ not present at the source. (Tsz Wo (Nicholas) Sze via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3601. Add a new contrib module for Hive, which is a sql-like
|
|
|
+ query processing tool that uses map/reduce. (Ashish Thusoo via omalley)
|
|
|
+
|
|
|
+ HADOOP-3866. Added sort and multi-job updates in the JobTracker web ui.
|
|
|
+ (Craig Weisenfluh via omalley)
|
|
|
+
|
|
|
+ HADOOP-3698. Add access control to control who is allowed to submit or
|
|
|
+ modify jobs in the JobTracker. (Hemanth Yamijala via omalley)
|
|
|
+
|
|
|
+ HADOOP-1869. Support access times for HDFS files. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-3941. Extend FileSystem API to return file-checksums.
|
|
|
+ (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-3581. Prevents memory intensive user tasks from taking down
|
|
|
+ nodes. (Vinod K V via ddas)
|
|
|
+
|
|
|
+ HADOOP-3970. Provides a way to recover counters written to JobHistory.
|
|
|
+ (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-3702. Adds ChainMapper and ChainReducer classes allow composing
|
|
|
+ chains of Maps and Reduces in a single Map/Reduce job, something like
|
|
|
+ MAP+ / REDUCE MAP*. (Alejandro Abdelnur via ddas)
|
|
|
+
|
|
|
+ HADOOP-3445. Add capacity scheduler that provides guaranteed capacities to
|
|
|
+ queues as a percentage of the cluster. (Vivek Ratan via omalley)
|
|
|
+
|
|
|
+ HADOOP-3992. Add a synthetic load generation facility to the test
|
|
|
+ directory. (hairong via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-3981. Implement a distributed file checksum algorithm in HDFS
|
|
|
+ and change DistCp to use file checksum for comparing src and dst files
|
|
|
+ (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-3829. Narrown down skipped records based on user acceptable value.
|
|
|
+ (Sharad Agarwal via ddas)
|
|
|
+
|
|
|
+ HADOOP-3930. Add common interfaces for the pluggable schedulers and the
|
|
|
+ cli & gui clients. (Sreekanth Ramakrishnan via omalley)
|
|
|
+
|
|
|
+ HADOOP-4176. Implement getFileChecksum(Path) in HftpFileSystem. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-249. Reuse JVMs across Map-Reduce Tasks.
|
|
|
+ Configuration changes to hadoop-default.xml:
|
|
|
+ add mapred.job.reuse.jvm.num.tasks
|
|
|
+ (Devaraj Das via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4070. Provide a mechanism in Hive for registering UDFs from the
|
|
|
+ query language. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-2536. Implement a JDBC based database input and output formats to
|
|
|
+ allow Map-Reduce applications to work with databases. (Fredrik Hedberg and
|
|
|
+ Enis Soztutar via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-3019. A new library to support total order partitions.
|
|
|
+ (cdouglas via omalley)
|
|
|
+
|
|
|
+ HADOOP-3924. Added a 'KILLED' job status. (Subramaniam Krishnan via
|
|
|
+ acmurthy)
|
|
|
+
|
|
|
+ IMPROVEMENTS
|
|
|
+
|
|
|
+ HADOOP-4205. hive: metastore and ql to use the refactored SerDe library.
|
|
|
+ (zshao)
|
|
|
+
|
|
|
+ HADOOP-4106. libhdfs: add time, permission and user attribute support
|
|
|
+ (part 2). (Pete Wyckoff through zshao)
|
|
|
+
|
|
|
+ HADOOP-4104. libhdfs: add time, permission and user attribute support.
|
|
|
+ (Pete Wyckoff through zshao)
|
|
|
+
|
|
|
+ HADOOP-3908. libhdfs: better error message if llibhdfs.so doesn't exist.
|
|
|
+ (Pete Wyckoff through zshao)
|
|
|
+
|
|
|
+ HADOOP-3732. Delay intialization of datanode block verification till
|
|
|
+ the verification thread is started. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-1627. Various small improvements to 'dfsadmin -report' output.
|
|
|
+ (rangadi)
|
|
|
+
|
|
|
+ HADOOP-3577. Tools to inject blocks into name node and simulated
|
|
|
+ data nodes for testing. (Sanjay Radia via hairong)
|
|
|
+
|
|
|
+ HADOOP-2664. Add a lzop compatible codec, so that files compressed by lzop
|
|
|
+ may be processed by map/reduce. (cdouglas via omalley)
|
|
|
+
|
|
|
+ HADOOP-3655. Add additional ant properties to control junit. (Steve
|
|
|
+ Loughran via omalley)
|
|
|
+
|
|
|
+ HADOOP-3543. Update the copyright year to 2008. (cdouglas via omalley)
|
|
|
+
|
|
|
+ HADOOP-3587. Add a unit test for the contrib/data_join framework.
|
|
|
+ (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3402. Add terasort example program (omalley)
|
|
|
+
|
|
|
+ HADOOP-3660. Add replication factor for injecting blocks in simulated
|
|
|
+ datanodes. (Sanjay Radia via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3684. Add a cloning function to the contrib/data_join framework
|
|
|
+ permitting users to define a more efficient method for cloning values from
|
|
|
+ the reduce than serialization/deserialization. (Runping Qi via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3478. Improves the handling of map output fetching. Now the
|
|
|
+ randomization is by the hosts (and not the map outputs themselves).
|
|
|
+ (Jothi Padmanabhan via ddas)
|
|
|
+
|
|
|
+ HADOOP-3617. Removed redundant checks of accounting space in MapTask and
|
|
|
+ makes the spill thread persistent so as to avoid creating a new one for
|
|
|
+ each spill. (Chris Douglas via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-3412. Factor the scheduler out of the JobTracker and make
|
|
|
+ it pluggable. (Tom White and Brice Arnould via omalley)
|
|
|
+
|
|
|
+ HADOOP-3756. Minor. Remove unused dfs.client.buffer.dir from
|
|
|
+ hadoop-default.xml. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-3747. Adds counter suport for MultipleOutputs.
|
|
|
+ (Alejandro Abdelnur via ddas)
|
|
|
+
|
|
|
+ HADOOP-3169. LeaseChecker daemon should not be started in DFSClient
|
|
|
+ constructor. (TszWo (Nicholas), SZE via hairong)
|
|
|
+
|
|
|
+ HADOOP-3824. Move base functionality of StatusHttpServer to a core
|
|
|
+ package. (TszWo (Nicholas), SZE via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3646. Add a bzip2 compatible codec, so bzip compressed data
|
|
|
+ may be processed by map/reduce. (Abdul Qadeer via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3861. MapFile.Reader and Writer should implement Closeable.
|
|
|
+ (tomwhite via omalley)
|
|
|
+
|
|
|
+ HADOOP-3791. Introduce generics into ReflectionUtils. (Chris Smith via
|
|
|
+ cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3694. Improve unit test performance by changing
|
|
|
+ MiniDFSCluster to listen only on 127.0.0.1. (cutting)
|
|
|
+
|
|
|
+ HADOOP-3620. Namenode should synchronously resolve a datanode's network
|
|
|
+ location when the datanode registers. (hairong)
|
|
|
+
|
|
|
+ HADOOP-3860. NNThroughputBenchmark is extended with rename and delete
|
|
|
+ benchmarks. (shv)
|
|
|
+
|
|
|
+ HADOOP-3892. Include unix group name in JobConf. (Matei Zaharia via johan)
|
|
|
+
|
|
|
+ HADOOP-3875. Change the time period between heartbeats to be relative to
|
|
|
+ the end of the heartbeat rpc, rather than the start. This causes better
|
|
|
+ behavior if the JobTracker is overloaded. (acmurthy via omalley)
|
|
|
+
|
|
|
+ HADOOP-3853. Move multiple input format (HADOOP-372) extension to
|
|
|
+ library package. (tomwhite via johan)
|
|
|
+
|
|
|
+ HADOOP-9. Use roulette scheduling for temporary space when the size
|
|
|
+ is not known. (Ari Rabkin via omalley)
|
|
|
+
|
|
|
+ HADOOP-3202. Use recursive delete rather than FileUtil.fullyDelete.
|
|
|
+ (Amareshwari Sriramadasu via omalley)
|
|
|
+
|
|
|
+ HADOOP-3368. Remove common-logging.properties from conf. (Steve Loughran
|
|
|
+ via omalley)
|
|
|
+
|
|
|
+ HADOOP-3851. Fix spelling mistake in FSNamesystemMetrics. (Steve Loughran
|
|
|
+ via omalley)
|
|
|
+
|
|
|
+ HADOOP-3780. Remove asynchronous resolution of network topology in the
|
|
|
+ JobTracker (Amar Kamat via omalley)
|
|
|
+
|
|
|
+ HADOOP-3852. Add ShellCommandExecutor.toString method to make nicer
|
|
|
+ error messages. (Steve Loughran via omalley)
|
|
|
+
|
|
|
+ HADOOP-3844. Include message of local exception in RPC client failures.
|
|
|
+ (Steve Loughran via omalley)
|
|
|
+
|
|
|
+ HADOOP-3935. Split out inner classes from DataNode.java. (johan)
|
|
|
+
|
|
|
+ HADOOP-3905. Create generic interfaces for edit log streams. (shv)
|
|
|
+
|
|
|
+ HADOOP-3062. Add metrics to DataNode and TaskTracker to record network
|
|
|
+ traffic for HDFS reads/writes and MR shuffling. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3742. Remove HDFS from public java doc and add javadoc-dev for
|
|
|
+ generative javadoc for developers. (Sanjay Radia via omalley)
|
|
|
+
|
|
|
+ HADOOP-3944. Improve documentation for public TupleWritable class in
|
|
|
+ join package. (Chris Douglas via enis)
|
|
|
+
|
|
|
+ HADOOP-2330. Preallocate HDFS transaction log to improve performance.
|
|
|
+ (dhruba and hairong)
|
|
|
+
|
|
|
+ HADOOP-3965. Convert DataBlockScanner into a package private class. (shv)
|
|
|
+
|
|
|
+ HADOOP-3488. Prevent hadoop-daemon from rsync'ing log files (Stefan
|
|
|
+ Groshupf and Craig Macdonald via omalley)
|
|
|
+
|
|
|
+ HADOOP-3342. Change the kill task actions to require http post instead of
|
|
|
+ get to prevent accidental crawls from triggering it. (enis via omalley)
|
|
|
+
|
|
|
+ HADOOP-3937. Limit the job name in the job history filename to 50
|
|
|
+ characters. (Matei Zaharia via omalley)
|
|
|
+
|
|
|
+ HADOOP-3943. Remove unnecessary synchronization in
|
|
|
+ NetworkTopology.pseudoSortByDistance. (hairong via omalley)
|
|
|
+
|
|
|
+ HADOOP-3498. File globbing alternation should be able to span path
|
|
|
+ components. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-3361. Implement renames for NativeS3FileSystem.
|
|
|
+ (Albert Chern via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-3605. Make EC2 scripts show an error message if AWS_ACCOUNT_ID is
|
|
|
+ unset. (Al Hoang via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-4147. Remove unused class JobWithTaskContext from class
|
|
|
+ JobInProgress. (Amareshwari Sriramadasu via johan)
|
|
|
+
|
|
|
+ HADOOP-4151. Add a byte-comparable interface that both Text and
|
|
|
+ BytesWritable implement. (cdouglas via omalley)
|
|
|
+
|
|
|
+ HADOOP-4174. Move fs image/edit log methods from ClientProtocol to
|
|
|
+ NamenodeProtocol. (shv via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4181. Include a .gitignore and saveVersion.sh change to support
|
|
|
+ developing under git. (omalley)
|
|
|
+
|
|
|
+ HADOOP-4186. Factor LineReader out of LineRecordReader. (tomwhite via
|
|
|
+ omalley)
|
|
|
+
|
|
|
+ HADOOP-4184. Break the module dependencies between core, hdfs, and
|
|
|
+ mapred. (tomwhite via omalley)
|
|
|
+
|
|
|
+ HADOOP-4075. test-patch.sh now spits out ant commands that it runs.
|
|
|
+ (Ramya R via nigel)
|
|
|
+
|
|
|
+ HADOOP-4117. Improve configurability of Hadoop EC2 instances.
|
|
|
+ (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-2411. Add support for larger CPU EC2 instance types.
|
|
|
+ (Chris K Wensel via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-4083. Changed the configuration attribute queue.name to
|
|
|
+ mapred.job.queue.name. (Hemanth Yamijala via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4194. Added the JobConf and JobID to job-related methods in
|
|
|
+ JobTrackerInstrumentation for better metrics. (Mac Yang via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-3975. Change test-patch script to report working the dir
|
|
|
+ modifications preventing the suite from being run. (Ramya R via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4124. Added a command-line switch to allow users to set job
|
|
|
+ priorities, also allow it to be manipulated via the web-ui. (Hemanth
|
|
|
+ Yamijala via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2165. Augmented JobHistory to include the URIs to the tasks'
|
|
|
+ userlogs. (Vinod Kumar Vavilapalli via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4062. Remove the synchronization on the output stream when a
|
|
|
+ connection is closed and also remove an undesirable exception when
|
|
|
+ a client is stoped while there is no pending RPC request. (hairong)
|
|
|
+
|
|
|
+ HADOOP-4227. Remove the deprecated class org.apache.hadoop.fs.ShellCommand.
|
|
|
+ (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4006. Clean up FSConstants and move some of the constants to
|
|
|
+ better places. (Sanjay Radia via rangadi)
|
|
|
+
|
|
|
+ HADOOP-4279. Trace the seeds of random sequences in append unit tests to
|
|
|
+ make itermitant failures reproducible. (szetszwo via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4209. Remove the change to the format of task attempt id by
|
|
|
+ incrementing the task attempt numbers by 1000 when the job restarts.
|
|
|
+ (Amar Kamat via omalley)
|
|
|
+
|
|
|
+ HADOOP-4301. Adds forrest doc for the skip bad records feature.
|
|
|
+ (Sharad Agarwal via ddas)
|
|
|
+
|
|
|
+ HADOOP-4354. Separate TestDatanodeDeath.testDatanodeDeath() into 4 tests.
|
|
|
+ (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-3790. Add more unit tests for testing HDFS file append. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4321. Include documentation for the capacity scheduler. (Hemanth
|
|
|
+ Yamijala via omalley)
|
|
|
+
|
|
|
+ HADOOP-4424. Change menu layout for Hadoop documentation (Boris Shkolnik
|
|
|
+ via cdouglas).
|
|
|
+
|
|
|
+ HADOOP-4438. Update forrest documentation to include missing FsShell
|
|
|
+ commands. (Suresh Srinivas via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4105. Add forrest documentation for libhdfs.
|
|
|
+ (Pete Wyckoff via cutting)
|
|
|
+
|
|
|
+ HADOOP-4510. Make getTaskOutputPath public. (Chris Wensel via omalley)
|
|
|
+
|
|
|
+ OPTIMIZATIONS
|
|
|
+
|
|
|
+ HADOOP-3556. Removed lock contention in MD5Hash by changing the
|
|
|
+ singleton MessageDigester by an instance per Thread using
|
|
|
+ ThreadLocal. (Iv?n de Prado via omalley)
|
|
|
+
|
|
|
+ HADOOP-3328. When client is writing data to DFS, only the last
|
|
|
+ datanode in the pipeline needs to verify the checksum. Saves around
|
|
|
+ 30% CPU on intermediate datanodes. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-3863. Use a thread-local string encoder rather than a static one
|
|
|
+ that is protected by a lock. (acmurthy via omalley)
|
|
|
+
|
|
|
+ HADOOP-3864. Prevent the JobTracker from locking up when a job is being
|
|
|
+ initialized. (acmurthy via omalley)
|
|
|
+
|
|
|
+ HADOOP-3816. Faster directory listing in KFS. (Sriram Rao via omalley)
|
|
|
+
|
|
|
+ HADOOP-2130. Pipes submit job should have both blocking and non-blocking
|
|
|
+ versions. (acmurthy via omalley)
|
|
|
+
|
|
|
+ HADOOP-3769. Make the SampleMapper and SampleReducer from
|
|
|
+ GenericMRLoadGenerator public, so they can be used in other contexts.
|
|
|
+ (Lingyun Yang via omalley)
|
|
|
+
|
|
|
+ HADOOP-3514. Inline the CRCs in intermediate files as opposed to reading
|
|
|
+ it from a different .crc file. (Jothi Padmanabhan via ddas)
|
|
|
+
|
|
|
+ HADOOP-3638. Caches the iFile index files in memory to reduce seeks
|
|
|
+ (Jothi Padmanabhan via ddas)
|
|
|
+
|
|
|
+ HADOOP-4225. FSEditLog.logOpenFile() should persist accessTime
|
|
|
+ rather than modificationTime. (shv)
|
|
|
+
|
|
|
+ HADOOP-4380. Made several new classes (Child, JVMId,
|
|
|
+ JobTrackerInstrumentation, QueueManager, ResourceEstimator,
|
|
|
+ TaskTrackerInstrumentation, and TaskTrackerMetricsInst) in
|
|
|
+ org.apache.hadoop.mapred package private instead of public. (omalley)
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-3563. Refactor the distributed upgrade code so that it is
|
|
|
+ easier to identify datanode and namenode related code. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-3640. Fix the read method in the NativeS3InputStream. (tomwhite via
|
|
|
+ omalley)
|
|
|
+
|
|
|
+ HADOOP-3711. Fixes the Streaming input parsing to properly find the
|
|
|
+ separator. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3725. Prevent TestMiniMRMapDebugScript from swallowing exceptions.
|
|
|
+ (Steve Loughran via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3726. Throw exceptions from TestCLI setup and teardown instead of
|
|
|
+ swallowing them. (Steve Loughran via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3721. Refactor CompositeRecordReader and related mapred.join classes
|
|
|
+ to make them clearer. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3720. Re-read the config file when dfsadmin -refreshNodes is invoked
|
|
|
+ so dfs.hosts and dfs.hosts.exclude are observed. (lohit vijayarenu via
|
|
|
+ cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3485. Allow writing to files over fuse.
|
|
|
+ (Pete Wyckoff via dhruba)
|
|
|
+
|
|
|
+ HADOOP-3723. The flags to the libhdfs.create call can be treated as
|
|
|
+ a bitmask. (Pete Wyckoff via dhruba)
|
|
|
+
|
|
|
+ HADOOP-3643. Filter out completed tasks when asking for running tasks in
|
|
|
+ the JobTracker web/ui. (Amar Kamat via omalley)
|
|
|
+
|
|
|
+ HADOOP-3777. Ensure that Lzo compressors/decompressors correctly handle the
|
|
|
+ case where native libraries aren't available. (Chris Douglas via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-3728. Fix SleepJob so that it doesn't depend on temporary files,
|
|
|
+ this ensures we can now run more than one instance of SleepJob
|
|
|
+ simultaneously. (Chris Douglas via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-3795. Fix saving image files on Namenode with different checkpoint
|
|
|
+ stamps. (Lohit Vijayarenu via mahadev)
|
|
|
+
|
|
|
+ HADOOP-3624. Improving createeditslog to create tree directory structure.
|
|
|
+ (Lohit Vijayarenu via mahadev)
|
|
|
+
|
|
|
+ HADOOP-3778. DFSInputStream.seek() did not retry in case of some errors.
|
|
|
+ (Luo Ning via rangadi)
|
|
|
+
|
|
|
+ HADOOP-3661. The handling of moving files deleted through fuse-dfs to
|
|
|
+ Trash made similar to the behaviour from dfs shell.
|
|
|
+ (Pete Wyckoff via dhruba)
|
|
|
+
|
|
|
+ HADOOP-3819. Unset LANG and LC_CTYPE in saveVersion.sh to make it
|
|
|
+ compatible with non-English locales. (Rong-En Fan via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3848. Cache calls to getSystemDir in the TaskTracker instead of
|
|
|
+ calling it for each task start. (acmurthy via omalley)
|
|
|
+
|
|
|
+ HADOOP-3131. Fix reduce progress reporting for compressed intermediate
|
|
|
+ data. (Matei Zaharia via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-3796. fuse-dfs configuration is implemented as file system
|
|
|
+ mount options. (Pete Wyckoff via dhruba)
|
|
|
+
|
|
|
+ HADOOP-3836. Fix TestMultipleOutputs to correctly clean up. (Alejandro
|
|
|
+ Abdelnur via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-3805. Improve fuse-dfs write performance.
|
|
|
+ (Pete Wyckoff via zshao)
|
|
|
+
|
|
|
+ HADOOP-3846. Fix unit test CreateEditsLog to generate paths correctly.
|
|
|
+ (Lohit Vjayarenu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3904. Fix unit tests using the old dfs package name.
|
|
|
+ (TszWo (Nicholas), SZE via johan)
|
|
|
+
|
|
|
+ HADOOP-3319. Fix some HOD error messages to go stderr instead of
|
|
|
+ stdout. (Vinod Kumar Vavilapalli via omalley)
|
|
|
+
|
|
|
+ HADOOP-3907. Move INodeDirectoryWithQuota to its own .java file.
|
|
|
+ (Tsz Wo (Nicholas), SZE via hairong)
|
|
|
+
|
|
|
+ HADOOP-3919. Fix attribute name in hadoop-default for
|
|
|
+ mapred.jobtracker.instrumentation. (Ari Rabkin via omalley)
|
|
|
+
|
|
|
+ HADOOP-3903. Change the package name for the servlets to be hdfs instead of
|
|
|
+ dfs. (Tsz Wo (Nicholas) Sze via omalley)
|
|
|
+
|
|
|
+ HADOOP-3773. Change Pipes to set the default map output key and value
|
|
|
+ types correctly. (Koji Noguchi via omalley)
|
|
|
+
|
|
|
+ HADOOP-3952. Fix compilation error in TestDataJoin referencing dfs package.
|
|
|
+ (omalley)
|
|
|
+
|
|
|
+ HADOOP-3951. Fix package name for FSNamesystem logs and modify other
|
|
|
+ hard-coded Logs to use the class name. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3889. Improve error reporting from HftpFileSystem, handling in
|
|
|
+ DistCp. (Tsz Wo (Nicholas), SZE via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3946. Fix TestMapRed after hadoop-3664. (tomwhite via omalley)
|
|
|
+
|
|
|
+ HADOOP-3949. Remove duplicate jars from Chukwa. (Jerome Boulon via omalley)
|
|
|
+
|
|
|
+ HADOOP-3933. DataNode sometimes sends up to io.byte.per.checksum bytes
|
|
|
+ more than required to client. (Ning Li via rangadi)
|
|
|
+
|
|
|
+ HADOOP-3962. Shell command "fs -count" should support paths with different
|
|
|
+ file systems. (Tsz Wo (Nicholas), SZE via mahadev)
|
|
|
+
|
|
|
+ HADOOP-3957. Fix javac warnings in DistCp and TestCopyFiles. (Tsz Wo
|
|
|
+ (Nicholas), SZE via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3958. Fix TestMapRed to check the success of test-job. (omalley via
|
|
|
+ acmurthy)
|
|
|
+
|
|
|
+ HADOOP-3985. Fix TestHDFSServerPorts to use random ports. (Hairong Kuang
|
|
|
+ via omalley)
|
|
|
+
|
|
|
+ HADOOP-3964. Fix javadoc warnings introduced by FailMon. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-3785. Fix FileSystem cache to be case-insensitive for scheme and
|
|
|
+ authority. (Bill de hOra via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3506. Fix a rare NPE caused by error handling in S3. (Tom White via
|
|
|
+ cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3705. Fix mapred.join parser to accept InputFormats named with
|
|
|
+ underscore and static, inner classes. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4023. Fix javadoc warnings introduced when the HDFS javadoc was
|
|
|
+ made private. (omalley)
|
|
|
+
|
|
|
+ HADOOP-4030. Remove lzop from the default list of codecs. (Arun Murthy via
|
|
|
+ cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3961. Fix task disk space requirement estimates for virtual
|
|
|
+ input jobs. Delays limiting task placement until after 10% of the maps
|
|
|
+ have finished. (Ari Rabkin via omalley)
|
|
|
+
|
|
|
+ HADOOP-2168. Fix problem with C++ record reader's progress not being
|
|
|
+ reported to framework. (acmurthy via omalley)
|
|
|
+
|
|
|
+ HADOOP-3966. Copy findbugs generated output files to PATCH_DIR while
|
|
|
+ running test-patch. (Ramya R via lohit)
|
|
|
+
|
|
|
+ HADOOP-4037. Fix the eclipse plugin for versions of kfs and log4j. (nigel
|
|
|
+ via omalley)
|
|
|
+
|
|
|
+ HADOOP-3950. Cause the Mini MR cluster to wait for task trackers to
|
|
|
+ register before continuing. (enis via omalley)
|
|
|
+
|
|
|
+ HADOOP-3910. Remove unused ClusterTestDFSNamespaceLogging and
|
|
|
+ ClusterTestDFS. (Tsz Wo (Nicholas), SZE via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3954. Disable record skipping by default. (Sharad Agarwal via
|
|
|
+ cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4050. Fix TestFairScheduler to use absolute paths for the work
|
|
|
+ directory. (Matei Zaharia via omalley)
|
|
|
+
|
|
|
+ HADOOP-4069. Keep temporary test files from TestKosmosFileSystem under
|
|
|
+ test.build.data instead of /tmp. (lohit via omalley)
|
|
|
+
|
|
|
+ HADOOP-4078. Create test files for TestKosmosFileSystem in separate
|
|
|
+ directory under test.build.data. (lohit)
|
|
|
+
|
|
|
+ HADOOP-3968. Fix getFileBlockLocations calls to use FileStatus instead
|
|
|
+ of Path reflecting the new API. (Pete Wyckoff via lohit)
|
|
|
+
|
|
|
+ HADOOP-3963. libhdfs does not exit on its own, instead it returns error
|
|
|
+ to the caller and behaves as a true library. (Pete Wyckoff via dhruba)
|
|
|
+
|
|
|
+ HADOOP-4100. Removes the cleanupTask scheduling from the Scheduler
|
|
|
+ implementations and moves it to the JobTracker.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-4097. Make hive work well with speculative execution turned on.
|
|
|
+ (Joydeep Sen Sarma via dhruba)
|
|
|
+
|
|
|
+ HADOOP-4113. Changes to libhdfs to not exit on its own, rather return
|
|
|
+ an error code to the caller. (Pete Wyckoff via dhruba)
|
|
|
+
|
|
|
+ HADOOP-4054. Remove duplicate lease removal during edit log loading.
|
|
|
+ (hairong)
|
|
|
+
|
|
|
+ HADOOP-4071. FSNameSystem.isReplicationInProgress should add an
|
|
|
+ underReplicated block to the neededReplication queue using method
|
|
|
+ "add" not "update". (hairong)
|
|
|
+
|
|
|
+ HADOOP-4154. Fix type warnings in WritableUtils. (szetszwo via omalley)
|
|
|
+
|
|
|
+ HADOOP-4133. Log files generated by Hive should reside in the
|
|
|
+ build directory. (Prasad Chakka via dhruba)
|
|
|
+
|
|
|
+ HADOOP-4094. Hive now has hive-default.xml and hive-site.xml similar
|
|
|
+ to core hadoop. (Prasad Chakka via dhruba)
|
|
|
+
|
|
|
+ HADOOP-4112. Handles cleanupTask in JobHistory
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3831. Very slow reading clients sometimes failed while reading.
|
|
|
+ (rangadi)
|
|
|
+
|
|
|
+ HADOOP-4155. Use JobTracker's start time while initializing JobHistory's
|
|
|
+ JobTracker Unique String. (lohit)
|
|
|
+
|
|
|
+ HADOOP-4099. Fix null pointer when using HFTP from an 0.18 server.
|
|
|
+ (dhruba via omalley)
|
|
|
+
|
|
|
+ HADOOP-3570. Includes user specified libjar files in the client side
|
|
|
+ classpath path. (Sharad Agarwal via ddas)
|
|
|
+
|
|
|
+ HADOOP-4129. Changed memory limits of TaskTracker and Tasks to be in
|
|
|
+ KiloBytes rather than bytes. (Vinod Kumar Vavilapalli via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4139. Optimize Hive multi group-by.
|
|
|
+ (Namin Jain via dhruba)
|
|
|
+
|
|
|
+ HADOOP-3911. Add a check to fsck options to make sure -files is not
|
|
|
+ the first option to resolve conflicts with GenericOptionsParser
|
|
|
+ (lohit)
|
|
|
+
|
|
|
+ HADOOP-3623. Refactor LeaseManager. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4125. Handles Reduce cleanup tip on the web ui.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-4087. Hive Metastore API for php and python clients.
|
|
|
+ (Prasad Chakka via dhruba)
|
|
|
+
|
|
|
+ HADOOP-4197. Update DATA_TRANSFER_VERSION for HADOOP-3981. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4138. Refactor the Hive SerDe library to better structure
|
|
|
+ the interfaces to the serializer and de-serializer.
|
|
|
+ (Zheng Shao via dhruba)
|
|
|
+
|
|
|
+ HADOOP-4195. Close compressor before returning to codec pool.
|
|
|
+ (acmurthy via omalley)
|
|
|
+
|
|
|
+ HADOOP-2403. Escapes some special characters before logging to
|
|
|
+ history files. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-4200. Fix a bug in the test-patch.sh script.
|
|
|
+ (Ramya R via nigel)
|
|
|
+
|
|
|
+ HADOOP-4084. Add explain plan capabilities to Hive Query Language.
|
|
|
+ (Ashish Thusoo via dhruba)
|
|
|
+
|
|
|
+ HADOOP-4121. Preserve cause for exception if the initialization of
|
|
|
+ HistoryViewer for JobHistory fails. (Amareshwari Sri Ramadasu via
|
|
|
+ acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4213. Fixes NPE in TestLimitTasksPerJobTaskScheduler.
|
|
|
+ (Sreekanth Ramakrishnan via ddas)
|
|
|
+
|
|
|
+ HADOOP-4077. Setting access and modification time for a file
|
|
|
+ requires write permissions on the file. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-3592. Fix a couple of possible file leaks in FileUtil
|
|
|
+ (Bill de hOra via rangadi)
|
|
|
+
|
|
|
+ HADOOP-4120. Hive interactive shell records the time taken by a
|
|
|
+ query. (Raghotham Murthy via dhruba)
|
|
|
+
|
|
|
+ HADOOP-4090. The hive scripts pick up hadoop from HADOOP_HOME
|
|
|
+ and then the path. (Raghotham Murthy via dhruba)
|
|
|
+
|
|
|
+ HADOOP-4242. Remove extra ";" in FSDirectory that blocks compilation
|
|
|
+ in some IDE's. (szetszwo via omalley)
|
|
|
+
|
|
|
+ HADOOP-4249. Fix eclipse path to include the hsqldb.jar. (szetszwo via
|
|
|
+ omalley)
|
|
|
+
|
|
|
+ HADOOP-4247. Move InputSampler into org.apache.hadoop.mapred.lib, so that
|
|
|
+ examples.jar doesn't depend on tools.jar. (omalley)
|
|
|
+
|
|
|
+ HADOOP-4269. Fix the deprecation of LineReader by extending the new class
|
|
|
+ into the old name and deprecating it. Also update the tests to test the
|
|
|
+ new class. (cdouglas via omalley)
|
|
|
+
|
|
|
+ HADOOP-4280. Fix conversions between seconds in C and milliseconds in
|
|
|
+ Java for access times for files. (Pete Wyckoff via rangadi)
|
|
|
+
|
|
|
+ HADOOP-4254. -setSpaceQuota command does not convert "TB" extenstion to
|
|
|
+ terabytes properly. Implementation now uses StringUtils for parsing this.
|
|
|
+ (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-4259. Findbugs should run over tools.jar also. (cdouglas via
|
|
|
+ omalley)
|
|
|
+
|
|
|
+ HADOOP-4275. Move public method isJobValidName from JobID to a private
|
|
|
+ method in JobTracker. (omalley)
|
|
|
+
|
|
|
+ HADOOP-4173. fix failures in TestProcfsBasedProcessTree and
|
|
|
+ TestTaskTrackerMemoryManager tests. ProcfsBasedProcessTree and
|
|
|
+ memory management in TaskTracker are disabled on Windows.
|
|
|
+ (Vinod K V via rangadi)
|
|
|
+
|
|
|
+ HADOOP-4189. Fixes the history blocksize & intertracker protocol version
|
|
|
+ issues introduced as part of HADOOP-3245. (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-4190. Fixes the backward compatibility issue with Job History.
|
|
|
+ introduced by HADOOP-3245 and HADOOP-2403. (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-4237. Fixes the TestStreamingBadRecords.testNarrowDown testcase.
|
|
|
+ (Sharad Agarwal via ddas)
|
|
|
+
|
|
|
+ HADOOP-4274. Capacity scheduler accidently modifies the underlying
|
|
|
+ data structures when browing the job lists. (Hemanth Yamijala via omalley)
|
|
|
+
|
|
|
+ HADOOP-4309. Fix eclipse-plugin compilation. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4232. Fix race condition in JVM reuse when multiple slots become
|
|
|
+ free. (ddas via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4302. Fix a race condition in TestReduceFetch that can yield false
|
|
|
+ negatvies. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3942. Update distcp documentation to include features introduced in
|
|
|
+ HADOOP-3873, HADOOP-3939. (Tsz Wo (Nicholas), SZE via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4319. fuse-dfs dfs_read function returns as many bytes as it is
|
|
|
+ told to read unlesss end-of-file is reached. (Pete Wyckoff via dhruba)
|
|
|
+
|
|
|
+ HADOOP-4246. Ensure we have the correct lower bound on the number of
|
|
|
+ retries for fetching map-outputs; also fixed the case where the reducer
|
|
|
+ automatically kills on too many unique map-outputs could not be fetched
|
|
|
+ for small jobs. (Amareshwari Sri Ramadasu via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4163. Report FSErrors from map output fetch threads instead of
|
|
|
+ merely logging them. (Sharad Agarwal via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4261. Adds a setup task for jobs. This is required so that we
|
|
|
+ don't setup jobs that haven't been inited yet (since init could lead
|
|
|
+ to job failure). Only after the init has successfully happened do we
|
|
|
+ launch the setupJob task. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-4256. Removes Completed and Failed Job tables from
|
|
|
+ jobqueue_details.jsp. (Sreekanth Ramakrishnan via ddas)
|
|
|
+
|
|
|
+ HADOOP-4267. Occasional exceptions during shutting down HSQLDB is logged
|
|
|
+ but not rethrown. (enis)
|
|
|
+
|
|
|
+ HADOOP-4018. The number of tasks for a single job cannot exceed a
|
|
|
+ pre-configured maximum value. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-4288. Fixes a NPE problem in CapacityScheduler.
|
|
|
+ (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-4014. Create hard links with 'fsutil hardlink' on Windows. (shv)
|
|
|
+
|
|
|
+ HADOOP-4393. Merged org.apache.hadoop.fs.permission.AccessControlException
|
|
|
+ and org.apache.hadoop.security.AccessControlIOException into a single
|
|
|
+ class hadoop.security.AccessControlException. (omalley via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4287. Fixes an issue to do with maintaining counts of running/pending
|
|
|
+ maps/reduces. (Sreekanth Ramakrishnan via ddas)
|
|
|
+
|
|
|
+ HADOOP-4361. Makes sure that jobs killed from command line are killed
|
|
|
+ fast (i.e., there is a slot to run the cleanup task soon).
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-4400. Add "hdfs://" to fs.default.name on quickstart.html.
|
|
|
+ (Jeff Hammerbacher via omalley)
|
|
|
+
|
|
|
+ HADOOP-4378. Fix TestJobQueueInformation to use SleepJob rather than
|
|
|
+ WordCount via TestMiniMRWithDFS. (Sreekanth Ramakrishnan via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4376. Fix formatting in hadoop-default.xml for
|
|
|
+ hadoop.http.filter.initializers. (Enis Soztutar via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4410. Adds an extra arg to the API FileUtil.makeShellPath to
|
|
|
+ determine whether to canonicalize file paths or not.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-4236. Ensure un-initialized jobs are killed correctly on
|
|
|
+ user-demand. (Sharad Agarwal via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4373. Fix calculation of Guaranteed Capacity for the
|
|
|
+ capacity-scheduler. (Hemanth Yamijala via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4053. Schedulers must be notified when jobs complete. (Amar Kamat via omalley)
|
|
|
+
|
|
|
+ HADOOP-4335. Fix FsShell -ls for filesystems without owners/groups. (David
|
|
|
+ Phillips via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4426. TestCapacityScheduler broke due to the two commits HADOOP-4053
|
|
|
+ and HADOOP-4373. This patch fixes that. (Hemanth Yamijala via ddas)
|
|
|
+
|
|
|
+ HADOOP-4418. Updates documentation in forrest for Mapred, streaming and pipes.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3155. Ensure that there is only one thread fetching
|
|
|
+ TaskCompletionEvents on TaskTracker re-init. (Dhruba Borthakur via
|
|
|
+ acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4425. Fix EditLogInputStream to overload the bulk read method.
|
|
|
+ (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4427. Adds the new queue/job commands to the manual.
|
|
|
+ (Sreekanth Ramakrishnan via ddas)
|
|
|
+
|
|
|
+ HADOOP-4278. Increase debug logging for unit test TestDatanodeDeath.
|
|
|
+ Fix the case when primary is dead. (dhruba via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4423. Keep block length when the block recovery is triggered by
|
|
|
+ append. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4449. Fix dfsadmin usage. (Raghu Angadi via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4455. Added TestSerDe so that unit tests can run successfully.
|
|
|
+ (Ashish Thusoo via dhruba)
|
|
|
+
|
|
|
+ HADOOP-4457. Fixes an input split logging problem introduced by
|
|
|
+ HADOOP-3245. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-4464. Separate out TestFileCreationClient from TestFileCreation.
|
|
|
+ (Tsz Wo (Nicholas), SZE via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4404. saveFSImage() removes files from a storage directory that do
|
|
|
+ not correspond to its type. (shv)
|
|
|
+
|
|
|
+ HADOOP-4149. Fix handling of updates to the job priority, by changing the
|
|
|
+ list of jobs to be keyed by the priority, submit time, and job tracker id.
|
|
|
+ (Amar Kamat via omalley)
|
|
|
+
|
|
|
+ HADOOP-4296. Fix job client failures by not retiring a job as soon as it
|
|
|
+ is finished. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-4439. Remove configuration variables that aren't usable yet, in
|
|
|
+ particular mapred.tasktracker.tasks.maxmemory and mapred.task.max.memory.
|
|
|
+ (Hemanth Yamijala via omalley)
|
|
|
+
|
|
|
+ HADOOP-4230. Fix for serde2 interface, limit operator, select * operator,
|
|
|
+ UDF trim functions and sampling. (Ashish Thusoo via dhruba)
|
|
|
+
|
|
|
+ HADOOP-4358. No need to truncate access time in INode. Also fixes NPE
|
|
|
+ in CreateEditsLog. (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-4387. TestHDFSFileSystemContract fails on windows nightly builds.
|
|
|
+ (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-4466. Ensure that SequenceFileOutputFormat isn't tied to Writables
|
|
|
+ and can be used with other Serialization frameworks. (Chris Wensel via
|
|
|
+ acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4525. Fix ipc.server.ipcnodelay originally missed in in HADOOP-2232.
|
|
|
+ (cdouglas via Clint Morgan)
|
|
|
+
|
|
|
+ HADOOP-4498. Ensure that JobHistory correctly escapes the job name so that
|
|
|
+ regex patterns work. (Chris Wensel via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4446. Modify guaranteed capacity labels in capacity scheduler's UI
|
|
|
+ to reflect the information being displayed. (Sreekanth Ramakrishnan via
|
|
|
+ yhemanth)
|
|
|
+
|
|
|
+ HADOOP-4282. Some user facing URLs are not filtered by user filters.
|
|
|
+ (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4595. Fixes two race conditions - one to do with updating free slot count,
|
|
|
+ and another to do with starting the MapEventsFetcher thread. (ddas)
|
|
|
+
|
|
|
+ HADOOP-4552. Fix a deadlock in RPC server. (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-4471. Sort running jobs by priority in the capacity scheduler.
|
|
|
+ (Amar Kamat via yhemanth)
|
|
|
+
|
|
|
+ HADOOP-4500. Fix MultiFileSplit to get the FileSystem from the relevant
|
|
|
+ path rather than the JobClient. (Joydeep Sen Sarma via cdouglas)
|
|
|
+
|
|
|
+Release 0.18.4 - Unreleased
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-5114. Remove timeout for accept() in DataNode. This makes accept()
|
|
|
+ fail in JDK on Windows and causes many tests to fail. (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-5192. Block receiver should not remove a block that's created or
|
|
|
+ being written by other threads. (hairong)
|
|
|
+
|
|
|
+ HADOOP-5134. FSNamesystem#commitBlockSynchronization adds under-construction
|
|
|
+ block locations to blocksMap. (Dhruba Borthakur via hairong)
|
|
|
+
|
|
|
+ HADOOP-5412. Simulated DataNode should not write to a block that's being
|
|
|
+ written by another thread. (hairong)
|
|
|
+
|
|
|
+ HADOOP-5465. Fix the problem of blocks remaining under-replicated by
|
|
|
+ providing synchronized modification to the counter xmitsInProgress in
|
|
|
+ DataNode. (hairong)
|
|
|
+
|
|
|
+ HADOOP-5557. Fixes some minor problems in TestOverReplicatedBlocks.
|
|
|
+ (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-5644. Namenode is stuck in safe mode. (suresh Srinivas via hairong)
|
|
|
+
|
|
|
+ HADOOP-6017. Lease Manager in NameNode does not handle certain characters
|
|
|
+ in filenames. This results in fatal errors in Secondary NameNode and while
|
|
|
+ restrating NameNode. (Tsz Wo (Nicholas), SZE via rangadi)
|
|
|
+
|
|
|
+Release 0.18.3 - 2009-01-27
|
|
|
+
|
|
|
+ IMPROVEMENTS
|
|
|
+
|
|
|
+ HADOOP-4150. Include librecordio in hadoop releases. (Giridharan Kesavan
|
|
|
+ via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4668. Improve documentation for setCombinerClass to clarify the
|
|
|
+ restrictions on combiners. (omalley)
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-4499. DFSClient should invoke checksumOk only once. (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-4597. Calculate mis-replicated blocks when safe-mode is turned
|
|
|
+ off manually. (shv)
|
|
|
+
|
|
|
+ HADOOP-3121. lsr should keep listing the remaining items but not
|
|
|
+ terminate if there is any IOException. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4610. Always calculate mis-replicated blocks when safe-mode is
|
|
|
+ turned off. (shv)
|
|
|
+
|
|
|
+ HADOOP-3883. Limit namenode to assign at most one generation stamp for
|
|
|
+ a particular block within a short period. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4556. Block went missing. (hairong)
|
|
|
+
|
|
|
+ HADOOP-4643. NameNode should exclude excessive replicas when counting
|
|
|
+ live replicas for a block. (hairong)
|
|
|
+
|
|
|
+ HADOOP-4703. Should not wait for proxy forever in lease recovering.
|
|
|
+ (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4647. NamenodeFsck should close the DFSClient it has created.
|
|
|
+ (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4616. Fuse-dfs can handle bad values from FileSystem.read call.
|
|
|
+ (Pete Wyckoff via dhruba)
|
|
|
+
|
|
|
+ HADOOP-4061. Throttle Datanode decommission monitoring in Namenode.
|
|
|
+ (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4659. Root cause of connection failure is being lost to code that
|
|
|
+ uses it for delaying startup. (Steve Loughran and Hairong via hairong)
|
|
|
+
|
|
|
+ HADOOP-4614. Lazily open segments when merging map spills to avoid using
|
|
|
+ too many file descriptors. (Yuri Pradkin via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4257. The DFS client should pick only one datanode as the candidate
|
|
|
+ to initiate lease recovery. (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-4713. Fix librecordio to handle records larger than 64k. (Christian
|
|
|
+ Kunz via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4635. Fix a memory leak in fuse dfs. (pete wyckoff via mahadev)
|
|
|
+
|
|
|
+ HADOOP-4714. Report status between merges and make the number of records
|
|
|
+ between progress reports configurable. (Jothi Padmanabhan via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4726. Fix documentation typos "the the". (Edward J. Yoon via
|
|
|
+ szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4679. Datanode prints tons of log messages: waiting for threadgroup
|
|
|
+ to exit, active threads is XX. (hairong)
|
|
|
+
|
|
|
+ HADOOP-4746. Job output directory should be normalized. (hairong)
|
|
|
+
|
|
|
+ HADOOP-4717. Removal of default port# in NameNode.getUri() causes a
|
|
|
+ map/reduce job failed to prompt temporary output. (hairong)
|
|
|
+
|
|
|
+ HADOOP-4778. Check for zero size block meta file when updating a block.
|
|
|
+ (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4742. Replica gets deleted by mistake. (Wang Xu via hairong)
|
|
|
+
|
|
|
+ HADOOP-4702. Failed block replication leaves an incomplete block in
|
|
|
+ receiver's tmp data directory. (hairong)
|
|
|
+
|
|
|
+ HADOOP-4613. Fix block browsing on Web UI. (Johan Oskarsson via shv)
|
|
|
+
|
|
|
+ HADOOP-4806. HDFS rename should not use src path as a regular expression.
|
|
|
+ (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4795. Prevent lease monitor getting into an infinite loop when
|
|
|
+ leases and the namespace tree does not match. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4620. Fixes Streaming to handle well the cases of map/reduce with empty
|
|
|
+ input/output. (Ravi Gummadi via ddas)
|
|
|
+
|
|
|
+ HADOOP-4857. Fixes TestUlimit to have exactly 1 map in the jobs spawned.
|
|
|
+ (Ravi Gummadi via ddas)
|
|
|
+
|
|
|
+ HADOOP-4810. Data lost at cluster startup time. (hairong)
|
|
|
+
|
|
|
+ HADOOP-4797. Improve how RPC server reads and writes large buffers. Avoids
|
|
|
+ soft-leak of direct buffers and excess copies in NIO layer. (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-4840. TestNodeCount sometimes fails with NullPointerException.
|
|
|
+ (hairong)
|
|
|
+
|
|
|
+ HADOOP-4904. Fix deadlock while leaving safe mode. (shv)
|
|
|
+
|
|
|
+ HADOOP-1980. 'dfsadmin -safemode enter' should prevent the namenode from
|
|
|
+ leaving safemode automatically. (shv & Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-4951. Lease monitor should acquire the LeaseManager lock but not the
|
|
|
+ Monitor lock. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4935. processMisReplicatedBlocks() should not clear
|
|
|
+ excessReplicateMap. (shv)
|
|
|
+
|
|
|
+ HADOOP-4961. Fix ConcurrentModificationException in lease recovery
|
|
|
+ of empty files. (shv)
|
|
|
+
|
|
|
+ HADOOP-4971. A long (unexpected) delay at datanodes could make subsequent
|
|
|
+ block reports from many datanode at the same time. (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-4910. NameNode should exclude replicas when choosing excessive
|
|
|
+ replicas to delete to avoid data lose. (hairong)
|
|
|
+
|
|
|
+ HADOOP-4983. Fixes a problem in updating Counters in the status reporting.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+Release 0.18.2 - 2008-11-03
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-3614. Fix a bug that Datanode may use an old GenerationStamp to get
|
|
|
+ meta file. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4314. Simulated datanodes should not include blocks that are still
|
|
|
+ being written in their block report. (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-4228. dfs datanode metrics, bytes_read and bytes_written, overflow
|
|
|
+ due to incorrect type used. (hairong)
|
|
|
+
|
|
|
+ HADOOP-4395. The FSEditLog loading is incorrect for the case OP_SET_OWNER.
|
|
|
+ (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4351. FSNamesystem.getBlockLocationsInternal throws
|
|
|
+ ArrayIndexOutOfBoundsException. (hairong)
|
|
|
+
|
|
|
+ HADOOP-4403. Make TestLeaseRecovery and TestFileCreation more robust.
|
|
|
+ (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4292. Do not support append() for LocalFileSystem. (hairong)
|
|
|
+
|
|
|
+ HADOOP-4399. Make fuse-dfs multi-thread access safe.
|
|
|
+ (Pete Wyckoff via dhruba)
|
|
|
+
|
|
|
+ HADOOP-4369. Use setMetric(...) instead of incrMetric(...) for metrics
|
|
|
+ averages. (Brian Bockelman via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4469. Rename and add the ant task jar file to the tar file. (nigel)
|
|
|
+
|
|
|
+ HADOOP-3914. DFSClient sends Checksum Ok only once for a block.
|
|
|
+ (Christian Kunz via hairong)
|
|
|
+
|
|
|
+ HADOOP-4467. SerializationFactory now uses the current context ClassLoader
|
|
|
+ allowing for user supplied Serialization instances. (Chris Wensel via
|
|
|
+ acmurthy)
|
|
|
+
|
|
|
+ HADOOP-4517. Release FSDataset lock before joining ongoing create threads.
|
|
|
+ (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4526. fsck failing with NullPointerException. (hairong)
|
|
|
+
|
|
|
+ HADOOP-4483 Honor the max parameter in DatanodeDescriptor.getBlockArray(..)
|
|
|
+ (Ahad Rana and Hairong Kuang via szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4340. Correctly set the exit code from JobShell.main so that the
|
|
|
+ 'hadoop jar' command returns the right code to the user. (acmurthy)
|
|
|
+
|
|
|
+ NEW FEATURES
|
|
|
+
|
|
|
+ HADOOP-2421. Add jdiff output to documentation, listing all API
|
|
|
+ changes from the prior release. (cutting)
|
|
|
+
|
|
|
+Release 0.18.1 - 2008-09-17
|
|
|
+
|
|
|
+ IMPROVEMENTS
|
|
|
+
|
|
|
+ HADOOP-3934. Upgrade log4j to 1.2.15. (omalley)
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-3995. In case of quota failure on HDFS, rename does not restore
|
|
|
+ source filename. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-3821. Prevent SequenceFile and IFile from duplicating codecs in
|
|
|
+ CodecPool when closed more than once. (Arun Murthy via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-4040. Remove coded default of the IPC idle connection timeout
|
|
|
+ from the TaskTracker, which was causing HDFS client connections to not be
|
|
|
+ collected. (ddas via omalley)
|
|
|
+
|
|
|
+ HADOOP-4046. Made WritableComparable's constructor protected instead of
|
|
|
+ private to re-enable class derivation. (cdouglas via omalley)
|
|
|
+
|
|
|
+ HADOOP-3940. Fix in-memory merge condition to wait when there are no map
|
|
|
+ outputs or when the final map outputs are being fetched without contention.
|
|
|
+ (cdouglas)
|
|
|
+
|
|
|
+Release 0.18.0 - 2008-08-19
|
|
|
+
|
|
|
+ INCOMPATIBLE CHANGES
|
|
|
+
|
|
|
+ HADOOP-2703. The default options to fsck skips checking files
|
|
|
+ that are being written to. The output of fsck is incompatible
|
|
|
+ with previous release. (lohit vijayarenu via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2865. FsShell.ls() printout format changed to print file names
|
|
|
+ in the end of the line. (Edward J. Yoon via shv)
|
|
|
+
|
|
|
+ HADOOP-3283. The Datanode has a RPC server. It currently supports
|
|
|
+ two RPCs: the first RPC retrives the metadata about a block and the
|
|
|
+ second RPC sets the generation stamp of an existing block.
|
|
|
+ (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2797. Code related to upgrading to 0.14 (Block CRCs) is
|
|
|
+ removed. As result, upgrade to 0.18 or later from 0.13 or earlier
|
|
|
+ is not supported. If upgrading from 0.13 or earlier is required,
|
|
|
+ please upgrade to an intermediate version (0.14-0.17) and then
|
|
|
+ to this version. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-544. This issue introduces new classes JobID, TaskID and
|
|
|
+ TaskAttemptID, which should be used instead of their string counterparts.
|
|
|
+ Functions in JobClient, TaskReport, RunningJob, jobcontrol.Job and
|
|
|
+ TaskCompletionEvent that use string arguments are deprecated in favor
|
|
|
+ of the corresponding ones that use ID objects. Applications can use
|
|
|
+ xxxID.toString() and xxxID.forName() methods to convert/restore objects
|
|
|
+ to/from strings. (Enis Soztutar via ddas)
|
|
|
+
|
|
|
+ HADOOP-2188. RPC client sends a ping rather than throw timeouts.
|
|
|
+ RPC server does not throw away old RPCs. If clients and the server are on
|
|
|
+ different versions, they are not able to function well. In addition,
|
|
|
+ The property ipc.client.timeout is removed from the default hadoop
|
|
|
+ configuration. It also removes metrics RpcOpsDiscardedOPsNum. (hairong)
|
|
|
+
|
|
|
+ HADOOP-2181. This issue adds logging for input splits in Jobtracker log
|
|
|
+ and jobHistory log. Also adds web UI for viewing input splits in job UI
|
|
|
+ and history UI. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3226. Run combiners multiple times over map outputs as they
|
|
|
+ are merged in both the map and the reduce tasks. (cdouglas via omalley)
|
|
|
+
|
|
|
+ HADOOP-3329. DatanodeDescriptor objects should not be stored in the
|
|
|
+ fsimage. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-2656. The Block object has a generation stamp inside it.
|
|
|
+ Existing blocks get a generation stamp of 0. This is needed to support
|
|
|
+ appends. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-3390. Removed deprecated ClientProtocol.abandonFileInProgress().
|
|
|
+ (Tsz Wo (Nicholas), SZE via rangadi)
|
|
|
+
|
|
|
+ HADOOP-3405. Made some map/reduce internal classes non-public:
|
|
|
+ MapTaskStatus, ReduceTaskStatus, JobSubmissionProtocol,
|
|
|
+ CompletedJobStatusStore. (enis via omaley)
|
|
|
+
|
|
|
+ HADOOP-3265. Removed depcrecated API getFileCacheHints().
|
|
|
+ (Lohit Vijayarenu via rangadi)
|
|
|
+
|
|
|
+ HADOOP-3310. The namenode instructs the primary datanode to do lease
|
|
|
+ recovery. The block gets a new generation stamp.
|
|
|
+ (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2909. Improve IPC idle connection management. Property
|
|
|
+ ipc.client.maxidletime is removed from the default configuration,
|
|
|
+ instead it is defined as twice of the ipc.client.connection.maxidletime.
|
|
|
+ A connection with outstanding requests won't be treated as idle.
|
|
|
+ (hairong)
|
|
|
+
|
|
|
+ HADOOP-3459. Change in the output format of dfs -ls to more closely match
|
|
|
+ /bin/ls. New format is: perm repl owner group size date name
|
|
|
+ (Mukund Madhugiri via omally)
|
|
|
+
|
|
|
+ HADOOP-3113. An fsync invoked on a HDFS file really really
|
|
|
+ persists data! The datanode moves blocks in the tmp directory to
|
|
|
+ the real block directory on a datanode-restart. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-3452. Change fsck to return non-zero status for a corrupt
|
|
|
+ FileSystem. (lohit vijayarenu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3193. Include the address of the client that found the corrupted
|
|
|
+ block in the log. Also include a CorruptedBlocks metric to track the size
|
|
|
+ of the corrupted block map. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3512. Separate out the tools into a tools jar. (omalley)
|
|
|
+
|
|
|
+ HADOOP-3598. Ensure that temporary task-output directories are not created
|
|
|
+ if they are not necessary e.g. for Maps with no side-effect files.
|
|
|
+ (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-3665. Modify WritableComparator so that it only creates instances
|
|
|
+ of the keytype if the type does not define a WritableComparator. Calling
|
|
|
+ the superclass compare will throw a NullPointerException. Also define
|
|
|
+ a RawComparator for NullWritable and permit it to be written as a key
|
|
|
+ to SequenceFiles. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3673. Avoid deadlock caused by DataNode RPC receoverBlock().
|
|
|
+ (Tsz Wo (Nicholas), SZE via rangadi)
|
|
|
+
|
|
|
+ NEW FEATURES
|
|
|
+
|
|
|
+ HADOOP-3074. Provides a UrlStreamHandler for DFS and other FS,
|
|
|
+ relying on FileSystem (taton)
|
|
|
+
|
|
|
+ HADOOP-2585. Name-node imports namespace data from a recent checkpoint
|
|
|
+ accessible via a NFS mount. (shv)
|
|
|
+
|
|
|
+ HADOOP-3061. Writable types for doubles and bytes. (Andrzej
|
|
|
+ Bialecki via omalley)
|
|
|
+
|
|
|
+ HADOOP-2857. Allow libhdfs to set jvm options. (Craig Macdonald
|
|
|
+ via omalley)
|
|
|
+
|
|
|
+ HADOOP-3317. Add default port for HDFS namenode. The port in
|
|
|
+ "hdfs:" URIs now defaults to 8020, so that one may simply use URIs
|
|
|
+ of the form "hdfs://example.com/dir/file". (cutting)
|
|
|
+
|
|
|
+ HADOOP-2019. Adds support for .tar, .tgz and .tar.gz files in
|
|
|
+ DistributedCache (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3058. Add FSNamesystem status metrics.
|
|
|
+ (Lohit Vjayarenu via rangadi)
|
|
|
+
|
|
|
+ HADOOP-1915. Allow users to specify counters via strings instead
|
|
|
+ of enumerations. (tomwhite via omalley)
|
|
|
+
|
|
|
+ HADOOP-2065. Delay invalidating corrupt replicas of block until its
|
|
|
+ is removed from under replicated state. If all replicas are found to
|
|
|
+ be corrupt, retain all copies and mark the block as corrupt.
|
|
|
+ (Lohit Vjayarenu via rangadi)
|
|
|
+
|
|
|
+ HADOOP-3221. Adds org.apache.hadoop.mapred.lib.NLineInputFormat, which
|
|
|
+ splits files into splits each of N lines. N can be specified by
|
|
|
+ configuration property "mapred.line.input.format.linespermap", which
|
|
|
+ defaults to 1. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3336. Direct a subset of annotated FSNamesystem calls for audit
|
|
|
+ logging. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3400. A new API FileSystem.deleteOnExit() that facilitates
|
|
|
+ handling of temporary files in HDFS. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-4. Add fuse-dfs to contrib, permitting one to mount an
|
|
|
+ HDFS filesystem on systems that support FUSE, e.g., Linux.
|
|
|
+ (Pete Wyckoff via cutting)
|
|
|
+
|
|
|
+ HADOOP-3246. Add FTPFileSystem. (Ankur Goel via cutting)
|
|
|
+
|
|
|
+ HADOOP-3250. Extend FileSystem API to allow appending to files.
|
|
|
+ (Tsz Wo (Nicholas), SZE via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3177. Implement Syncable interface for FileSystem.
|
|
|
+ (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1328. Implement user counters in streaming. (tomwhite via
|
|
|
+ omalley)
|
|
|
+
|
|
|
+ HADOOP-3187. Quotas for namespace management. (Hairong Kuang via ddas)
|
|
|
+
|
|
|
+ HADOOP-3307. Support for Archives in Hadoop. (Mahadev Konar via ddas)
|
|
|
+
|
|
|
+ HADOOP-3460. Add SequenceFileAsBinaryOutputFormat to permit direct
|
|
|
+ writes of serialized data. (Koji Noguchi via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3230. Add ability to get counter values from command
|
|
|
+ line. (tomwhite via omalley)
|
|
|
+
|
|
|
+ HADOOP-930. Add support for native S3 files. (tomwhite via cutting)
|
|
|
+
|
|
|
+ HADOOP-3502. Quota API needs documentation in Forrest. (hairong)
|
|
|
+
|
|
|
+ HADOOP-3413. Allow SequenceFile.Reader to use serialization
|
|
|
+ framework. (tomwhite via omalley)
|
|
|
+
|
|
|
+ HADOOP-3541. Import of the namespace from a checkpoint documented
|
|
|
+ in hadoop user guide. (shv)
|
|
|
+
|
|
|
+ IMPROVEMENTS
|
|
|
+
|
|
|
+ HADOOP-3677. Simplify generation stamp upgrade by making is a
|
|
|
+ local upgrade on datandodes. Deleted distributed upgrade.
|
|
|
+ (rangadi)
|
|
|
+
|
|
|
+ HADOOP-2928. Remove deprecated FileSystem.getContentLength().
|
|
|
+ (Lohit Vijayarenu via rangadi)
|
|
|
+
|
|
|
+ HADOOP-3130. Make the connect timeout smaller for getFile.
|
|
|
+ (Amar Ramesh Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-3160. Remove deprecated exists() from ClientProtocol and
|
|
|
+ FSNamesystem (Lohit Vjayarenu via rangadi)
|
|
|
+
|
|
|
+ HADOOP-2910. Throttle IPC Clients during bursts of requests or
|
|
|
+ server slowdown. Clients retry connection for up to 15 minutes
|
|
|
+ when socket connection times out. (hairong)
|
|
|
+
|
|
|
+ HADOOP-3295. Allow TextOutputFormat to use configurable spearators.
|
|
|
+ (Zheng Shao via cdouglas).
|
|
|
+
|
|
|
+ HADOOP-3308. Improve QuickSort by excluding values eq the pivot from the
|
|
|
+ partition. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2461. Trim property names in configuration.
|
|
|
+ (Tsz Wo (Nicholas), SZE via shv)
|
|
|
+
|
|
|
+ HADOOP-2799. Deprecate o.a.h.io.Closable in favor of java.io.Closable.
|
|
|
+ (Tsz Wo (Nicholas), SZE via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3345. Enhance the hudson-test-patch target to cleanup messages,
|
|
|
+ fix minor defects, and add eclipse plugin and python unit tests. (nigel)
|
|
|
+
|
|
|
+ HADOOP-3144. Improve robustness of LineRecordReader by defining a maximum
|
|
|
+ line length (mapred.linerecordreader.maxlength), thereby avoiding reading
|
|
|
+ too far into the following split. (Zheng Shao via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3334. Move lease handling from FSNamesystem into a seperate class.
|
|
|
+ (Tsz Wo (Nicholas), SZE via rangadi)
|
|
|
+
|
|
|
+ HADOOP-3332. Reduces the amount of logging in Reducer's shuffle phase.
|
|
|
+ (Devaraj Das)
|
|
|
+
|
|
|
+ HADOOP-3355. Enhances Configuration class to accept hex numbers for getInt
|
|
|
+ and getLong. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3350. Add an argument to distcp to permit the user to limit the
|
|
|
+ number of maps. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3013. Add corrupt block reporting to fsck.
|
|
|
+ (lohit vijayarenu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3377. Remove TaskRunner::replaceAll and replace with equivalent
|
|
|
+ String::replace. (Brice Arnould via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3398. Minor improvement to a utility function in that participates
|
|
|
+ in backoff calculation. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3381. Clear referenced when directories are deleted so that
|
|
|
+ effect of memory leaks are not multiplied. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-2867. Adds the task's CWD to its LD_LIBRARY_PATH.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3232. DU class runs the 'du' command in a seperate thread so
|
|
|
+ that it does not block user. DataNode misses heartbeats in large
|
|
|
+ nodes otherwise. (Johan Oskarsson via rangadi)
|
|
|
+
|
|
|
+ HADOOP-3035. During block transfers between datanodes, the receiving
|
|
|
+ datanode, now can report corrupt replicas received from src node to
|
|
|
+ the namenode. (Lohit Vijayarenu via rangadi)
|
|
|
+
|
|
|
+ HADOOP-3434. Retain the cause of the bind failure in Server::bind.
|
|
|
+ (Steve Loughran via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3429. Increases the size of the buffers used for the communication
|
|
|
+ for Streaming jobs. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3486. Change default for initial block report to 0 seconds
|
|
|
+ and document it. (Sanjay Radia via omalley)
|
|
|
+
|
|
|
+ HADOOP-3448. Improve the text in the assertion making sure the
|
|
|
+ layout versions are consistent in the data node. (Steve Loughran
|
|
|
+ via omalley)
|
|
|
+
|
|
|
+ HADOOP-2095. Improve the Map-Reduce shuffle/merge by cutting down
|
|
|
+ buffer-copies; changed intermediate sort/merge to use the new IFile format
|
|
|
+ rather than SequenceFiles and compression of map-outputs is now
|
|
|
+ implemented by compressing the entire file rather than SequenceFile
|
|
|
+ compression. Shuffle also has been changed to use a simple byte-buffer
|
|
|
+ manager rather than the InMemoryFileSystem.
|
|
|
+ Configuration changes to hadoop-default.xml:
|
|
|
+ deprecated mapred.map.output.compression.type
|
|
|
+ (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-236. JobTacker now refuses connection from a task tracker with a
|
|
|
+ different version number. (Sharad Agarwal via ddas)
|
|
|
+
|
|
|
+ HADOOP-3427. Improves the shuffle scheduler. It now waits for notifications
|
|
|
+ from shuffle threads when it has scheduled enough, before scheduling more.
|
|
|
+ (ddas)
|
|
|
+
|
|
|
+ HADOOP-2393. Moves the handling of dir deletions in the tasktracker to
|
|
|
+ a separate thread. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3501. Deprecate InMemoryFileSystem. (cutting via omalley)
|
|
|
+
|
|
|
+ HADOOP-3366. Stall the shuffle while in-memory merge is in progress.
|
|
|
+ (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2916. Refactor src structure, but leave package structure alone.
|
|
|
+ (Raghu Angadi via mukund)
|
|
|
+
|
|
|
+ HADOOP-3492. Add forrest documentation for user archives.
|
|
|
+ (Mahadev Konar via hairong)
|
|
|
+
|
|
|
+ HADOOP-3467. Improve documentation for FileSystem::deleteOnExit.
|
|
|
+ (Tsz Wo (Nicholas), SZE via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3379. Documents stream.non.zero.exit.status.is.failure for Streaming.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3096. Improves documentation about the Task Execution Environment in
|
|
|
+ the Map-Reduce tutorial. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2984. Add forrest documentation for DistCp. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3406. Add forrest documentation for Profiling.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2762. Add forrest documentation for controls of memory limits on
|
|
|
+ hadoop daemons and Map-Reduce tasks. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3535. Fix documentation and name of IOUtils.close to
|
|
|
+ reflect that it should only be used in cleanup contexts. (omalley)
|
|
|
+
|
|
|
+ HADOOP-3593. Updates the mapred tutorial. (ddas)
|
|
|
+
|
|
|
+ HADOOP-3547. Documents the way in which native libraries can be distributed
|
|
|
+ via the DistributedCache. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3606. Updates the Streaming doc. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3532. Add jdiff reports to the build scripts. (omalley)
|
|
|
+
|
|
|
+ HADOOP-3100. Develop tests to test the DFS command line interface. (mukund)
|
|
|
+
|
|
|
+ HADOOP-3688. Fix up HDFS docs. (Robert Chansler via hairong)
|
|
|
+
|
|
|
+ OPTIMIZATIONS
|
|
|
+
|
|
|
+ HADOOP-3274. The default constructor of BytesWritable creates empty
|
|
|
+ byte array. (Tsz Wo (Nicholas), SZE via shv)
|
|
|
+
|
|
|
+ HADOOP-3272. Remove redundant copy of Block object in BlocksMap.
|
|
|
+ (Lohit Vjayarenu via shv)
|
|
|
+
|
|
|
+ HADOOP-3164. Reduce DataNode CPU usage by using FileChannel.tranferTo().
|
|
|
+ On Linux DataNode takes 5 times less CPU while serving data. Results may
|
|
|
+ vary on other platforms. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-3248. Optimization of saveFSImage. (Dhruba via shv)
|
|
|
+
|
|
|
+ HADOOP-3297. Fetch more task completion events from the job
|
|
|
+ tracker and task tracker. (ddas via omalley)
|
|
|
+
|
|
|
+ HADOOP-3364. Faster image and log edits loading. (shv)
|
|
|
+
|
|
|
+ HADOOP-3369. Fast block processing during name-node startup. (shv)
|
|
|
+
|
|
|
+ HADOOP-1702. Reduce buffer copies when data is written to DFS.
|
|
|
+ DataNodes take 30% less CPU while writing data. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-3095. Speed up split generation in the FileInputSplit,
|
|
|
+ especially for non-HDFS file systems. Deprecates
|
|
|
+ InputFormat.validateInput. (tomwhite via omalley)
|
|
|
+
|
|
|
+ HADOOP-3552. Add forrest documentation for Hadoop commands.
|
|
|
+ (Sharad Agarwal via cdouglas)
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-2905. 'fsck -move' triggers NPE in NameNode.
|
|
|
+ (Lohit Vjayarenu via rangadi)
|
|
|
+
|
|
|
+ Increment ClientProtocol.versionID missed by HADOOP-2585. (shv)
|
|
|
+
|
|
|
+ HADOOP-3254. Restructure internal namenode methods that process
|
|
|
+ heartbeats to use well-defined BlockCommand object(s) instead of
|
|
|
+ using the base java Object. (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-3176. Change lease record when a open-for-write-file
|
|
|
+ gets renamed. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-3269. Fix a case when namenode fails to restart
|
|
|
+ while processing a lease record. ((Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-3282. Port issues in TestCheckpoint resolved. (shv)
|
|
|
+
|
|
|
+ HADOOP-3268. file:// URLs issue in TestUrlStreamHandler under Windows.
|
|
|
+ (taton)
|
|
|
+
|
|
|
+ HADOOP-3127. Deleting files in trash should really remove them.
|
|
|
+ (Brice Arnould via omalley)
|
|
|
+
|
|
|
+ HADOOP-3300. Fix locking of explicit locks in NetworkTopology.
|
|
|
+ (tomwhite via omalley)
|
|
|
+
|
|
|
+ HADOOP-3270. Constant DatanodeCommands are stored in static final
|
|
|
+ immutable variables for better code clarity.
|
|
|
+ (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2793. Fix broken links for worst performing shuffle tasks in
|
|
|
+ the job history page. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3313. Avoid unnecessary calls to System.currentTimeMillis
|
|
|
+ in RPC::Invoker. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3318. Recognize "Darwin" as an alias for "Mac OS X" to
|
|
|
+ support Soylatte. (Sam Pullara via omalley)
|
|
|
+
|
|
|
+ HADOOP-3301. Fix misleading error message when S3 URI hostname
|
|
|
+ contains an underscore. (tomwhite via omalley)
|
|
|
+
|
|
|
+ HADOOP-3338. Fix Eclipse plugin to compile after HADOOP-544 was
|
|
|
+ committed. Updated all references to use the new JobID representation.
|
|
|
+ (taton via nigel)
|
|
|
+
|
|
|
+ HADOOP-3337. Loading FSEditLog was broken by HADOOP-3283 since it
|
|
|
+ changed Writable serialization of DatanodeInfo. This patch handles it.
|
|
|
+ (Tsz Wo (Nicholas), SZE via rangadi)
|
|
|
+
|
|
|
+ HADOOP-3101. Prevent JobClient from throwing an exception when printing
|
|
|
+ usage. (Edward J. Yoon via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3119. Update javadoc for Text::getBytes to better describe its
|
|
|
+ behavior. (Tim Nelson via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2294. Fix documentation in libhdfs to refer to the correct free
|
|
|
+ function. (Craig Macdonald via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3335. Prevent the libhdfs build from deleting the wrong
|
|
|
+ files on make clean. (cutting via omalley)
|
|
|
+
|
|
|
+ HADOOP-2930. Make {start,stop}-balancer.sh work even if hadoop-daemon.sh
|
|
|
+ is not in the PATH. (Spiros Papadimitriou via hairong)
|
|
|
+
|
|
|
+ HADOOP-3085. Catch Exception in metrics util classes to ensure that
|
|
|
+ misconfigured metrics don't prevent others from updating. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3299. CompositeInputFormat should configure the sub-input
|
|
|
+ formats. (cdouglas via omalley)
|
|
|
+
|
|
|
+ HADOOP-3309. Lower io.sort.mb and fs.inmemory.size.mb for MiniMRDFSSort
|
|
|
+ unit test so it passes on Windows. (lohit vijayarenu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3348. TestUrlStreamHandler should set URLStreamFactory after
|
|
|
+ DataNodes are initialized. (Lohit Vijayarenu via rangadi)
|
|
|
+
|
|
|
+ HADOOP-3371. Ignore InstanceAlreadyExistsException from
|
|
|
+ MBeanUtil::registerMBean. (lohit vijayarenu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3349. A file rename was incorrectly changing the name inside a
|
|
|
+ lease record. (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-3365. Removes an unnecessary copy of the key from SegmentDescriptor
|
|
|
+ to MergeQueue. (Devaraj Das)
|
|
|
+
|
|
|
+ HADOOP-3388. Fix for TestDatanodeBlockScanner to handle blocks with
|
|
|
+ generation stamps in them. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-3203. Fixes TaskTracker::localizeJob to pass correct file sizes
|
|
|
+ for the jarfile and the jobfile. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3391. Fix a findbugs warning introduced by HADOOP-3248 (rangadi)
|
|
|
+
|
|
|
+ HADOOP-3393. Fix datanode shutdown to call DataBlockScanner::shutdown and
|
|
|
+ close its log, even if the scanner thread is not running. (lohit vijayarenu
|
|
|
+ via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3399. A debug message was logged at info level. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-3396. TestDatanodeBlockScanner occationally fails.
|
|
|
+ (Lohit Vijayarenu via rangadi)
|
|
|
+
|
|
|
+ HADOOP-3339. Some of the failures on 3rd datanode in DFS write pipelie
|
|
|
+ are not detected properly. This could lead to hard failure of client's
|
|
|
+ write operation. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-3409. Namenode should save the root inode into fsimage. (hairong)
|
|
|
+
|
|
|
+ HADOOP-3296. Fix task cache to work for more than two levels in the cache
|
|
|
+ hierarchy. This also adds a new counter to track cache hits at levels
|
|
|
+ greater than two. (Amar Kamat via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3375. Lease paths were sometimes not removed from
|
|
|
+ LeaseManager.sortedLeasesByPath. (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-3424. Values returned by getPartition should be checked to
|
|
|
+ make sure they are in the range 0 to #reduces - 1 (cdouglas via
|
|
|
+ omalley)
|
|
|
+
|
|
|
+ HADOOP-3408. Change FSNamesystem to send its metrics as integers to
|
|
|
+ accommodate collectors that don't support long values. (lohit vijayarenu
|
|
|
+ via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3403. Fixes a problem in the JobTracker to do with handling of lost
|
|
|
+ tasktrackers. (Arun Murthy via ddas)
|
|
|
+
|
|
|
+ HADOOP-1318. Completed maps are not failed if the number of reducers are
|
|
|
+ zero. (Amareshwari Sriramadasu via ddas).
|
|
|
+
|
|
|
+ HADOOP-3351. Fixes the history viewer tool to not do huge StringBuffer
|
|
|
+ allocations. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3419. Fixes TestFsck to wait for updates to happen before
|
|
|
+ checking results to make the test more reliable. (Lohit Vijaya
|
|
|
+ Renu via omalley)
|
|
|
+
|
|
|
+ HADOOP-3259. Makes failure to read system properties due to a
|
|
|
+ security manager non-fatal. (Edward Yoon via omalley)
|
|
|
+
|
|
|
+ HADOOP-3451. Update libhdfs to use FileSystem::getFileBlockLocations
|
|
|
+ instead of removed getFileCacheHints. (lohit vijayarenu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3401. Update FileBench to set the new
|
|
|
+ "mapred.work.output.dir" property to work post-3041. (cdouglas via omalley)
|
|
|
+
|
|
|
+ HADOOP-2669. DFSClient locks pendingCreates appropriately. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-3410. Fix KFS implemenation to return correct file
|
|
|
+ modification time. (Sriram Rao via cutting)
|
|
|
+
|
|
|
+ HADOOP-3340. Fix DFS metrics for BlocksReplicated, HeartbeatsNum, and
|
|
|
+ BlockReportsAverageTime. (lohit vijayarenu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3435. Remove the assuption in the scripts that bash is at
|
|
|
+ /bin/bash and fix the test patch to require bash instead of sh.
|
|
|
+ (Brice Arnould via omalley)
|
|
|
+
|
|
|
+ HADOOP-3471. Fix spurious errors from TestIndexedSort and add additional
|
|
|
+ logging to let failures be reproducible. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3443. Avoid copying map output across partitions when renaming a
|
|
|
+ single spill. (omalley via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3454. Fix Text::find to search only valid byte ranges. (Chad Whipkey
|
|
|
+ via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3417. Removes the static configuration variable,
|
|
|
+ commandLineConfig from JobClient. Moves the cli parsing from
|
|
|
+ JobShell to GenericOptionsParser. Thus removes the class
|
|
|
+ org.apache.hadoop.mapred.JobShell. (Amareshwari Sriramadasu via
|
|
|
+ ddas)
|
|
|
+
|
|
|
+ HADOOP-2132. Only RUNNING/PREP jobs can be killed. (Jothi Padmanabhan
|
|
|
+ via ddas)
|
|
|
+
|
|
|
+ HADOOP-3476. Code cleanup in fuse-dfs.
|
|
|
+ (Peter Wyckoff via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2427. Ensure that the cwd of completed tasks is cleaned-up
|
|
|
+ correctly on task-completion. (Amareshwari Sri Ramadasu via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2565. Remove DFSPath cache of FileStatus.
|
|
|
+ (Tsz Wo (Nicholas), SZE via hairong)
|
|
|
+
|
|
|
+ HADOOP-3326. Cleanup the local-fs and in-memory merge in the ReduceTask by
|
|
|
+ spawing only one thread each for the on-disk and in-memory merge.
|
|
|
+ (Sharad Agarwal via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-3493. Fix TestStreamingFailure to use FileUtil.fullyDelete to
|
|
|
+ ensure correct cleanup. (Lohit Vijayarenu via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-3455. Fix NPE in ipc.Client in case of connection failure and
|
|
|
+ improve its synchronization. (hairong)
|
|
|
+
|
|
|
+ HADOOP-3240. Fix a testcase to not create files in the current directory.
|
|
|
+ Instead the file is created in the test directory (Mahadev Konar via ddas)
|
|
|
+
|
|
|
+ HADOOP-3496. Fix failure in TestHarFileSystem.testArchives due to change
|
|
|
+ in HADOOP-3095. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-3135. Get the system directory from the JobTracker instead of from
|
|
|
+ the conf. (Subramaniam Krishnan via ddas)
|
|
|
+
|
|
|
+ HADOOP-3503. Fix a race condition when client and namenode start
|
|
|
+ simultaneous recovery of the same block. (dhruba & Tsz Wo
|
|
|
+ (Nicholas), SZE)
|
|
|
+
|
|
|
+ HADOOP-3440. Fixes DistributedCache to not create symlinks for paths which
|
|
|
+ don't have fragments even when createSymLink is true.
|
|
|
+ (Abhijit Bagri via ddas)
|
|
|
+
|
|
|
+ HADOOP-3463. Hadoop-daemons script should cd to $HADOOP_HOME. (omalley)
|
|
|
+
|
|
|
+ HADOOP-3489. Fix NPE in SafeModeMonitor. (Lohit Vijayarenu via shv)
|
|
|
+
|
|
|
+ HADOOP-3509. Fix NPE in FSNamesystem.close. (Tsz Wo (Nicholas), SZE via
|
|
|
+ shv)
|
|
|
+
|
|
|
+ HADOOP-3491. Name-node shutdown causes InterruptedException in
|
|
|
+ ResolutionMonitor. (Lohit Vijayarenu via shv)
|
|
|
+
|
|
|
+ HADOOP-3511. Fixes namenode image to not set the root's quota to an
|
|
|
+ invalid value when the quota was not saved in the image. (hairong)
|
|
|
+
|
|
|
+ HADOOP-3516. Ensure the JobClient in HadoopArchives is initialized
|
|
|
+ with a configuration. (Subramaniam Krishnan via omalley)
|
|
|
+
|
|
|
+ HADOOP-3513. Improve NNThroughputBenchmark log messages. (shv)
|
|
|
+
|
|
|
+ HADOOP-3519. Fix NPE in DFS FileSystem rename. (hairong via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-3528. Metrics FilesCreated and files_deleted metrics
|
|
|
+ do not match. (Lohit via Mahadev)
|
|
|
+
|
|
|
+ HADOOP-3418. When a directory is deleted, any leases that point to files
|
|
|
+ in the subdirectory are removed. ((Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-3542. Diables the creation of _logs directory for the archives
|
|
|
+ directory. (Mahadev Konar via ddas)
|
|
|
+
|
|
|
+ HADOOP-3544. Fixes a documentation issue for hadoop archives.
|
|
|
+ (Mahadev Konar via ddas)
|
|
|
+
|
|
|
+ HADOOP-3517. Fixes a problem in the reducer due to which the last InMemory
|
|
|
+ merge may be missed. (Arun Murthy via ddas)
|
|
|
+
|
|
|
+ HADOOP-3548. Fixes build.xml to copy all *.jar files to the dist.
|
|
|
+ (Owen O'Malley via ddas)
|
|
|
+
|
|
|
+ HADOOP-3363. Fix unformatted storage detection in FSImage. (shv)
|
|
|
+
|
|
|
+ HADOOP-3560. Fixes a problem to do with split creation in archives.
|
|
|
+ (Mahadev Konar via ddas)
|
|
|
+
|
|
|
+ HADOOP-3545. Fixes a overflow problem in archives.
|
|
|
+ (Mahadev Konar via ddas)
|
|
|
+
|
|
|
+ HADOOP-3561. Prevent the trash from deleting its parent directories.
|
|
|
+ (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3575. Fix the clover ant target after package refactoring.
|
|
|
+ (Nigel Daley via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3539. Fix the tool path in the bin/hadoop script under
|
|
|
+ cygwin. (Tsz Wo (Nicholas), Sze via omalley)
|
|
|
+
|
|
|
+ HADOOP-3520. TestDFSUpgradeFromImage triggers a race condition in the
|
|
|
+ Upgrade Manager. Fixed. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-3586. Provide deprecated, backwards compatibile semantics for the
|
|
|
+ combiner to be run once and only once on each record. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3533. Add deprecated methods to provide API compatibility
|
|
|
+ between 0.18 and 0.17. Remove the deprecated methods in trunk. (omalley)
|
|
|
+
|
|
|
+ HADOOP-3580. Fixes a problem to do with specifying a har as an input to
|
|
|
+ a job. (Mahadev Konar via ddas)
|
|
|
+
|
|
|
+ HADOOP-3333. Don't assign a task to a tasktracker that it failed to
|
|
|
+ execute earlier (used to happen in the case of lost tasktrackers where
|
|
|
+ the tasktracker would reinitialize and bind to a different port).
|
|
|
+ (Jothi Padmanabhan and Arun Murthy via ddas)
|
|
|
+
|
|
|
+ HADOOP-3534. Log IOExceptions that happen in closing the name
|
|
|
+ system when the NameNode shuts down. (Tsz Wo (Nicholas) Sze via omalley)
|
|
|
+
|
|
|
+ HADOOP-3546. TaskTracker re-initialization gets stuck in cleaning up.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3576. Fix NullPointerException when renaming a directory
|
|
|
+ to its subdirectory. (Tse Wo (Nicholas), SZE via hairong)
|
|
|
+
|
|
|
+ HADOOP-3320. Fix NullPointerException in NetworkTopology.getDistance().
|
|
|
+ (hairong)
|
|
|
+
|
|
|
+ HADOOP-3569. KFS input stream read() now correctly reads 1 byte
|
|
|
+ instead of 4. (Sriram Rao via omalley)
|
|
|
+
|
|
|
+ HADOOP-3599. Fix JobConf::setCombineOnceOnly to modify the instance rather
|
|
|
+ than a parameter. (Owen O'Malley via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3590. Null pointer exception in JobTracker when the task tracker is
|
|
|
+ not yet resolved. (Amar Ramesh Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-3603. Fix MapOutputCollector to spill when io.sort.spill.percent is
|
|
|
+ 1.0 and to detect spills when emitted records write no data. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3615. Set DatanodeProtocol.versionID to the correct value.
|
|
|
+ (Tsz Wo (Nicholas), SZE via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3559. Fix the libhdfs test script and config to work with the
|
|
|
+ current semantics. (lohit vijayarenu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3480. Need to update Eclipse template to reflect current trunk.
|
|
|
+ (Brice Arnould via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-3588. Fixed usability issues with archives. (mahadev)
|
|
|
+
|
|
|
+ HADOOP-3635. Uncaught exception in DataBlockScanner.
|
|
|
+ (Tsz Wo (Nicholas), SZE via hairong)
|
|
|
+
|
|
|
+ HADOOP-3639. Exception when closing DFSClient while multiple files are
|
|
|
+ open. (Benjamin Gufler via hairong)
|
|
|
+
|
|
|
+ HADOOP-3572. SetQuotas usage interface has some minor bugs. (hairong)
|
|
|
+
|
|
|
+ HADOOP-3649. Fix bug in removing blocks from the corrupted block map.
|
|
|
+ (Lohit Vijayarenu via shv)
|
|
|
+
|
|
|
+ HADOOP-3604. Work around a JVM synchronization problem observed while
|
|
|
+ retrieving the address of direct buffers from compression code by obtaining
|
|
|
+ a lock during this call. (Arun C Murthy via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3683. Fix dfs metrics to count file listings rather than files
|
|
|
+ listed. (lohit vijayarenu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3597. Fix SortValidator to use filesystems other than the default as
|
|
|
+ input. Validation job still runs on default fs.
|
|
|
+ (Jothi Padmanabhan via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3693. Fix archives, distcp and native library documentation to
|
|
|
+ conform to style guidelines. (Amareshwari Sriramadasu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3653. Fix test-patch target to properly account for Eclipse
|
|
|
+ classpath jars. (Brice Arnould via nigel)
|
|
|
+
|
|
|
+ HADOOP-3692. Fix documentation for Cluster setup and Quick start guides.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3691. Fix streaming and tutorial docs. (Jothi Padmanabhan via ddas)
|
|
|
+
|
|
|
+ HADOOP-3630. Fix NullPointerException in CompositeRecordReader from empty
|
|
|
+ sources (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3706. Fix a ClassLoader issue in the mapred.join Parser that
|
|
|
+ prevents it from loading user-specified InputFormats.
|
|
|
+ (Jingkei Ly via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3718. Fix KFSOutputStream::write(int) to output a byte instead of
|
|
|
+ an int, per the OutputStream contract. (Sriram Rao via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3647. Add debug logs to help track down a very occassional,
|
|
|
+ hard-to-reproduce, bug in shuffle/merge on the reducer. (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-3716. Prevent listStatus in KosmosFileSystem from returning
|
|
|
+ null for valid, empty directories. (Sriram Rao via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3752. Fix audit logging to record rename events. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3737. Fix CompressedWritable to call Deflater::end to release
|
|
|
+ compressor memory. (Grant Glouser via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3670. Fixes JobTracker to clear out split bytes when no longer
|
|
|
+ required. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3755. Update gridmix to work with HOD 0.4 (Runping Qi via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3743. Fix -libjars, -files, -archives options to work even if
|
|
|
+ user code does not implement tools. (Amareshwari Sriramadasu via mahadev)
|
|
|
+
|
|
|
+ HADOOP-3774. Fix typos in shell output. (Tsz Wo (Nicholas), SZE via
|
|
|
+ cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3762. Fixed FileSystem cache to work with the default port. (cutting
|
|
|
+ via omalley)
|
|
|
+
|
|
|
+ HADOOP-3798. Fix tests compilation. (Mukund Madhugiri via omalley)
|
|
|
+
|
|
|
+ HADOOP-3794. Return modification time instead of zero for KosmosFileSystem.
|
|
|
+ (Sriram Rao via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3806. Remove debug statement to stdout from QuickSort. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3776. Fix NPE at NameNode when datanode reports a block after it is
|
|
|
+ deleted at NameNode. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-3537. Disallow adding a datanode to a network topology when its
|
|
|
+ network location is not resolved. (hairong)
|
|
|
+
|
|
|
+ HADOOP-3571. Fix bug in block removal used in lease recovery. (shv)
|
|
|
+
|
|
|
+ HADOOP-3645. MetricsTimeVaryingRate returns wrong value for
|
|
|
+ metric_avg_time. (Lohit Vijayarenu via hairong)
|
|
|
+
|
|
|
+ HADOOP-3521. Reverted the missing cast to float for sending Counters' values
|
|
|
+ to Hadoop metrics which was removed by HADOOP-544. (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-3820. Fixes two problems in the gridmix-env - a syntax error, and a
|
|
|
+ wrong definition of USE_REAL_DATASET by default. (Arun Murthy via ddas)
|
|
|
+
|
|
|
+ HADOOP-3724. Fixes two problems related to storing and recovering lease
|
|
|
+ in the fsimage. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-3827. Fixed compression of empty map-outputs. (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-3865. Remove reference to FSNamesystem from metrics preventing
|
|
|
+ garbage collection. (Lohit Vijayarenu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3884. Fix so that Eclipse plugin builds against recent
|
|
|
+ Eclipse releases. (cutting)
|
|
|
+
|
|
|
+ HADOOP-3837. Streaming jobs report progress status. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-3897. Fix a NPE in secondary namenode. (Lohit Vijayarenu via
|
|
|
+ cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3901. Fix bin/hadoop to correctly set classpath under cygwin.
|
|
|
+ (Tsz Wo (Nicholas) Sze via omalley)
|
|
|
+
|
|
|
+ HADOOP-3947. Fix a problem in tasktracker reinitialization.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+Release 0.17.3 - Unreleased
|
|
|
+
|
|
|
+ IMPROVEMENTS
|
|
|
+
|
|
|
+ HADOOP-4164. Chinese translation of the documentation. (Xuebing Yan via
|
|
|
+ omalley)
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-4277. Checksum verification was mistakenly disabled for
|
|
|
+ LocalFileSystem. (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-4271. Checksum input stream can sometimes return invalid
|
|
|
+ data to the user. (Ning Li via rangadi)
|
|
|
+
|
|
|
+ HADOOP-4318. DistCp should use absolute paths for cleanup. (szetszwo)
|
|
|
+
|
|
|
+ HADOOP-4326. ChecksumFileSystem does not override create(...) correctly.
|
|
|
+ (szetszwo)
|
|
|
+
|
|
|
+Release 0.17.2 - 2008-08-11
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-3678. Avoid spurious exceptions logged at DataNode when clients
|
|
|
+ read from DFS. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-3707. NameNode keeps a count of number of blocks scheduled
|
|
|
+ to be written to a datanode and uses it to avoid allocating more
|
|
|
+ blocks than a datanode can hold. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-3760. Fix a bug with HDFS file close() mistakenly introduced
|
|
|
+ by HADOOP-3681. (Lohit Vijayarenu via rangadi)
|
|
|
+
|
|
|
+ HADOOP-3681. DFSClient can get into an infinite loop while closing
|
|
|
+ a file if there are some errors. (Lohit Vijayarenu via rangadi)
|
|
|
+
|
|
|
+ HADOOP-3002. Hold off block removal while in safe mode. (shv)
|
|
|
+
|
|
|
+ HADOOP-3685. Unbalanced replication target. (hairong)
|
|
|
+
|
|
|
+ HADOOP-3758. Shutdown datanode on version mismatch instead of retrying
|
|
|
+ continuously, preventing excessive logging at the namenode.
|
|
|
+ (lohit vijayarenu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3633. Correct exception handling in DataXceiveServer, and throttle
|
|
|
+ the number of xceiver threads in a data-node. (shv)
|
|
|
+
|
|
|
+ HADOOP-3370. Ensure that the TaskTracker.runningJobs data-structure is
|
|
|
+ correctly cleaned-up on task completion. (Zheng Shao via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-3813. Fix task-output clean-up on HDFS to use the recursive
|
|
|
+ FileSystem.delete rather than the FileUtil.fullyDelete. (Amareshwari
|
|
|
+ Sri Ramadasu via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-3859. Allow the maximum number of xceivers in the data node to
|
|
|
+ be configurable. (Johan Oskarsson via omalley)
|
|
|
+
|
|
|
+ HADOOP-3931. Fix corner case in the map-side sort that causes some values
|
|
|
+ to be counted as too large and cause pre-mature spills to disk. Some values
|
|
|
+ will also bypass the combiner incorrectly. (cdouglas via omalley)
|
|
|
+
|
|
|
+Release 0.17.1 - 2008-06-23
|
|
|
+
|
|
|
+ INCOMPATIBLE CHANGES
|
|
|
+
|
|
|
+ HADOOP-3565. Fix the Java serialization, which is not enabled by
|
|
|
+ default, to clear the state of the serializer between objects.
|
|
|
+ (tomwhite via omalley)
|
|
|
+
|
|
|
+ IMPROVEMENTS
|
|
|
+
|
|
|
+ HADOOP-3522. Improve documentation on reduce pointing out that
|
|
|
+ input keys and values will be reused. (omalley)
|
|
|
+
|
|
|
+ HADOOP-3487. Balancer uses thread pools for managing its threads;
|
|
|
+ therefore provides better resource management. (hairong)
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-2159 Namenode stuck in safemode. The counter blockSafe should
|
|
|
+ not be decremented for invalid blocks. (hairong)
|
|
|
+
|
|
|
+ HADOOP-3472 MapFile.Reader getClosest() function returns incorrect results
|
|
|
+ when before is true (Todd Lipcon via Stack)
|
|
|
+
|
|
|
+ HADOOP-3442. Limit recursion depth on the stack for QuickSort to prevent
|
|
|
+ StackOverflowErrors. To avoid O(n*n) cases, when partitioning depth exceeds
|
|
|
+ a multiple of log(n), change to HeapSort. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3477. Fix build to not package contrib/*/bin twice in
|
|
|
+ distributions. (Adam Heath via cutting)
|
|
|
+
|
|
|
+ HADOOP-3475. Fix MapTask to correctly size the accounting allocation of
|
|
|
+ io.sort.mb. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3550. Fix the serialization data structures in MapTask where the
|
|
|
+ value lengths are incorrectly calculated. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3526. Fix contrib/data_join framework by cloning values retained
|
|
|
+ in the reduce. (Spyros Blanas via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-1979. Speed up fsck by adding a buffered stream. (Lohit
|
|
|
+ Vijaya Renu via omalley)
|
|
|
+
|
|
|
+Release 0.17.0 - 2008-05-18
|
|
|
+
|
|
|
+ INCOMPATIBLE CHANGES
|
|
|
+
|
|
|
+ HADOOP-2786. Move hbase out of hadoop core
|
|
|
+
|
|
|
+ HADOOP-2345. New HDFS transactions to support appending
|
|
|
+ to files. Disk layout version changed from -11 to -12. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-2192. Error messages from "dfs mv" command improved.
|
|
|
+ (Mahadev Konar via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1902. "dfs du" command without any arguments operates on the
|
|
|
+ current working directory. (Mahadev Konar via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2873. Fixed bad disk format introduced by HADOOP-2345.
|
|
|
+ Disk layout version changed from -12 to -13. See changelist 630992
|
|
|
+ (dhruba)
|
|
|
+
|
|
|
+ HADOOP-1985. This addresses rack-awareness for Map tasks and for
|
|
|
+ HDFS in a uniform way. (ddas)
|
|
|
+
|
|
|
+ HADOOP-1986. Add support for a general serialization mechanism for
|
|
|
+ Map Reduce. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-771. FileSystem.delete() takes an explicit parameter that
|
|
|
+ specifies whether a recursive delete is intended.
|
|
|
+ (Mahadev Konar via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2470. Remove getContentLength(String), open(String, long, long)
|
|
|
+ and isDir(String) from ClientProtocol. ClientProtocol version changed
|
|
|
+ from 26 to 27. (Tsz Wo (Nicholas), SZE via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2822. Remove deprecated code for classes InputFormatBase and
|
|
|
+ PhasedFileSystem. (Amareshwari Sriramadasu via enis)
|
|
|
+
|
|
|
+ HADOOP-2116. Changes the layout of the task execution directory.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2828. The following deprecated methods in Configuration.java
|
|
|
+ have been removed
|
|
|
+ getObject(String name)
|
|
|
+ setObject(String name, Object value)
|
|
|
+ get(String name, Object defaultValue)
|
|
|
+ set(String name, Object value)
|
|
|
+ Iterator entries()
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2824. Removes one deprecated constructor from MiniMRCluster.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2823. Removes deprecated methods getColumn(), getLine() from
|
|
|
+ org.apache.hadoop.record.compiler.generated.SimpleCharStream.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3060. Removes one unused constructor argument from MiniMRCluster.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2854. Remove deprecated o.a.h.ipc.Server::getUserInfo().
|
|
|
+ (lohit vijayarenu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2563. Remove deprecated FileSystem::listPaths.
|
|
|
+ (lohit vijayarenu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2818. Remove deprecated methods in Counters.
|
|
|
+ (Amareshwari Sriramadasu via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-2831. Remove deprecated o.a.h.dfs.INode::getAbsoluteName()
|
|
|
+ (lohit vijayarenu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2839. Remove deprecated FileSystem::globPaths.
|
|
|
+ (lohit vijayarenu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2634. Deprecate ClientProtocol::exists.
|
|
|
+ (lohit vijayarenu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2410. Make EC2 cluster nodes more independent of each other.
|
|
|
+ Multiple concurrent EC2 clusters are now supported, and nodes may be
|
|
|
+ added to a cluster on the fly with new nodes starting in the same EC2
|
|
|
+ availability zone as the cluster. Ganglia monitoring and large
|
|
|
+ instance sizes have also been added. (Chris K Wensel via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-2826. Deprecated FileSplit.getFile(), LineRecordReader.readLine().
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3239. getFileInfo() returns null for non-existing files instead
|
|
|
+ of throwing FileNotFoundException. (Lohit Vijayarenu via shv)
|
|
|
+
|
|
|
+ HADOOP-3266. Removed HOD changes from CHANGES.txt, as they are now inside
|
|
|
+ src/contrib/hod (Hemanth Yamijala via ddas)
|
|
|
+
|
|
|
+ HADOOP-3280. Separate the configuration of the virtual memory size
|
|
|
+ (mapred.child.ulimit) from the jvm heap size, so that 64 bit
|
|
|
+ streaming applications are supported even when running with 32 bit
|
|
|
+ jvms. (acmurthy via omalley)
|
|
|
+
|
|
|
+ NEW FEATURES
|
|
|
+
|
|
|
+ HADOOP-1398. Add HBase in-memory block cache. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-2178. Job History on DFS. (Amareshwari Sri Ramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2063. A new parameter to dfs -get command to fetch a file
|
|
|
+ even if it is corrupted. (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2219. A new command "df -count" that counts the number of
|
|
|
+ files and directories. (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2906. Add an OutputFormat capable of using keys, values, and
|
|
|
+ config params to map records to different output files.
|
|
|
+ (Runping Qi via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2346. Utilities to support timeout while writing to sockets.
|
|
|
+ DFSClient and DataNode sockets have 10min write timeout. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-2951. Add a contrib module that provides a utility to
|
|
|
+ build or update Lucene indexes using Map/Reduce. (Ning Li via cutting)
|
|
|
+
|
|
|
+ HADOOP-1622. Allow multiple jar files for map reduce.
|
|
|
+ (Mahadev Konar via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2055. Allows users to set PathFilter on the FileInputFormat.
|
|
|
+ (Alejandro Abdelnur via ddas)
|
|
|
+
|
|
|
+ HADOOP-2551. More environment variables like HADOOP_NAMENODE_OPTS
|
|
|
+ for better control of HADOOP_OPTS for each component. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-3001. Add job counters that measure the number of bytes
|
|
|
+ read and written to HDFS, S3, KFS, and local file systems. (omalley)
|
|
|
+
|
|
|
+ HADOOP-3048. A new Interface and a default implementation to convert
|
|
|
+ and restore serializations of objects to/from strings. (enis)
|
|
|
+
|
|
|
+ IMPROVEMENTS
|
|
|
+
|
|
|
+ HADOOP-2655. Copy on write for data and metadata files in the
|
|
|
+ presence of snapshots. Needed for supporting appends to HDFS
|
|
|
+ files. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-1967. When a Path specifies the same scheme as the default
|
|
|
+ FileSystem but no authority, the default FileSystem's authority is
|
|
|
+ used. Also add warnings for old-format FileSystem names, accessor
|
|
|
+ methods for fs.default.name, and check for null authority in HDFS.
|
|
|
+ (cutting)
|
|
|
+
|
|
|
+ HADOOP-2895. Let the profiling string be configurable.
|
|
|
+ (Martin Traverso via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-910. Enables Reduces to do merges for the on-disk map output files
|
|
|
+ in parallel with their copying. (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-730. Use rename rather than copy for local renames. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2810. Updated the Hadoop Core logo. (nigel)
|
|
|
+
|
|
|
+ HADOOP-2057. Streaming should optionally treat a non-zero exit status
|
|
|
+ of a child process as a failed task. (Rick Cox via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-2765. Enables specifying ulimits for streaming/pipes tasks (ddas)
|
|
|
+
|
|
|
+ HADOOP-2888. Make gridmix scripts more readily configurable and amenable
|
|
|
+ to automated execution. (Mukund Madhugiri via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2908. A document that describes the DFS Shell command.
|
|
|
+ (Mahadev Konar via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2981. Update README.txt to reflect the upcoming use of
|
|
|
+ cryptography. (omalley)
|
|
|
+
|
|
|
+ HADOOP-2804. Add support to publish CHANGES.txt as HTML when running
|
|
|
+ the Ant 'docs' target. (nigel)
|
|
|
+
|
|
|
+ HADOOP-2559. Change DFS block placement to allocate the first replica
|
|
|
+ locally, the second off-rack, and the third intra-rack from the
|
|
|
+ second. (lohit vijayarenu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2939. Make the automated patch testing process an executable
|
|
|
+ Ant target, test-patch. (nigel)
|
|
|
+
|
|
|
+ HADOOP-2239. Add HsftpFileSystem to permit transferring files over ssl.
|
|
|
+ (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2886. Track individual RPC metrics.
|
|
|
+ (girish vaitheeswaran via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2373. Improvement in safe-mode reporting. (shv)
|
|
|
+
|
|
|
+ HADOOP-3091. Modify FsShell command -put to accept multiple sources.
|
|
|
+ (Lohit Vijaya Renu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3092. Show counter values from job -status command.
|
|
|
+ (Tom White via ddas)
|
|
|
+
|
|
|
+ HADOOP-1228. Ant task to generate Eclipse project files. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-3093. Adds Configuration.getStrings(name, default-value) and
|
|
|
+ the corresponding setStrings. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3106. Adds documentation in forrest for debugging.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3099. Add an option to distcp to preserve user, group, and
|
|
|
+ permission information. (Tsz Wo (Nicholas), SZE via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2841. Unwrap AccessControlException and FileNotFoundException
|
|
|
+ from RemoteException for DFSClient. (shv)
|
|
|
+
|
|
|
+ HADOOP-3152. Make index interval configuable when using
|
|
|
+ MapFileOutputFormat for map-reduce job. (Rong-En Fan via cutting)
|
|
|
+
|
|
|
+ HADOOP-3143. Decrease number of slaves from 4 to 3 in TestMiniMRDFSSort,
|
|
|
+ as Hudson generates false negatives under the current load.
|
|
|
+ (Nigel Daley via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3174. Illustrative example for MultipleFileInputFormat. (Enis
|
|
|
+ Soztutar via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2993. Clarify the usage of JAVA_HOME in the Quick Start guide.
|
|
|
+ (acmurthy via nigel)
|
|
|
+
|
|
|
+ HADOOP-3124. Make DataNode socket write timeout configurable. (rangadi)
|
|
|
+
|
|
|
+ OPTIMIZATIONS
|
|
|
+
|
|
|
+ HADOOP-2790. Fixed inefficient method hasSpeculativeTask by removing
|
|
|
+ repetitive calls to get the current time and late checking to see if
|
|
|
+ we want speculation on at all. (omalley)
|
|
|
+
|
|
|
+ HADOOP-2758. Reduce buffer copies in DataNode when data is read from
|
|
|
+ HDFS, without negatively affecting read throughput. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-2399. Input key and value to combiner and reducer is reused.
|
|
|
+ (Owen O'Malley via ddas).
|
|
|
+
|
|
|
+ HADOOP-2423. Code optimization in FSNamesystem.mkdirs.
|
|
|
+ (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2606. ReplicationMonitor selects data-nodes to replicate directly
|
|
|
+ from needed replication blocks instead of looking up for the blocks for
|
|
|
+ each live data-node. (shv)
|
|
|
+
|
|
|
+ HADOOP-2148. Eliminate redundant data-node blockMap lookups. (shv)
|
|
|
+
|
|
|
+ HADOOP-2027. Return the number of bytes in each block in a file
|
|
|
+ via a single rpc to the namenode to speed up job planning.
|
|
|
+ (Lohit Vijaya Renu via omalley)
|
|
|
+
|
|
|
+ HADOOP-2902. Replace uses of "fs.default.name" with calls to the
|
|
|
+ accessor methods added in HADOOP-1967. (cutting)
|
|
|
+
|
|
|
+ HADOOP-2119. Optimize scheduling of jobs with large numbers of
|
|
|
+ tasks by replacing static arrays with lists of runnable tasks.
|
|
|
+ (Amar Kamat via omalley)
|
|
|
+
|
|
|
+ HADOOP-2919. Reduce the number of memory copies done during the
|
|
|
+ map output sorting. Also adds two config variables:
|
|
|
+ io.sort.spill.percent - the percentages of io.sort.mb that should
|
|
|
+ cause a spill (default 80%)
|
|
|
+ io.sort.record.percent - the percent of io.sort.mb that should
|
|
|
+ hold key/value indexes (default 5%)
|
|
|
+ (cdouglas via omalley)
|
|
|
+
|
|
|
+ HADOOP-3140. Doesn't add a task in the commit queue if the task hadn't
|
|
|
+ generated any output. (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-3168. Reduce the amount of logging in streaming to an
|
|
|
+ exponentially increasing number of records (up to 10,000
|
|
|
+ records/log). (Zheng Shao via omalley)
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-2195. '-mkdir' behaviour is now closer to Linux shell in case of
|
|
|
+ errors. (Mahadev Konar via rangadi)
|
|
|
+
|
|
|
+ HADOOP-2190. bring behaviour '-ls' and '-du' closer to Linux shell
|
|
|
+ commands in case of errors. (Mahadev Konar via rangadi)
|
|
|
+
|
|
|
+ HADOOP-2193. 'fs -rm' and 'fs -rmr' show error message when the target
|
|
|
+ file does not exist. (Mahadev Konar via rangadi)
|
|
|
+
|
|
|
+ HADOOP-2738 Text is not subclassable because set(Text) and compareTo(Object)
|
|
|
+ access the other instance's private members directly. (jimk)
|
|
|
+
|
|
|
+ HADOOP-2779. Remove the references to HBase in the build.xml. (omalley)
|
|
|
+
|
|
|
+ HADOOP-2194. dfs cat on a non-existent file throws FileNotFoundException.
|
|
|
+ (Mahadev Konar via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2767. Fix for NetworkTopology erroneously skipping the last leaf
|
|
|
+ node on a rack. (Hairong Kuang and Mark Butler via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1593. FsShell works with paths in non-default FileSystem.
|
|
|
+ (Mahadev Konar via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2191. du and dus command on non-existent directory gives
|
|
|
+ appropriate error message. (Mahadev Konar via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2832. Remove tabs from code of DFSClient for better
|
|
|
+ indentation. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-2844. distcp closes file handles for sequence files.
|
|
|
+ (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2727. Fix links in Web UI of the hadoop daemons and some docs
|
|
|
+ (Amareshwari Sri Ramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2871. Fixes a problem to do with file: URI in the JobHistory init.
|
|
|
+ (Amareshwari Sri Ramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2800. Deprecate SetFile.Writer constructor not the whole class.
|
|
|
+ (Johan Oskarsson via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-2891. DFSClient.close() closes all open files. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-2845. Fix dfsadmin disk utilization report on Solaris.
|
|
|
+ (Martin Traverso via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-2912. MiniDFSCluster restart should wait for namenode to exit
|
|
|
+ safemode. This was causing TestFsck to fail. (Mahadev Konar via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2820. The following classes in streaming are removed :
|
|
|
+ StreamLineRecordReader StreamOutputFormat StreamSequenceRecordReader.
|
|
|
+ (Amareshwari Sri Ramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2819. The following methods in JobConf are removed:
|
|
|
+ getInputKeyClass() setInputKeyClass getInputValueClass()
|
|
|
+ setInputValueClass(Class theClass) setSpeculativeExecution
|
|
|
+ getSpeculativeExecution() (Amareshwari Sri Ramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2817. Removes deprecated mapred.tasktracker.tasks.maximum and
|
|
|
+ ClusterStatus.getMaxTasks(). (Amareshwari Sri Ramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2821. Removes deprecated ShellUtil and ToolBase classes from
|
|
|
+ the util package. (Amareshwari Sri Ramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2934. The namenode was encountreing a NPE while loading
|
|
|
+ leases from the fsimage. Fixed. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-2938. Some fs commands did not glob paths.
|
|
|
+ (Tsz Wo (Nicholas), SZE via rangadi)
|
|
|
+
|
|
|
+ HADOOP-2943. Compression of intermediate map output causes failures
|
|
|
+ in the merge. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2870. DataNode and NameNode closes all connections while
|
|
|
+ shutting down. (Hairong Kuang via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2973. Fix TestLocalDFS for Windows platform.
|
|
|
+ (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2971. select multiple times if it returns early in
|
|
|
+ SocketIOWithTimeout. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-2955. Fix TestCrcCorruption test failures caused by HADOOP-2758
|
|
|
+ (rangadi)
|
|
|
+
|
|
|
+ HADOOP-2657. A flush call on the DFSOutputStream flushes the last
|
|
|
+ partial CRC chunk too. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-2974. IPC unit tests used "0.0.0.0" to connect to server, which
|
|
|
+ is not always supported. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-2996. Fixes uses of StringBuffer in StreamUtils class.
|
|
|
+ (Dave Brosius via ddas)
|
|
|
+
|
|
|
+ HADOOP-2995. Fixes StreamBaseRecordReader's getProgress to return a
|
|
|
+ floating point number. (Dave Brosius via ddas)
|
|
|
+
|
|
|
+ HADOOP-2972. Fix for a NPE in FSDataset.invalidate.
|
|
|
+ (Mahadev Konar via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2994. Code cleanup for DFSClient: remove redundant
|
|
|
+ conversions from string to string. (Dave Brosius via dhruba)
|
|
|
+
|
|
|
+ HADOOP-3009. TestFileCreation sometimes fails because restarting
|
|
|
+ minidfscluster sometimes creates datanodes with ports that are
|
|
|
+ different from their original instance. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-2992. Distributed Upgrade framework works correctly with
|
|
|
+ more than one upgrade object. (Konstantin Shvachko via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2679. Fix a typo in libhdfs. (Jason via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2976. When a lease expires, the Namenode ensures that
|
|
|
+ blocks of the file are adequately replicated. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-2901. Fixes the creation of info servers in the JobClient
|
|
|
+ and JobTracker. Removes the creation from JobClient and removes
|
|
|
+ additional info server from the JobTracker. Also adds the command
|
|
|
+ line utility to view the history files (HADOOP-2896), and fixes
|
|
|
+ bugs in JSPs to do with analysis - HADOOP-2742, HADOOP-2792.
|
|
|
+ (Amareshwari Sri Ramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2890. If different datanodes report the same block but
|
|
|
+ with different sizes to the namenode, the namenode picks the
|
|
|
+ replica(s) with the largest size as the only valid replica(s). (dhruba)
|
|
|
+
|
|
|
+ HADOOP-2825. Deprecated MapOutputLocation.getFile() is removed.
|
|
|
+ (Amareshwari Sri Ramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2806. Fixes a streaming document.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3008. SocketIOWithTimeout throws InterruptedIOException if the
|
|
|
+ thread is interrupted while it is waiting. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-3006. Fix wrong packet size reported by DataNode when a block
|
|
|
+ is being replicated. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-3029. Datanode prints log message "firstbadlink" only if
|
|
|
+ it detects a bad connection to another datanode in the pipeline. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-3030. Release reserved space for file in InMemoryFileSystem if
|
|
|
+ checksum reservation fails. (Devaraj Das via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3036. Fix findbugs warnings in UpgradeUtilities. (Konstantin
|
|
|
+ Shvachko via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3025. ChecksumFileSystem supports the delete method with
|
|
|
+ the recursive flag. (Mahadev Konar via dhruba)
|
|
|
+
|
|
|
+ HADOOP-3012. dfs -mv file to user home directory throws exception if
|
|
|
+ the user home directory does not exist. (Mahadev Konar via dhruba)
|
|
|
+
|
|
|
+ HADOOP-3066. Should not require superuser privilege to query if hdfs is in
|
|
|
+ safe mode (jimk)
|
|
|
+
|
|
|
+ HADOOP-3040. If the input line starts with the separator char, the key
|
|
|
+ is set as empty. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3080. Removes flush calls from JobHistory.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3086. Adds the testcase missed during commit of hadoop-3040.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3046. Fix the raw comparators for Text and BytesWritables
|
|
|
+ to use the provided length rather than recompute it. (omalley)
|
|
|
+
|
|
|
+ HADOOP-3094. Fix BytesWritable.toString to avoid extending the sign bit
|
|
|
+ (Owen O'Malley via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3067. DFSInputStream's position read does not close the sockets.
|
|
|
+ (rangadi)
|
|
|
+
|
|
|
+ HADOOP-3073. close() on SocketInputStream or SocketOutputStream should
|
|
|
+ close the underlying channel. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-3087. Fixes a problem to do with refreshing of loadHistory.jsp.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3065. Better logging message if the rack location of a datanode
|
|
|
+ cannot be determined. (Devaraj Das via dhruba)
|
|
|
+
|
|
|
+ HADOOP-3064. Commas in a file path should not be treated as delimiters.
|
|
|
+ (Hairong Kuang via shv)
|
|
|
+
|
|
|
+ HADOOP-2997. Adds test for non-writable serialier. Also fixes a problem
|
|
|
+ introduced by HADOOP-2399. (Tom White via ddas)
|
|
|
+
|
|
|
+ HADOOP-3114. Fix TestDFSShell on Windows. (Lohit Vijaya Renu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3118. Fix Namenode NPE while loading fsimage after a cluster
|
|
|
+ upgrade from older disk format. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-3161. Fix FIleUtil.HardLink.getLinkCount on Mac OS. (nigel
|
|
|
+ via omalley)
|
|
|
+
|
|
|
+ HADOOP-2927. Fix TestDU to acurately calculate the expected file size.
|
|
|
+ (shv via nigel)
|
|
|
+
|
|
|
+ HADOOP-3123. Fix the native library build scripts to work on Solaris.
|
|
|
+ (tomwhite via omalley)
|
|
|
+
|
|
|
+ HADOOP-3089. Streaming should accept stderr from task before
|
|
|
+ first key arrives. (Rick Cox via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-3146. A DFSOutputStream.flush method is renamed as
|
|
|
+ DFSOutputStream.fsync. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-3165. -put/-copyFromLocal did not treat input file "-" as stdin.
|
|
|
+ (Lohit Vijayarenu via rangadi)
|
|
|
+
|
|
|
+ HADOOP-3041. Deprecate JobConf.setOutputPath and JobConf.getOutputPath.
|
|
|
+ Deprecate OutputFormatBase. Add FileOutputFormat. Existing output formats
|
|
|
+ extending OutputFormatBase, now extend FileOutputFormat. Add the following
|
|
|
+ APIs in FileOutputFormat: setOutputPath, getOutputPath, getWorkOutputPath.
|
|
|
+ (Amareshwari Sriramadasu via nigel)
|
|
|
+
|
|
|
+ HADOOP-3083. The fsimage does not store leases. This would have to be
|
|
|
+ reworked in the next release to support appends. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-3166. Fix an ArrayIndexOutOfBoundsException in the spill thread
|
|
|
+ and make exception handling more promiscuous to catch this condition.
|
|
|
+ (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3050. DataNode sends one and only one block report after
|
|
|
+ it registers with the namenode. (Hairong Kuang)
|
|
|
+
|
|
|
+ HADOOP-3044. NNBench sets the right configuration for the mapper.
|
|
|
+ (Hairong Kuang)
|
|
|
+
|
|
|
+ HADOOP-3178. Fix GridMix scripts for small and medium jobs
|
|
|
+ to handle input paths differently. (Mukund Madhugiri via nigel)
|
|
|
+
|
|
|
+ HADOOP-1911. Fix an infinite loop in DFSClient when all replicas of a
|
|
|
+ block are bad (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3157. Fix path handling in DistributedCache and TestMiniMRLocalFS.
|
|
|
+ (Doug Cutting via rangadi)
|
|
|
+
|
|
|
+ HADOOP-3018. Fix the eclipse plug-in contrib wrt removed deprecated
|
|
|
+ methods (taton)
|
|
|
+
|
|
|
+ HADOOP-3183. Fix TestJobShell to use 'ls' instead of java.io.File::exists
|
|
|
+ since cygwin symlinks are unsupported.
|
|
|
+ (Mahadev konar via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3175. Fix FsShell.CommandFormat to handle "-" in arguments.
|
|
|
+ (Edward J. Yoon via rangadi)
|
|
|
+
|
|
|
+ HADOOP-3220. Safemode message corrected. (shv)
|
|
|
+
|
|
|
+ HADOOP-3208. Fix WritableDeserializer to set the Configuration on
|
|
|
+ deserialized Writables. (Enis Soztutar via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3224. 'dfs -du /dir' does not return correct size.
|
|
|
+ (Lohit Vjayarenu via rangadi)
|
|
|
+
|
|
|
+ HADOOP-3223. Fix typo in help message for -chmod. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-1373. checkPath() should ignore case when it compares authoriy.
|
|
|
+ (Edward J. Yoon via rangadi)
|
|
|
+
|
|
|
+ HADOOP-3204. Fixes a problem to do with ReduceTask's LocalFSMerger not
|
|
|
+ catching Throwable. (Amar Ramesh Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-3229. Report progress when collecting records from the mapper and
|
|
|
+ the combiner. (Doug Cutting via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3225. Unwrapping methods of RemoteException should initialize
|
|
|
+ detailedMassage field. (Mahadev Konar, shv, cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3247. Fix gridmix scripts to use the correct globbing syntax and
|
|
|
+ change maxentToSameCluster to run the correct number of jobs.
|
|
|
+ (Runping Qi via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3242. Fix the RecordReader of SequenceFileAsBinaryInputFormat to
|
|
|
+ correctly read from the start of the split and not the beginning of the
|
|
|
+ file. (cdouglas via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-3256. Encodes the job name used in the filename for history files.
|
|
|
+ (Arun Murthy via ddas)
|
|
|
+
|
|
|
+ HADOOP-3162. Ensure that comma-separated input paths are treated correctly
|
|
|
+ as multiple input paths. (Amareshwari Sri Ramadasu via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-3263. Ensure that the job-history log file always follows the
|
|
|
+ pattern of hostname_timestamp_jobid_username_jobname even if username
|
|
|
+ and/or jobname are not specfied. This helps to avoid wrong assumptions
|
|
|
+ made about the job-history log filename in jobhistory.jsp. (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-3251. Fixes getFilesystemName in JobTracker and LocalJobRunner to
|
|
|
+ use FileSystem.getUri instead of FileSystem.getName. (Arun Murthy via ddas)
|
|
|
+
|
|
|
+ HADOOP-3237. Fixes TestDFSShell.testErrOutPut on Windows platform.
|
|
|
+ (Mahadev Konar via ddas)
|
|
|
+
|
|
|
+ HADOOP-3279. TaskTracker checks for SUCCEEDED task status in addition to
|
|
|
+ COMMIT_PENDING status when it fails maps due to lost map.
|
|
|
+ (Devaraj Das)
|
|
|
+
|
|
|
+ HADOOP-3286. Prevent collisions in gridmix output dirs by increasing the
|
|
|
+ granularity of the timestamp. (Runping Qi via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3285. Fix input split locality when the splits align to
|
|
|
+ fs blocks. (omalley)
|
|
|
+
|
|
|
+ HADOOP-3372. Fix heap management in streaming tests. (Arun Murthy via
|
|
|
+ cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3031. Fix javac warnings in test classes. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3382. Fix memory leak when files are not cleanly closed (rangadi)
|
|
|
+
|
|
|
+ HADOOP-3322. Fix to push MetricsRecord for rpc metrics. (Eric Yang via
|
|
|
+ mukund)
|
|
|
+
|
|
|
+Release 0.16.4 - 2008-05-05
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-3138. DFS mkdirs() should not throw an exception if the directory
|
|
|
+ already exists. (rangadi via mukund)
|
|
|
+
|
|
|
+ HADOOP-3294. Fix distcp to check the destination length and retry the copy
|
|
|
+ if it doesn't match the src length. (Tsz Wo (Nicholas), SZE via mukund)
|
|
|
+
|
|
|
+ HADOOP-3186. Fix incorrect permission checkding for mv and renameTo
|
|
|
+ in HDFS. (Tsz Wo (Nicholas), SZE via mukund)
|
|
|
+
|
|
|
+Release 0.16.3 - 2008-04-16
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-3010. Fix ConcurrentModificationException in ipc.Server.Responder.
|
|
|
+ (rangadi)
|
|
|
+
|
|
|
+ HADOOP-3154. Catch all Throwables from the SpillThread in MapTask, rather
|
|
|
+ than IOExceptions only. (ddas via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3159. Avoid file system cache being overwritten whenever
|
|
|
+ configuration is modified. (Tsz Wo (Nicholas), SZE via hairong)
|
|
|
+
|
|
|
+ HADOOP-3139. Remove the consistency check for the FileSystem cache in
|
|
|
+ closeAll() that causes spurious warnings and a deadlock.
|
|
|
+ (Tsz Wo (Nicholas), SZE via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3195. Fix TestFileSystem to be deterministic.
|
|
|
+ (Tsz Wo (Nicholas), SZE via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3069. Primary name-node should not truncate image when transferring
|
|
|
+ it from the secondary. (shv)
|
|
|
+
|
|
|
+ HADOOP-3182. Change permissions of the job-submission directory to 777
|
|
|
+ from 733 to ensure sharing of HOD clusters works correctly. (Tsz Wo
|
|
|
+ (Nicholas), Sze and Amareshwari Sri Ramadasu via acmurthy)
|
|
|
+
|
|
|
+Release 0.16.2 - 2008-04-02
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-3011. Prohibit distcp from overwriting directories on the
|
|
|
+ destination filesystem with files. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3033. The BlockReceiver thread in the datanode writes data to
|
|
|
+ the block file, changes file position (if needed) and flushes all by
|
|
|
+ itself. The PacketResponder thread does not flush block file. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-2978. Fixes the JobHistory log format for counters.
|
|
|
+ (Runping Qi via ddas)
|
|
|
+
|
|
|
+ HADOOP-2985. Fixes LocalJobRunner to tolerate null job output path.
|
|
|
+ Also makes the _temporary a constant in MRConstants.java.
|
|
|
+ (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3003. FileSystem cache key is updated after a
|
|
|
+ FileSystem object is created. (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-3042. Updates the Javadoc in JobConf.getOutputPath to reflect
|
|
|
+ the actual temporary path. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3007. Tolerate mirror failures while DataNode is replicating
|
|
|
+ blocks as it used to before. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-2944. Fixes a "Run on Hadoop" wizard NPE when creating a
|
|
|
+ Location from the wizard. (taton)
|
|
|
+
|
|
|
+ HADOOP-3049. Fixes a problem in MultiThreadedMapRunner to do with
|
|
|
+ catching RuntimeExceptions. (Alejandro Abdelnur via ddas)
|
|
|
+
|
|
|
+ HADOOP-3039. Fixes a problem to do with exceptions in tasks not
|
|
|
+ killing jobs. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3027. Fixes a problem to do with adding a shutdown hook in
|
|
|
+ FileSystem. (Amareshwari Sriramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-3056. Fix distcp when the target is an empty directory by
|
|
|
+ making sure the directory is created first. (cdouglas and acmurthy
|
|
|
+ via omalley)
|
|
|
+
|
|
|
+ HADOOP-3070. Protect the trash emptier thread from null pointer
|
|
|
+ exceptions. (Koji Noguchi via omalley)
|
|
|
+
|
|
|
+ HADOOP-3084. Fix HftpFileSystem to work for zero-lenghth files.
|
|
|
+ (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-3107. Fix NPE when fsck invokes getListings. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-3104. Limit MultithreadedMapRunner to have a fixed length queue
|
|
|
+ between the RecordReader and the map threads. (Alejandro Abdelnur via
|
|
|
+ omalley)
|
|
|
+
|
|
|
+ HADOOP-2833. Do not use "Dr. Who" as the default user in JobClient.
|
|
|
+ A valid user name is required. (Tsz Wo (Nicholas), SZE via rangadi)
|
|
|
+
|
|
|
+ HADOOP-3128. Throw RemoteException in setPermissions and setOwner of
|
|
|
+ DistributedFileSystem. (shv via nigel)
|
|
|
+
|
|
|
+Release 0.16.1 - 2008-03-13
|
|
|
+
|
|
|
+ INCOMPATIBLE CHANGES
|
|
|
+
|
|
|
+ HADOOP-2869. Deprecate SequenceFile.setCompressionType in favor of
|
|
|
+ SequenceFile.createWriter, SequenceFileOutputFormat.setCompressionType,
|
|
|
+ and JobConf.setMapOutputCompressionType. (Arun C Murthy via cdouglas)
|
|
|
+ Configuration changes to hadoop-default.xml:
|
|
|
+ deprecated io.seqfile.compression.type
|
|
|
+
|
|
|
+ IMPROVEMENTS
|
|
|
+
|
|
|
+ HADOOP-2371. User guide for file permissions in HDFS.
|
|
|
+ (Robert Chansler via rangadi)
|
|
|
+
|
|
|
+ HADOOP-3098. Allow more characters in user and group names while
|
|
|
+ using -chown and -chgrp commands. (rangadi)
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-2789. Race condition in IPC Server Responder that could close
|
|
|
+ connections early. (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-2785. minor. Fix a typo in Datanode block verification
|
|
|
+ (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-2788. minor. Fix help message for chgrp shell command (Raghu Angadi).
|
|
|
+
|
|
|
+ HADOOP-1188. fstime file is updated when a storage directory containing
|
|
|
+ namespace image becomes inaccessible. (shv)
|
|
|
+
|
|
|
+ HADOOP-2787. An application can set a configuration variable named
|
|
|
+ dfs.umask to set the umask that is used by DFS.
|
|
|
+ (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2780. The default socket buffer size for DataNodes is 128K.
|
|
|
+ (dhruba)
|
|
|
+
|
|
|
+ HADOOP-2716. Superuser privileges for the Balancer.
|
|
|
+ (Tsz Wo (Nicholas), SZE via shv)
|
|
|
+
|
|
|
+ HADOOP-2754. Filter out .crc files from local file system listing.
|
|
|
+ (Hairong Kuang via shv)
|
|
|
+
|
|
|
+ HADOOP-2733. Fix compiler warnings in test code.
|
|
|
+ (Tsz Wo (Nicholas), SZE via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2725. Modify distcp to avoid leaving partially copied files at
|
|
|
+ the destination after encountering an error. (Tsz Wo (Nicholas), SZE
|
|
|
+ via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2391. Cleanup job output directory before declaring a job as
|
|
|
+ SUCCESSFUL. (Amareshwari Sri Ramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2808. Minor fix to FileUtil::copy to mind the overwrite
|
|
|
+ formal. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2683. Moving UGI out of the RPC Server.
|
|
|
+ (Tsz Wo (Nicholas), SZE via shv)
|
|
|
+
|
|
|
+ HADOOP-2814. Fix for NPE in datanode in unit test TestDataTransferProtocol.
|
|
|
+ (Raghu Angadi via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2811. Dump of counters in job history does not add comma between
|
|
|
+ groups. (runping via omalley)
|
|
|
+
|
|
|
+ HADOOP-2735. Enables setting TMPDIR for tasks.
|
|
|
+ (Amareshwari Sri Ramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2843. Fix protections on map-side join classes to enable derivation.
|
|
|
+ (cdouglas via omalley)
|
|
|
+
|
|
|
+ HADOOP-2840. Fix gridmix scripts to correctly invoke the java sort through
|
|
|
+ the proper jar. (Mukund Madhugiri via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2769. TestNNThroughputBnechmark should not use a fixed port for
|
|
|
+ the namenode http port. (omalley)
|
|
|
+
|
|
|
+ HADOOP-2852. Update gridmix benchmark to avoid an artifically long tail.
|
|
|
+ (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2894. Fix a problem to do with tasktrackers failing to connect to
|
|
|
+ JobTracker upon reinitialization. (Owen O'Malley via ddas).
|
|
|
+
|
|
|
+ HADOOP-2903. Fix exception generated by Metrics while using pushMetric().
|
|
|
+ (girish vaitheeswaran via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2904. Fix to RPC metrics to log the correct host name.
|
|
|
+ (girish vaitheeswaran via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2918. Improve error logging so that dfs writes failure with
|
|
|
+ "No lease on file" can be diagnosed. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-2923. Add SequenceFileAsBinaryInputFormat, which was
|
|
|
+ missed in the commit for HADOOP-2603. (cdouglas via omalley)
|
|
|
+
|
|
|
+ HADOOP-2931. IOException thrown by DFSOutputStream had wrong stack
|
|
|
+ trace in some cases. (Michael Bieniosek via rangadi)
|
|
|
+
|
|
|
+ HADOOP-2883. Write failures and data corruptions on HDFS files.
|
|
|
+ The write timeout is back to what it was on 0.15 release. Also, the
|
|
|
+ datnodes flushes the block file buffered output stream before
|
|
|
+ sending a positive ack for the packet back to the client. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-2756. NPE in DFSClient while closing DFSOutputStreams
|
|
|
+ under load. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-2958. Fixed FileBench which broke due to HADOOP-2391 which performs
|
|
|
+ a check for existence of the output directory and a trivial bug in
|
|
|
+ GenericMRLoadGenerator where min/max word lenghts were identical since
|
|
|
+ they were looking at the same config variables (Chris Douglas via
|
|
|
+ acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2915. Fixed FileSystem.CACHE so that a username is included
|
|
|
+ in the cache key. (Tsz Wo (Nicholas), SZE via nigel)
|
|
|
+
|
|
|
+ HADOOP-2813. TestDU unit test uses its own directory to run its
|
|
|
+ sequence of tests. (Mahadev Konar via dhruba)
|
|
|
+
|
|
|
+Release 0.16.0 - 2008-02-07
|
|
|
+
|
|
|
+ INCOMPATIBLE CHANGES
|
|
|
+
|
|
|
+ HADOOP-1245. Use the mapred.tasktracker.tasks.maximum value
|
|
|
+ configured on each tasktracker when allocating tasks, instead of
|
|
|
+ the value configured on the jobtracker. InterTrackerProtocol
|
|
|
+ version changed from 5 to 6. (Michael Bieniosek via omalley)
|
|
|
+
|
|
|
+ HADOOP-1843. Removed code from Configuration and JobConf deprecated by
|
|
|
+ HADOOP-785 and a minor fix to Configuration.toString. Specifically the
|
|
|
+ important change is that mapred-default.xml is no longer supported and
|
|
|
+ Configuration no longer supports the notion of default/final resources.
|
|
|
+ (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-1302. Remove deprecated abacus code from the contrib directory.
|
|
|
+ This also fixes a configuration bug in AggregateWordCount, so that the
|
|
|
+ job now works. (enis)
|
|
|
+
|
|
|
+ HADOOP-2288. Enhance FileSystem API to support access control.
|
|
|
+ (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2184. RPC Support for user permissions and authentication.
|
|
|
+ (Raghu Angadi via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2185. RPC Server uses any available port if the specified
|
|
|
+ port is zero. Otherwise it uses the specified port. Also combines
|
|
|
+ the configuration attributes for the servers' bind address and
|
|
|
+ port from "x.x.x.x" and "y" to "x.x.x.x:y".
|
|
|
+ Deprecated configuration variables:
|
|
|
+ dfs.info.bindAddress
|
|
|
+ dfs.info.port
|
|
|
+ dfs.datanode.bindAddress
|
|
|
+ dfs.datanode.port
|
|
|
+ dfs.datanode.info.bindAdress
|
|
|
+ dfs.datanode.info.port
|
|
|
+ dfs.secondary.info.bindAddress
|
|
|
+ dfs.secondary.info.port
|
|
|
+ mapred.job.tracker.info.bindAddress
|
|
|
+ mapred.job.tracker.info.port
|
|
|
+ mapred.task.tracker.report.bindAddress
|
|
|
+ tasktracker.http.bindAddress
|
|
|
+ tasktracker.http.port
|
|
|
+ New configuration variables (post HADOOP-2404):
|
|
|
+ dfs.secondary.http.address
|
|
|
+ dfs.datanode.address
|
|
|
+ dfs.datanode.http.address
|
|
|
+ dfs.http.address
|
|
|
+ mapred.job.tracker.http.address
|
|
|
+ mapred.task.tracker.report.address
|
|
|
+ mapred.task.tracker.http.address
|
|
|
+ (Konstantin Shvachko via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2401. Only the current leaseholder can abandon a block for
|
|
|
+ a HDFS file. ClientProtocol version changed from 20 to 21.
|
|
|
+ (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2381. Support permission information in FileStatus. Client
|
|
|
+ Protocol version changed from 21 to 22. (Raghu Angadi via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2110. Block report processing creates fewer transient objects.
|
|
|
+ Datanode Protocol version changed from 10 to 11.
|
|
|
+ (Sanjay Radia via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2567. Add FileSystem#getHomeDirectory(), which returns the
|
|
|
+ user's home directory in a FileSystem as a fully-qualified path.
|
|
|
+ FileSystem#getWorkingDirectory() is also changed to return a
|
|
|
+ fully-qualified path, which can break applications that attempt
|
|
|
+ to, e.g., pass LocalFileSystem#getWorkingDir().toString() directly
|
|
|
+ to java.io methods that accept file names. (cutting)
|
|
|
+
|
|
|
+ HADOOP-2514. Change trash feature to maintain a per-user trash
|
|
|
+ directory, named ".Trash" in the user's home directory. The
|
|
|
+ "fs.trash.root" parameter is no longer used. Full source paths
|
|
|
+ are also no longer reproduced within the trash.
|
|
|
+
|
|
|
+ HADOOP-2012. Periodic data verification on Datanodes.
|
|
|
+ (Raghu Angadi via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1707. The DFSClient does not use a local disk file to cache
|
|
|
+ writes to a HDFS file. Changed Data Transfer Version from 7 to 8.
|
|
|
+ (dhruba)
|
|
|
+
|
|
|
+ HADOOP-2652. Fix permission issues for HftpFileSystem. This is an
|
|
|
+ incompatible change since distcp may not be able to copy files
|
|
|
+ from cluster A (compiled with this patch) to cluster B (compiled
|
|
|
+ with previous versions). (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ NEW FEATURES
|
|
|
+
|
|
|
+ HADOOP-1857. Ability to run a script when a task fails to capture stack
|
|
|
+ traces. (Amareshwari Sri Ramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2299. Defination of a login interface. A simple implementation for
|
|
|
+ Unix users and groups. (Hairong Kuang via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1652. A utility to balance data among datanodes in a HDFS cluster.
|
|
|
+ (Hairong Kuang via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2085. A library to support map-side joins of consistently
|
|
|
+ partitioned and sorted data sets. (Chris Douglas via omalley)
|
|
|
+
|
|
|
+ HADOOP-2336. Shell commands to modify file permissions. (rangadi)
|
|
|
+
|
|
|
+ HADOOP-1298. Implement file permissions for HDFS.
|
|
|
+ (Tsz Wo (Nicholas) & taton via cutting)
|
|
|
+
|
|
|
+ HADOOP-2447. HDFS can be configured to limit the total number of
|
|
|
+ objects (inodes and blocks) in the file system. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-2487. Added an option to get statuses for all submitted/run jobs.
|
|
|
+ This information can be used to develop tools for analysing jobs.
|
|
|
+ (Amareshwari Sri Ramadasu via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-1873. Implement user permissions for Map/Reduce framework.
|
|
|
+ (Hairong Kuang via shv)
|
|
|
+
|
|
|
+ HADOOP-2532. Add to MapFile a getClosest method that returns the key
|
|
|
+ that comes just before if the key is not present. (stack via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-1883. Add versioning to Record I/O. (Vivek Ratan via ddas)
|
|
|
+
|
|
|
+ HADOOP-2603. Add SeqeunceFileAsBinaryInputFormat, which reads
|
|
|
+ sequence files as BytesWritable/BytesWritable regardless of the
|
|
|
+ key and value types used to write the file. (cdouglas via omalley)
|
|
|
+
|
|
|
+ HADOOP-2367. Add ability to profile a subset of map/reduce tasks and fetch
|
|
|
+ the result to the local filesystem of the submitting application. Also
|
|
|
+ includes a general IntegerRanges extension to Configuration for setting
|
|
|
+ positive, ranged parameters. (Owen O'Malley via cdouglas)
|
|
|
+
|
|
|
+ IMPROVEMENTS
|
|
|
+
|
|
|
+ HADOOP-2045. Change committer list on website to a table, so that
|
|
|
+ folks can list their organization, timezone, etc. (cutting)
|
|
|
+
|
|
|
+ HADOOP-2058. Facilitate creating new datanodes dynamically in
|
|
|
+ MiniDFSCluster. (Hairong Kuang via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1855. fsck verifies block placement policies and reports
|
|
|
+ violations. (Konstantin Shvachko via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1604. An system administrator can finalize namenode upgrades
|
|
|
+ without running the cluster. (Konstantin Shvachko via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1839. Link-ify the Pending/Running/Complete/Killed grid in
|
|
|
+ jobdetails.jsp to help quickly narrow down and see categorized TIPs'
|
|
|
+ details via jobtasks.jsp. (Amar Kamat via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-1210. Log counters in job history. (Owen O'Malley via ddas)
|
|
|
+
|
|
|
+ HADOOP-1912. Datanode has two new commands COPY and REPLACE. These are
|
|
|
+ needed for supporting data rebalance. (Hairong Kuang via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2086. This patch adds the ability to add dependencies to a job
|
|
|
+ (run via JobControl) after construction. (Adrian Woodhead via ddas)
|
|
|
+
|
|
|
+ HADOOP-1185. Support changing the logging level of a server without
|
|
|
+ restarting the server. (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2134. Remove developer-centric requirements from overview.html and
|
|
|
+ keep it end-user focussed, specifically sections related to subversion and
|
|
|
+ building Hadoop. (Jim Kellerman via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-1989. Support simulated DataNodes. This helps creating large virtual
|
|
|
+ clusters for testing purposes. (Sanjay Radia via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1274. Support different number of mappers and reducers per
|
|
|
+ TaskTracker to allow administrators to better configure and utilize
|
|
|
+ heterogenous clusters.
|
|
|
+ Configuration changes to hadoop-default.xml:
|
|
|
+ add mapred.tasktracker.map.tasks.maximum (default value of 2)
|
|
|
+ add mapred.tasktracker.reduce.tasks.maximum (default value of 2)
|
|
|
+ remove mapred.tasktracker.tasks.maximum (deprecated for 0.16.0)
|
|
|
+ (Amareshwari Sri Ramadasu via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2104. Adds a description to the ant targets. This makes the
|
|
|
+ output of "ant -projecthelp" sensible. (Chris Douglas via ddas)
|
|
|
+
|
|
|
+ HADOOP-2127. Added a pipes sort example to benchmark trivial pipes
|
|
|
+ application versus trivial java application. (omalley via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2113. A new shell command "dfs -text" to view the contents of
|
|
|
+ a gziped or SequenceFile. (Chris Douglas via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2207. Add a "package" target for contrib modules that
|
|
|
+ permits each to determine what files are copied into release
|
|
|
+ builds. (stack via cutting)
|
|
|
+
|
|
|
+ HADOOP-1984. Makes the backoff for failed fetches exponential.
|
|
|
+ Earlier, it was a random backoff from an interval.
|
|
|
+ (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-1327. Include website documentation for streaming. (Rob Weltman
|
|
|
+ via omalley)
|
|
|
+
|
|
|
+ HADOOP-2000. Rewrite NNBench to measure namenode performance accurately.
|
|
|
+ It now uses the map-reduce framework for load generation.
|
|
|
+ (Mukund Madhugiri via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2248. Speeds up the framework w.r.t Counters. Also has API
|
|
|
+ updates to the Counters part. (Owen O'Malley via ddas)
|
|
|
+
|
|
|
+ HADOOP-2326. The initial block report at Datanode startup time has
|
|
|
+ a random backoff period. (Sanjay Radia via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2432. HDFS includes the name of the file while throwing
|
|
|
+ "File does not exist" exception. (Jim Kellerman via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2457. Added a 'forrest.home' property to the 'docs' target in
|
|
|
+ build.xml. (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2149. A new benchmark for three name-node operation: file create,
|
|
|
+ open, and block report, to evaluate the name-node performance
|
|
|
+ for optimizations or new features. (Konstantin Shvachko via shv)
|
|
|
+
|
|
|
+ HADOOP-2466. Change FileInputFormat.computeSplitSize to a protected
|
|
|
+ non-static method to allow sub-classes to provide alternate
|
|
|
+ implementations. (Alejandro Abdelnur via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2425. Change TextOutputFormat to handle Text specifically for better
|
|
|
+ performance. Make NullWritable implement Comparable. Make TextOutputFormat
|
|
|
+ treat NullWritable like null. (omalley)
|
|
|
+
|
|
|
+ HADOOP-1719. Improves the utilization of shuffle copier threads.
|
|
|
+ (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ HADOOP-2390. Added documentation for user-controls for intermediate
|
|
|
+ map-outputs & final job-outputs and native-hadoop libraries. (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-1660. Add the cwd of the map/reduce task to the java.library.path
|
|
|
+ of the child-jvm to support loading of native libraries distributed via
|
|
|
+ the DistributedCache. (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2285. Speeds up TextInputFormat. Also includes updates to the
|
|
|
+ Text API. (Owen O'Malley via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2233. Adds a generic load generator for modeling MR jobs. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2369. Adds a set of scripts for simulating a mix of user map/reduce
|
|
|
+ workloads. (Runping Qi via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2547. Removes use of a 'magic number' in build.xml.
|
|
|
+ (Hrishikesh via nigel)
|
|
|
+
|
|
|
+ HADOOP-2268. Fix org.apache.hadoop.mapred.jobcontrol classes to use the
|
|
|
+ List/Map interfaces rather than concrete ArrayList/HashMap classes
|
|
|
+ internally. (Adrian Woodhead via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2406. Add a benchmark for measuring read/write performance through
|
|
|
+ the InputFormat interface, particularly with compression. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2131. Allow finer-grained control over speculative-execution. Now
|
|
|
+ users can set it for maps and reduces independently.
|
|
|
+ Configuration changes to hadoop-default.xml:
|
|
|
+ deprecated mapred.speculative.execution
|
|
|
+ add mapred.map.tasks.speculative.execution
|
|
|
+ add mapred.reduce.tasks.speculative.execution
|
|
|
+ (Amareshwari Sri Ramadasu via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-1965. Interleave sort/spill in teh map-task along with calls to the
|
|
|
+ Mapper.map method. This is done by splitting the 'io.sort.mb' buffer into
|
|
|
+ two and using one half for collecting map-outputs and the other half for
|
|
|
+ sort/spill. (Amar Kamat via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2464. Unit tests for chmod, chown, and chgrp using DFS.
|
|
|
+ (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-1876. Persist statuses of completed jobs in HDFS so that the
|
|
|
+ JobClient can query and get information about decommissioned jobs and also
|
|
|
+ across JobTracker restarts.
|
|
|
+ Configuration changes to hadoop-default.xml:
|
|
|
+ add mapred.job.tracker.persist.jobstatus.active (default value of false)
|
|
|
+ add mapred.job.tracker.persist.jobstatus.hours (default value of 0)
|
|
|
+ add mapred.job.tracker.persist.jobstatus.dir (default value of
|
|
|
+ /jobtracker/jobsInfo)
|
|
|
+ (Alejandro Abdelnur via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2077. Added version and build information to STARTUP_MSG for all
|
|
|
+ hadoop daemons to aid error-reporting, debugging etc. (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2398. Additional instrumentation for NameNode and RPC server.
|
|
|
+ Add support for accessing instrumentation statistics via JMX.
|
|
|
+ (Sanjay radia via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2449. A return of the non-MR version of NNBench.
|
|
|
+ (Sanjay Radia via shv)
|
|
|
+
|
|
|
+ HADOOP-1989. Remove 'datanodecluster' command from bin/hadoop.
|
|
|
+ (Sanjay Radia via shv)
|
|
|
+
|
|
|
+ HADOOP-1742. Improve JavaDoc documentation for ClientProtocol, DFSClient,
|
|
|
+ and FSNamesystem. (Konstantin Shvachko)
|
|
|
+
|
|
|
+ HADOOP-2298. Add Ant target for a binary-only distribution.
|
|
|
+ (Hrishikesh via nigel)
|
|
|
+
|
|
|
+ HADOOP-2509. Add Ant target for Rat report (Apache license header
|
|
|
+ reports). (Hrishikesh via nigel)
|
|
|
+
|
|
|
+ HADOOP-2469. WritableUtils.clone should take a Configuration
|
|
|
+ instead of a JobConf. (stack via omalley)
|
|
|
+
|
|
|
+ HADOOP-2659. Introduce superuser permissions for admin operations.
|
|
|
+ (Tsz Wo (Nicholas), SZE via shv)
|
|
|
+
|
|
|
+ HADOOP-2596. Added a SequenceFile.createWriter api which allows the user
|
|
|
+ to specify the blocksize, replication factor and the buffersize to be
|
|
|
+ used for the underlying HDFS file. (Alejandro Abdelnur via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2431. Test HDFS File Permissions. (Hairong Kuang via shv)
|
|
|
+
|
|
|
+ HADOOP-2232. Add an option to disable Nagle's algorithm in the IPC stack.
|
|
|
+ (Clint Morgan via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2342. Created a micro-benchmark for measuring
|
|
|
+ local-file versus hdfs reads. (Owen O'Malley via nigel)
|
|
|
+
|
|
|
+ HADOOP-2529. First version of HDFS User Guide. (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-2690. Add jar-test target to build.xml, separating compilation
|
|
|
+ and packaging of the test classes. (Enis Soztutar via cdouglas)
|
|
|
+
|
|
|
+ OPTIMIZATIONS
|
|
|
+
|
|
|
+ HADOOP-1898. Release the lock protecting the last time of the last stack
|
|
|
+ dump while the dump is happening. (Amareshwari Sri Ramadasu via omalley)
|
|
|
+
|
|
|
+ HADOOP-1900. Makes the heartbeat and task event queries interval
|
|
|
+ dependent on the cluster size. (Amareshwari Sri Ramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2208. Counter update frequency (from TaskTracker to JobTracker) is
|
|
|
+ capped at 1 minute. (Amareshwari Sri Ramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2284. Reduce the number of progress updates during the sorting in
|
|
|
+ the map task. (Amar Kamat via ddas)
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-2583. Fixes a bug in the Eclipse plug-in UI to edit locations.
|
|
|
+ Plug-in version is now synchronized with Hadoop version.
|
|
|
+
|
|
|
+ HADOOP-2100. Remove faulty check for existence of $HADOOP_PID_DIR and let
|
|
|
+ 'mkdir -p' check & create it. (Michael Bieniosek via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-1642. Ensure jobids generated by LocalJobRunner are unique to
|
|
|
+ avoid collissions and hence job-failures. (Doug Cutting via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2096. Close open file-descriptors held by streams while localizing
|
|
|
+ job.xml in the JobTracker and while displaying it on the webui in
|
|
|
+ jobconf.jsp. (Amar Kamat via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2098. Log start & completion of empty jobs to JobHistory, which
|
|
|
+ also ensures that we close the file-descriptor of the job's history log
|
|
|
+ opened during job-submission. (Amar Kamat via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2112. Adding back changes to build.xml lost while reverting
|
|
|
+ HADOOP-1622 i.e. http://svn.apache.org/viewvc?view=rev&revision=588771.
|
|
|
+ (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2089. Fixes the command line argument handling to handle multiple
|
|
|
+ -cacheArchive in Hadoop streaming. (Lohit Vijayarenu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2071. Fix StreamXmlRecordReader to use a BufferedInputStream
|
|
|
+ wrapped over the DFSInputStream since mark/reset aren't supported by
|
|
|
+ DFSInputStream anymore. (Lohit Vijayarenu via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-1348. Allow XML comments inside configuration files.
|
|
|
+ (Rajagopal Natarajan and Enis Soztutar via enis)
|
|
|
+
|
|
|
+ HADOOP-1952. Improve handling of invalid, user-specified classes while
|
|
|
+ configuring streaming jobs such as combiner, input/output formats etc.
|
|
|
+ Now invalid options are caught, logged and jobs are failed early. (Lohit
|
|
|
+ Vijayarenu via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2151. FileSystem.globPaths validates the list of Paths that
|
|
|
+ it returns. (Lohit Vijayarenu via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2121. Cleanup DFSOutputStream when the stream encountered errors
|
|
|
+ when Datanodes became full. (Raghu Angadi via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1130. The FileSystem.closeAll() method closes all existing
|
|
|
+ DFSClients. (Chris Douglas via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2204. DFSTestUtil.waitReplication was not waiting for all replicas
|
|
|
+ to get created, thus causing unit test failure.
|
|
|
+ (Raghu Angadi via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2078. An zero size file may have no blocks associated with it.
|
|
|
+ (Konstantin Shvachko via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2212. ChecksumFileSystem.getSumBufferSize might throw
|
|
|
+ java.lang.ArithmeticException. The fix is to initialize bytesPerChecksum
|
|
|
+ to 0. (Michael Bieniosek via ddas)
|
|
|
+
|
|
|
+ HADOOP-2216. Fix jobtasks.jsp to ensure that it first collects the
|
|
|
+ taskids which satisfy the filtering criteria and then use that list to
|
|
|
+ print out only the required task-reports, previously it was oblivious to
|
|
|
+ the filtering and hence used the wrong index into the array of task-reports.
|
|
|
+ (Amar Kamat via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2272. Fix findbugs target to reflect changes made to the location
|
|
|
+ of the streaming jar file by HADOOP-2207. (Adrian Woodhead via nigel)
|
|
|
+
|
|
|
+ HADOOP-2244. Fixes the MapWritable.readFields to clear the instance
|
|
|
+ field variable every time readFields is called. (Michael Stack via ddas).
|
|
|
+
|
|
|
+ HADOOP-2245. Fixes LocalJobRunner to include a jobId in the mapId. Also,
|
|
|
+ adds a testcase for JobControl. (Adrian Woodhead via ddas).
|
|
|
+
|
|
|
+ HADOOP-2275. Fix erroneous detection of corrupted file when namenode
|
|
|
+ fails to allocate any datanodes for newly allocated block.
|
|
|
+ (Dhruba Borthakur via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2256. Fix a buf in the namenode that could cause it to encounter
|
|
|
+ an infinite loop while deleting excess replicas that were created by
|
|
|
+ block rebalancing. (Hairong Kuang via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2209. SecondaryNamenode process exits if it encounters exceptions
|
|
|
+ that it cannot handle. (Dhruba Borthakur via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2314. Prevent TestBlockReplacement from occasionally getting
|
|
|
+ into an infinite loop. (Hairong Kuang via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2300. This fixes a bug where mapred.tasktracker.tasks.maximum
|
|
|
+ would be ignored even if it was set in hadoop-site.xml.
|
|
|
+ (Amareshwari Sri Ramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2349. Improve code layout in file system transaction logging code.
|
|
|
+ (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2368. Fix unit tests on Windows.
|
|
|
+ (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2363. This fix allows running multiple instances of the unit test
|
|
|
+ in parallel. The bug was introduced in HADOOP-2185 that changed
|
|
|
+ port-rolling behaviour. (Konstantin Shvachko via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2271. Fix chmod task to be non-parallel. (Adrian Woodhead via
|
|
|
+ omalley)
|
|
|
+
|
|
|
+ HADOOP-2313. Fail the build if building libhdfs fails. (nigel via omalley)
|
|
|
+
|
|
|
+ HADOOP-2359. Remove warning for interruptted exception when closing down
|
|
|
+ minidfs. (dhruba via omalley)
|
|
|
+
|
|
|
+ HADOOP-1841. Prevent slow clients from consuming threads in the NameNode.
|
|
|
+ (dhruba)
|
|
|
+
|
|
|
+ HADOOP-2323. JobTracker.close() should not print stack traces for
|
|
|
+ normal exit. (jimk via cutting)
|
|
|
+
|
|
|
+ HADOOP-2376. Prevents sort example from overriding the number of maps.
|
|
|
+ (Owen O'Malley via ddas)
|
|
|
+
|
|
|
+ HADOOP-2434. FSDatasetInterface read interface causes HDFS reads to occur
|
|
|
+ in 1 byte chunks, causing performance degradation.
|
|
|
+ (Raghu Angadi via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2459. Fix package target so that src/docs/build files are not
|
|
|
+ included in the release. (nigel)
|
|
|
+
|
|
|
+ HADOOP-2215. Fix documentation in cluster_setup.html &
|
|
|
+ mapred_tutorial.html reflect that mapred.tasktracker.tasks.maximum has
|
|
|
+ been superceeded by mapred.tasktracker.{map|reduce}.tasks.maximum.
|
|
|
+ (Amareshwari Sri Ramadasu via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2459. Fix package target so that src/docs/build files are not
|
|
|
+ included in the release. (nigel)
|
|
|
+
|
|
|
+ HADOOP-2352. Remove AC_CHECK_LIB for libz and liblzo to ensure that
|
|
|
+ libhadoop.so doesn't have a dependency on them. (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2453. Fix the configuration for wordcount-simple example in Hadoop
|
|
|
+ Pipes which currently produces an XML parsing error. (Amareshwari Sri
|
|
|
+ Ramadasu via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2476. Unit test failure while reading permission bits of local
|
|
|
+ file system (on Windows) fixed. (Raghu Angadi via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2247. Fine-tune the strategies for killing mappers and reducers
|
|
|
+ due to failures while fetching map-outputs. Now the map-completion times
|
|
|
+ and number of currently running reduces are taken into account by the
|
|
|
+ JobTracker before killing the mappers, while the progress made by the
|
|
|
+ reducer and the number of fetch-failures vis-a-vis total number of
|
|
|
+ fetch-attempts are taken into account before teh reducer kills itself.
|
|
|
+ (Amar Kamat via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2452. Fix eclipse plug-in build.xml to refers to the right
|
|
|
+ location where hadoop-*-core.jar is generated. (taton)
|
|
|
+
|
|
|
+ HADOOP-2492. Additional debugging in the rpc server to better
|
|
|
+ diagnose ConcurrentModificationException. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-2344. Enhance the utility for executing shell commands to read the
|
|
|
+ stdout/stderr streams while waiting for the command to finish (to free up
|
|
|
+ the buffers). Also, this patch throws away stderr of the DF utility.
|
|
|
+ @deprecated
|
|
|
+ org.apache.hadoop.fs.ShellCommand for org.apache.hadoop.util.Shell
|
|
|
+ org.apache.hadoop.util.ShellUtil for
|
|
|
+ org.apache.hadoop.util.Shell.ShellCommandExecutor
|
|
|
+ (Amar Kamat via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2511. Fix a javadoc warning in org.apache.hadoop.util.Shell
|
|
|
+ introduced by HADOOP-2344. (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2442. Fix TestLocalFileSystemPermission.testLocalFSsetOwner
|
|
|
+ to work on more platforms. (Raghu Angadi via nigel)
|
|
|
+
|
|
|
+ HADOOP-2488. Fix a regression in random read performance.
|
|
|
+ (Michael Stack via rangadi)
|
|
|
+
|
|
|
+ HADOOP-2523. Fix TestDFSShell.testFilePermissions on Windows.
|
|
|
+ (Raghu Angadi via nigel)
|
|
|
+
|
|
|
+ HADOOP-2535. Removed support for deprecated mapred.child.heap.size and
|
|
|
+ fixed some indentation issues in TaskRunner. (acmurthy)
|
|
|
+ Configuration changes to hadoop-default.xml:
|
|
|
+ remove mapred.child.heap.size
|
|
|
+
|
|
|
+ HADOOP-2512. Fix error stream handling in Shell. Use exit code to
|
|
|
+ detect shell command errors in RawLocalFileSystem. (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-2446. Fixes TestHDFSServerPorts and TestMRServerPorts so they
|
|
|
+ do not rely on statically configured ports and cleanup better. (nigel)
|
|
|
+
|
|
|
+ HADOOP-2537. Make build process compatible with Ant 1.7.0.
|
|
|
+ (Hrishikesh via nigel)
|
|
|
+
|
|
|
+ HADOOP-1281. Ensure running tasks of completed map TIPs (e.g. speculative
|
|
|
+ tasks) are killed as soon as the TIP completed. (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2571. Suppress a suprious warning in test code. (cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2481. NNBench report its progress periodically.
|
|
|
+ (Hairong Kuang via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2601. Start name-node on a free port for TestNNThroughputBenchmark.
|
|
|
+ (Konstantin Shvachko)
|
|
|
+
|
|
|
+ HADOOP-2494. Set +x on contrib/*/bin/* in packaged tar bundle.
|
|
|
+ (stack via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-2605. Remove bogus leading slash in task-tracker report bindAddress.
|
|
|
+ (Konstantin Shvachko)
|
|
|
+
|
|
|
+ HADOOP-2620. Trivial. 'bin/hadoop fs -help' did not list chmod, chown, and
|
|
|
+ chgrp. (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-2614. The DFS WebUI accesses are configured to be from the user
|
|
|
+ specified by dfs.web.ugi. (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2543. Implement a "no-permission-checking" mode for smooth
|
|
|
+ upgrade from a pre-0.16 install of HDFS.
|
|
|
+ (Hairong Kuang via dhruba)
|
|
|
+
|
|
|
+ HADOOP-290. A DataNode log message now prints the target of a replication
|
|
|
+ request correctly. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-2538. Redirect to a warning, if plaintext parameter is true but
|
|
|
+ the filter parameter is not given in TaskLogServlet.
|
|
|
+ (Michael Bieniosek via enis)
|
|
|
+
|
|
|
+ HADOOP-2582. Prevent 'bin/hadoop fs -copyToLocal' from creating
|
|
|
+ zero-length files when the src does not exist.
|
|
|
+ (Lohit Vijayarenu via cdouglas)
|
|
|
+
|
|
|
+ HADOOP-2189. Incrementing user counters should count as progress. (ddas)
|
|
|
+
|
|
|
+ HADOOP-2649. The NameNode periodically computes replication work for
|
|
|
+ the datanodes. The periodicity of this computation is now configurable.
|
|
|
+ (dhruba)
|
|
|
+
|
|
|
+ HADOOP-2549. Correct disk size computation so that data-nodes could switch
|
|
|
+ to other local drives if current is full. (Hairong Kuang via shv)
|
|
|
+
|
|
|
+ HADOOP-2633. Fsck should call name-node methods directly rather than
|
|
|
+ through rpc. (Tsz Wo (Nicholas), SZE via shv)
|
|
|
+
|
|
|
+ HADOOP-2687. Modify a few log message generated by dfs client to be
|
|
|
+ logged only at INFO level. (stack via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2402. Fix BlockCompressorStream to ensure it buffers data before
|
|
|
+ sending it down to the compressor so that each write call doesn't
|
|
|
+ compress. (Chris Douglas via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2645. The Metrics initialization code does not throw
|
|
|
+ exceptions when servers are restarted by MiniDFSCluster.
|
|
|
+ (Sanjay Radia via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2691. Fix a race condition that was causing the DFSClient
|
|
|
+ to erroneously remove a good datanode from a pipeline that actually
|
|
|
+ had another datanode that was bad. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-1195. All code in FSNamesystem checks the return value
|
|
|
+ of getDataNode for null before using it. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-2640. Fix a bug in MultiFileSplitInputFormat that was always
|
|
|
+ returning 1 split in some circumstances. (Enis Soztutar via nigel)
|
|
|
+
|
|
|
+ HADOOP-2626. Fix paths with special characters to work correctly
|
|
|
+ with the local filesystem. (Thomas Friol via cutting)
|
|
|
+
|
|
|
+ HADOOP-2646. Fix SortValidator to work with fully-qualified
|
|
|
+ working directories. (Arun C Murthy via nigel)
|
|
|
+
|
|
|
+ HADOOP-2092. Added a ping mechanism to the pipes' task to periodically
|
|
|
+ check if the parent Java task is running, and exit if the parent isn't
|
|
|
+ alive and responding. (Amareshwari Sri Ramadasu via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2714. TestDecommission failed on windows because the replication
|
|
|
+ request was timing out. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-2576. Namenode performance degradation over time triggered by
|
|
|
+ large heartbeat interval. (Raghu Angadi)
|
|
|
+
|
|
|
+ HADOOP-2713. TestDatanodeDeath failed on windows because the replication
|
|
|
+ request was timing out. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-2639. Fixes a problem to do with incorrect maintenance of values
|
|
|
+ for runningMapTasks/runningReduceTasks. (Amar Kamat and Arun Murthy
|
|
|
+ via ddas)
|
|
|
+
|
|
|
+ HADOOP-2723. Fixed the check for checking whether to do user task
|
|
|
+ profiling. (Amareshwari Sri Ramadasu via omalley)
|
|
|
+
|
|
|
+ HADOOP-2734. Link forrest docs to new http://hadoop.apache.org
|
|
|
+ (Doug Cutting via nigel)
|
|
|
+
|
|
|
+ HADOOP-2641. Added Apache license headers to 95 files. (nigel)
|
|
|
+
|
|
|
+ HADOOP-2732. Fix bug in path globbing. (Hairong Kuang via nigel)
|
|
|
+
|
|
|
+ HADOOP-2404. Fix backwards compatability with hadoop-0.15 configuration
|
|
|
+ files that was broken by HADOOP-2185. (omalley)
|
|
|
+
|
|
|
+ HADOOP-2755. Fix fsck performance degradation because of permissions
|
|
|
+ issue. (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2768. Fix performance regression caused by HADOOP-1707.
|
|
|
+ (dhruba borthakur via nigel)
|
|
|
+
|
|
|
+ HADOOP-3108. Fix NPE in setPermission and setOwner. (shv)
|
|
|
+
|
|
|
+Release 0.15.3 - 2008-01-18
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-2562. globPaths supports {ab,cd}. (Hairong Kuang via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2540. fsck reports missing blocks incorrectly. (dhruba)
|
|
|
+
|
|
|
+ HADOOP-2570. "work" directory created unconditionally, and symlinks
|
|
|
+ created from the task cwds.
|
|
|
+
|
|
|
+ HADOOP-2574. Fixed mapred_tutorial.xml to correct minor errors with the
|
|
|
+ WordCount examples. (acmurthy)
|
|
|
+
|
|
|
+Release 0.15.2 - 2008-01-02
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-2246. Moved the changelog for HADOOP-1851 from the NEW FEATURES
|
|
|
+ section to the INCOMPATIBLE CHANGES section. (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2238. Fix TaskGraphServlet so that it sets the content type of
|
|
|
+ the response appropriately. (Paul Saab via enis)
|
|
|
+
|
|
|
+ HADOOP-2129. Fix so that distcp works correctly when source is
|
|
|
+ HDFS but not the default filesystem. HDFS paths returned by the
|
|
|
+ listStatus() method are now fully-qualified. (cutting)
|
|
|
+
|
|
|
+ HADOOP-2378. Fixes a problem where the last task completion event would
|
|
|
+ get created after the job completes. (Alejandro Abdelnur via ddas)
|
|
|
+
|
|
|
+ HADOOP-2228. Checks whether a job with a certain jobId is already running
|
|
|
+ and then tries to create the JobInProgress object.
|
|
|
+ (Johan Oskarsson via ddas)
|
|
|
+
|
|
|
+ HADOOP-2422. dfs -cat multiple files fail with 'Unable to write to
|
|
|
+ output stream'. (Raghu Angadi via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2460. When the namenode encounters ioerrors on writing a
|
|
|
+ transaction log, it stops writing new transactions to that one.
|
|
|
+ (Raghu Angadi via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2227. Use the LocalDirAllocator uniformly for handling all of the
|
|
|
+ temporary storage required for a given task. It also implies that
|
|
|
+ mapred.local.dir.minspacestart is handled by checking if there is enough
|
|
|
+ free-space on any one of the available disks. (Amareshwari Sri Ramadasu
|
|
|
+ via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2437. Fix the LocalDirAllocator to choose the seed for the
|
|
|
+ round-robin disk selections randomly. This helps in spreading data across
|
|
|
+ multiple partitions much better. (acmurhty)
|
|
|
+
|
|
|
+ HADOOP-2486. When the list of files from the InMemoryFileSystem is obtained
|
|
|
+ for merging, this patch will ensure that only those files whose checksums
|
|
|
+ have also got created (renamed) are returned. (ddas)
|
|
|
+
|
|
|
+ HADOOP-2456. Hardcode English locale to prevent NumberFormatException
|
|
|
+ from occurring when starting the NameNode with certain locales.
|
|
|
+ (Matthias Friedrich via nigel)
|
|
|
+
|
|
|
+ IMPROVEMENTS
|
|
|
+
|
|
|
+ HADOOP-2160. Remove project-level, non-user documentation from
|
|
|
+ releases, since it's now maintained in a separate tree. (cutting)
|
|
|
+
|
|
|
+ HADOOP-1327. Add user documentation for streaming. (cutting)
|
|
|
+
|
|
|
+ HADOOP-2382. Add hadoop-default.html to subversion. (cutting)
|
|
|
+
|
|
|
+ HADOOP-2158. hdfsListDirectory calls FileSystem.listStatus instead
|
|
|
+ of FileSystem.listPaths. This reduces the number of RPC calls on the
|
|
|
+ namenode, thereby improving scalability. (Christian Kunz via dhruba)
|
|
|
+
|
|
|
+Release 0.15.1 - 2007-11-27
|
|
|
+
|
|
|
+ INCOMPATIBLE CHANGES
|
|
|
+
|
|
|
+ HADOOP-713. Reduce CPU usage on namenode while listing directories.
|
|
|
+ FileSystem.listPaths does not return the size of the entire subtree.
|
|
|
+ Introduced a new API ClientProtocol.getContentLength that returns the
|
|
|
+ size of the subtree. (Dhruba Borthakur via dhruba)
|
|
|
+
|
|
|
+ IMPROVEMENTS
|
|
|
+
|
|
|
+ HADOOP-1917. Addition of guides/tutorial for better overall
|
|
|
+ documentation for Hadoop. Specifically:
|
|
|
+ * quickstart.html is targetted towards first-time users and helps them
|
|
|
+ setup a single-node cluster and play with Hadoop.
|
|
|
+ * cluster_setup.html helps admins to configure and setup non-trivial
|
|
|
+ hadoop clusters.
|
|
|
+ * mapred_tutorial.html is a comprehensive Map-Reduce tutorial.
|
|
|
+ (acmurthy)
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-2174. Removed the unnecessary Reporter.setStatus call from
|
|
|
+ FSCopyFilesMapper.close which led to a NPE since the reporter isn't valid
|
|
|
+ in the close method. (Chris Douglas via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2172. Restore performance of random access to local files
|
|
|
+ by caching positions of local input streams, avoiding a system
|
|
|
+ call. (cutting)
|
|
|
+
|
|
|
+ HADOOP-2205. Regenerate the Hadoop website since some of the changes made
|
|
|
+ by HADOOP-1917 weren't correctly copied over to the trunk/docs directory.
|
|
|
+ Also fixed a couple of minor typos and broken links. (acmurthy)
|
|
|
+
|
|
|
+Release 0.15.0 - 2007-11-2
|
|
|
+
|
|
|
+ INCOMPATIBLE CHANGES
|
|
|
+
|
|
|
+ HADOOP-1708. Make files appear in namespace as soon as they are
|
|
|
+ created. (Dhruba Borthakur via dhruba)
|
|
|
+
|
|
|
+ HADOOP-999. A HDFS Client immediately informs the NameNode of a new
|
|
|
+ file creation. ClientProtocol version changed from 14 to 15.
|
|
|
+ (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-932. File locking interfaces and implementations (that were
|
|
|
+ earlier deprecated) are removed. Client Protocol version changed
|
|
|
+ from 15 to 16. (Raghu Angadi via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1621. FileStatus is now a concrete class and FileSystem.listPaths
|
|
|
+ is deprecated and replaced with listStatus. (Chris Douglas via omalley)
|
|
|
+
|
|
|
+ HADOOP-1656. The blockSize of a file is stored persistently in the file
|
|
|
+ inode. (Dhruba Borthakur via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1838. The blocksize of files created with an earlier release is
|
|
|
+ set to the default block size. (Dhruba Borthakur via dhruba)
|
|
|
+
|
|
|
+ HADOOP-785. Add support for 'final' Configuration parameters,
|
|
|
+ removing support for 'mapred-default.xml', and changing
|
|
|
+ 'hadoop-site.xml' to not override other files. Now folks should
|
|
|
+ generally use 'hadoop-site.xml' for all configurations. Values
|
|
|
+ with a 'final' tag may not be overridden by subsequently loaded
|
|
|
+ configuration files, e.g., by jobs. (Arun C. Murthy via cutting)
|
|
|
+
|
|
|
+ HADOOP-1846. DatanodeReport in ClientProtocol can report live
|
|
|
+ datanodes, dead datanodes or all datanodes. Client Protocol version
|
|
|
+ changed from 17 to 18. (Hairong Kuang via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1851. Permit specification of map output compression type
|
|
|
+ and codec, independent of the final output's compression
|
|
|
+ parameters. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+ HADOOP-1819. Jobtracker cleanups, including binding ports before
|
|
|
+ clearing state directories, so that inadvertently starting a
|
|
|
+ second jobtracker doesn't trash one that's already running. Removed
|
|
|
+ method JobTracker.getTracker() because the static variable, which
|
|
|
+ stored the value caused initialization problems.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+ NEW FEATURES
|
|
|
+
|
|
|
+ HADOOP-89. A client can access file data even before the creator
|
|
|
+ has closed the file. Introduce a new command "tail" from dfs shell.
|
|
|
+ (Dhruba Borthakur via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1636. Allow configuration of the number of jobs kept in
|
|
|
+ memory by the JobTracker. (Michael Bieniosek via omalley)
|
|
|
+
|
|
|
+ HADOOP-1667. Reorganize CHANGES.txt into sections to make it
|
|
|
+ easier to read. Also remove numbering, to make merging easier.
|
|
|
+ (cutting)
|
|
|
+
|
|
|
+ HADOOP-1610. Add metrics for failed tasks.
|
|
|
+ (Devaraj Das via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-1767. Add "bin/hadoop job -list" sub-command. (taton via cutting)
|
|
|
+
|
|
|
+ HADOOP-1351. Add "bin/hadoop job [-fail-task|-kill-task]" sub-commands
|
|
|
+ to terminate a particular task-attempt. (Enis Soztutar via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-1880. SleepJob : An example job that sleeps at each map and
|
|
|
+ reduce task. (enis)
|
|
|
+
|
|
|
+ HADOOP-1809. Add a link in web site to #hadoop IRC channel. (enis)
|
|
|
+
|
|
|
+ HADOOP-1894. Add percentage graphs and mapred task completion graphs
|
|
|
+ to Web User Interface. Users not using Firefox may install a plugin to
|
|
|
+ their browsers to see svg graphics. (enis)
|
|
|
+
|
|
|
+ HADOOP-1914. Introduce a new NamenodeProtocol to allow secondary
|
|
|
+ namenodes and rebalancing processes to communicate with a primary
|
|
|
+ namenode. (Hairong Kuang via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1963. Add a FileSystem implementation for the Kosmos
|
|
|
+ Filesystem (KFS). (Sriram Rao via cutting)
|
|
|
+
|
|
|
+ HADOOP-1822. Allow the specialization and configuration of socket
|
|
|
+ factories. Provide a StandardSocketFactory, and a SocksSocketFactory to
|
|
|
+ allow the use of SOCKS proxies. (taton).
|
|
|
+
|
|
|
+ HADOOP-1968. FileSystem supports wildcard input syntax "{ }".
|
|
|
+ (Hairong Kuang via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2566. Add globStatus method to the FileSystem interface
|
|
|
+ and deprecate globPath and listPath. (Hairong Kuang via hairong)
|
|
|
+
|
|
|
+ OPTIMIZATIONS
|
|
|
+
|
|
|
+ HADOOP-1910. Reduce the number of RPCs that DistributedFileSystem.create()
|
|
|
+ makes to the namenode. (Raghu Angadi via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1565. Reduce memory usage of NameNode by replacing
|
|
|
+ TreeMap in HDFS Namespace with ArrayList.
|
|
|
+ (Dhruba Borthakur via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1743. Change DFS INode from a nested class to standalone
|
|
|
+ class, with specialized subclasses for directories and files, to
|
|
|
+ save memory on the namenode. (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+ HADOOP-1759. Change file name in INode from String to byte[],
|
|
|
+ saving memory on the namenode. (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+ HADOOP-1766. Save memory in namenode by having BlockInfo extend
|
|
|
+ Block, and replace many uses of Block with BlockInfo.
|
|
|
+ (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+ HADOOP-1687. Save memory in namenode by optimizing BlockMap
|
|
|
+ representation. (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+ HADOOP-1774. Remove use of INode.parent in Block CRC upgrade.
|
|
|
+ (Raghu Angadi via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1788. Increase the buffer size on the Pipes command socket.
|
|
|
+ (Amareshwari Sri Ramadasu and Christian Kunz via omalley)
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-1946. The Datanode code does not need to invoke du on
|
|
|
+ every heartbeat. (Hairong Kuang via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1935. Fix a NullPointerException in internalReleaseCreate.
|
|
|
+ (Dhruba Borthakur)
|
|
|
+
|
|
|
+ HADOOP-1933. The nodes listed in include and exclude files
|
|
|
+ are always listed in the datanode report.
|
|
|
+ (Raghu Angadi via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1953. The job tracker should wait beteween calls to try and delete
|
|
|
+ the system directory (Owen O'Malley via devaraj)
|
|
|
+
|
|
|
+ HADOOP-1932. TestFileCreation fails with message saying filestatus.dat
|
|
|
+ is of incorrect size. (Dhruba Borthakur via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1573. Support for 0 reducers in PIPES.
|
|
|
+ (Owen O'Malley via devaraj)
|
|
|
+
|
|
|
+ HADOOP-1500. Fix typographical errors in the DFS WebUI.
|
|
|
+ (Nigel Daley via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1076. Periodic checkpoint can continue even if an earlier
|
|
|
+ checkpoint encountered an error. (Dhruba Borthakur via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1887. The Namenode encounters an ArrayIndexOutOfBoundsException
|
|
|
+ while listing a directory that had a file that was
|
|
|
+ being actively written to. (Dhruba Borthakur via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1904. The Namenode encounters an exception because the
|
|
|
+ list of blocks per datanode-descriptor was corrupted.
|
|
|
+ (Konstantin Shvachko via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1762. The Namenode fsimage does not contain a list of
|
|
|
+ Datanodes. (Raghu Angadi via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1890. Removed debugging prints introduced by HADOOP-1774.
|
|
|
+ (Raghu Angadi via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1763. Too many lost task trackers on large clusters due to
|
|
|
+ insufficient number of RPC handler threads on the JobTracker.
|
|
|
+ (Devaraj Das)
|
|
|
+
|
|
|
+ HADOOP-1463. HDFS report correct usage statistics for disk space
|
|
|
+ used by HDFS. (Hairong Kuang via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1692. In DFS ant task, don't cache the Configuration.
|
|
|
+ (Chris Douglas via cutting)
|
|
|
+
|
|
|
+ HADOOP-1726. Remove lib/jetty-ext/ant.jar. (omalley)
|
|
|
+
|
|
|
+ HADOOP-1772. Fix hadoop-daemon.sh script to get correct hostname
|
|
|
+ under Cygwin. (Tsz Wo (Nicholas), SZE via cutting)
|
|
|
+
|
|
|
+ HADOOP-1749. Change TestDFSUpgrade to sort files, fixing sporadic
|
|
|
+ test failures. (Enis Soztutar via cutting)
|
|
|
+
|
|
|
+ HADOOP-1748. Fix tasktracker to be able to launch tasks when log
|
|
|
+ directory is relative. (omalley via cutting)
|
|
|
+
|
|
|
+ HADOOP-1775. Fix a NullPointerException and an
|
|
|
+ IllegalArgumentException in MapWritable.
|
|
|
+ (Jim Kellerman via cutting)
|
|
|
+
|
|
|
+ HADOOP-1795. Fix so that jobs can generate output file names with
|
|
|
+ special characters. (Fr??d??ric Bertin via cutting)
|
|
|
+
|
|
|
+ HADOOP-1810. Fix incorrect value type in MRBench (SmallJobs)
|
|
|
+ (Devaraj Das via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-1806. Fix ant task to compile again, also fix default
|
|
|
+ builds to compile ant tasks. (Chris Douglas via cutting)
|
|
|
+
|
|
|
+ HADOOP-1758. Fix escape processing in librecordio to not be
|
|
|
+ quadratic. (Vivek Ratan via cutting)
|
|
|
+
|
|
|
+ HADOOP-1817. Fix MultiFileSplit to read and write the split
|
|
|
+ length, so that it is not always zero in map tasks.
|
|
|
+ (Thomas Friol via cutting)
|
|
|
+
|
|
|
+ HADOOP-1853. Fix contrib/streaming to accept multiple -cacheFile
|
|
|
+ options. (Prachi Gupta via cutting)
|
|
|
+
|
|
|
+ HADOOP-1818. Fix MultiFileInputFormat so that it does not return
|
|
|
+ empty splits when numPaths < numSplits. (Thomas Friol via enis)
|
|
|
+
|
|
|
+ HADOOP-1840. Fix race condition which leads to task's diagnostic
|
|
|
+ messages getting lost. (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-1885. Fix race condition in MiniDFSCluster shutdown.
|
|
|
+ (Chris Douglas via nigel)
|
|
|
+
|
|
|
+ HADOOP-1889. Fix path in EC2 scripts for building your own AMI.
|
|
|
+ (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-1892. Fix a NullPointerException in the JobTracker when
|
|
|
+ trying to fetch a task's diagnostic messages from the JobClient.
|
|
|
+ (Amar Kamat via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-1897. Completely remove about.html page from the web site.
|
|
|
+ (enis)
|
|
|
+
|
|
|
+ HADOOP-1907. Fix null pointer exception when getting task diagnostics
|
|
|
+ in JobClient. (Christian Kunz via omalley)
|
|
|
+
|
|
|
+ HADOOP-1882. Remove spurious asterisks from decimal number displays.
|
|
|
+ (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+ HADOOP-1783. Make S3 FileSystem return Paths fully-qualified with
|
|
|
+ scheme and host. (tomwhite)
|
|
|
+
|
|
|
+ HADOOP-1925. Make pipes' autoconf script look for libsocket and libnsl, so
|
|
|
+ that it can compile under Solaris. (omalley)
|
|
|
+
|
|
|
+ HADOOP-1940. TestDFSUpgradeFromImage must shut down its MiniDFSCluster.
|
|
|
+ (Chris Douglas via nigel)
|
|
|
+
|
|
|
+ HADOOP-1930. Fix the blame for failed fetchs on the right host. (Arun C.
|
|
|
+ Murthy via omalley)
|
|
|
+
|
|
|
+ HADOOP-1934. Fix the platform name on Mac to use underscores rather than
|
|
|
+ spaces. (omalley)
|
|
|
+
|
|
|
+ HADOOP-1959. Use "/" instead of File.separator in the StatusHttpServer.
|
|
|
+ (jimk via omalley)
|
|
|
+
|
|
|
+ HADOOP-1626. Improve dfsadmin help messages.
|
|
|
+ (Lohit Vijayarenu via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1695. The SecondaryNamenode waits for the Primary NameNode to
|
|
|
+ start up. (Dhruba Borthakur)
|
|
|
+
|
|
|
+ HADOOP-1983. Have Pipes flush the command socket when progress is sent
|
|
|
+ to prevent timeouts during long computations. (omalley)
|
|
|
+
|
|
|
+ HADOOP-1875. Non-existant directories or read-only directories are
|
|
|
+ filtered from dfs.client.buffer.dir. (Hairong Kuang via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1992. Fix the performance degradation in the sort validator.
|
|
|
+ (acmurthy via omalley)
|
|
|
+
|
|
|
+ HADOOP-1874. Move task-outputs' promotion/discard to a separate thread
|
|
|
+ distinct from the main heartbeat-processing thread. The main upside being
|
|
|
+ that we do not lock-up the JobTracker during HDFS operations, which
|
|
|
+ otherwise may lead to lost tasktrackers if the NameNode is unresponsive.
|
|
|
+ (Devaraj Das via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2026. Namenode prints out one log line for "Number of transactions"
|
|
|
+ at most once every minute. (Dhruba Borthakur)
|
|
|
+
|
|
|
+ HADOOP-2022. Ensure that status information for successful tasks is correctly
|
|
|
+ recorded at the JobTracker, so that, for example, one may view correct
|
|
|
+ information via taskdetails.jsp. This bug was introduced by HADOOP-1874.
|
|
|
+ (Amar Kamat via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2031. Correctly maintain the taskid which takes the TIP to
|
|
|
+ completion, failing which the case of lost tasktrackers isn't handled
|
|
|
+ properly i.e. the map TIP is incorrectly left marked as 'complete' and it
|
|
|
+ is never rescheduled elsewhere, leading to hung reduces.
|
|
|
+ (Devaraj Das via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2018. The source datanode of a data transfer waits for
|
|
|
+ a response from the target datanode before closing the data stream.
|
|
|
+ (Hairong Kuang via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2023. Disable TestLocalDirAllocator on Windows.
|
|
|
+ (Hairong Kuang via nigel)
|
|
|
+
|
|
|
+ HADOOP-2016. Ignore status-updates from FAILED/KILLED tasks at the
|
|
|
+ TaskTracker. This fixes a race-condition which caused the tasks to wrongly
|
|
|
+ remain in the RUNNING state even after being killed by the JobTracker and
|
|
|
+ thus handicap the cleanup of the task's output sub-directory. (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-1771. Fix a NullPointerException in streaming caused by an
|
|
|
+ IOException in MROutputThread. (lohit vijayarenu via nigel)
|
|
|
+
|
|
|
+ HADOOP-2028. Fix distcp so that the log dir does not need to be
|
|
|
+ specified and the destination does not need to exist.
|
|
|
+ (Chris Douglas via nigel)
|
|
|
+
|
|
|
+ HADOOP-2044. The namenode protects all lease manipulations using a
|
|
|
+ sortedLease lock. (Dhruba Borthakur)
|
|
|
+
|
|
|
+ HADOOP-2051. The TaskCommit thread should not die for exceptions other
|
|
|
+ than the InterruptedException. This behavior is there for the other long
|
|
|
+ running threads in the JobTracker. (Arun C Murthy via ddas)
|
|
|
+
|
|
|
+ HADOOP-1973. The FileSystem object would be accessed on the JobTracker
|
|
|
+ through a RPC in the InterTrackerProtocol. The check for the object being
|
|
|
+ null was missing and hence NPE would be thrown sometimes. This issue fixes
|
|
|
+ that problem. (Amareshwari Sri Ramadasu via ddas)
|
|
|
+
|
|
|
+ HADOOP-2033. The SequenceFile.Writer.sync method was a no-op, which caused
|
|
|
+ very uneven splits for applications like distcp that count on them.
|
|
|
+ (omalley)
|
|
|
+
|
|
|
+ HADOOP-2070. Added a flush method to pipes' DownwardProtocol and call
|
|
|
+ that before waiting for the application to finish to ensure all buffered
|
|
|
+ data is flushed. (Owen O'Malley via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2080. Fixed calculation of the checksum file size when the values
|
|
|
+ are large. (omalley)
|
|
|
+
|
|
|
+ HADOOP-2048. Change error handling in distcp so that each map copies
|
|
|
+ as much as possible before reporting the error. Also report progress on
|
|
|
+ every copy. (Chris Douglas via omalley)
|
|
|
+
|
|
|
+ HADOOP-2073. Change size of VERSION file after writing contents to it.
|
|
|
+ (Konstantin Shvachko via dhruba)
|
|
|
+
|
|
|
+ HADOOP-2102. Fix the deprecated ToolBase to pass its Configuration object
|
|
|
+ to the superceding ToolRunner to ensure it picks up the appropriate
|
|
|
+ configuration resources. (Dennis Kubes and Enis Soztutar via acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2103. Fix minor javadoc bugs introduce by HADOOP-2046. (Nigel
|
|
|
+ Daley via acmurthy)
|
|
|
+
|
|
|
+ IMPROVEMENTS
|
|
|
+
|
|
|
+ HADOOP-1908. Restructure data node code so that block sending and
|
|
|
+ receiving are seperated from data transfer header handling.
|
|
|
+ (Hairong Kuang via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1921. Save the configuration of completed/failed jobs and make them
|
|
|
+ available via the web-ui. (Amar Kamat via devaraj)
|
|
|
+
|
|
|
+ HADOOP-1266. Remove dependency of package org.apache.hadoop.net on
|
|
|
+ org.apache.hadoop.dfs. (Hairong Kuang via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1779. Replace INodeDirectory.getINode() by a getExistingPathINodes()
|
|
|
+ to allow the retrieval of all existing INodes along a given path in a
|
|
|
+ single lookup. This facilitates removal of the 'parent' field in the
|
|
|
+ inode. (Christophe Taton via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1756. Add toString() to some Writable-s. (ab)
|
|
|
+
|
|
|
+ HADOOP-1727. New classes: MapWritable and SortedMapWritable.
|
|
|
+ (Jim Kellerman via ab)
|
|
|
+
|
|
|
+ HADOOP-1651. Improve progress reporting.
|
|
|
+ (Devaraj Das via tomwhite)
|
|
|
+
|
|
|
+ HADOOP-1595. dfsshell can wait for a file to achieve its intended
|
|
|
+ replication target. (Tsz Wo (Nicholas), SZE via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1693. Remove un-needed log fields in DFS replication classes,
|
|
|
+ since the log may be accessed statically. (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+ HADOOP-1231. Add generics to Mapper and Reducer interfaces.
|
|
|
+ (tomwhite via cutting)
|
|
|
+
|
|
|
+ HADOOP-1436. Improved command-line APIs, so that all tools need
|
|
|
+ not subclass ToolBase, and generic parameter parser is public.
|
|
|
+ (Enis Soztutar via cutting)
|
|
|
+
|
|
|
+ HADOOP-1703. DFS-internal code cleanups, removing several uses of
|
|
|
+ the obsolete UTF8. (Christophe Taton via cutting)
|
|
|
+
|
|
|
+ HADOOP-1731. Add Hadoop's version to contrib jar file names.
|
|
|
+ (cutting)
|
|
|
+
|
|
|
+ HADOOP-1689. Make shell scripts more portable. All shell scripts
|
|
|
+ now explicitly depend on bash, but do not require that bash be
|
|
|
+ installed in a particular location, as long as it is on $PATH.
|
|
|
+ (cutting)
|
|
|
+
|
|
|
+ HADOOP-1744. Remove many uses of the deprecated UTF8 class from
|
|
|
+ the HDFS namenode. (Christophe Taton via cutting)
|
|
|
+
|
|
|
+ HADOOP-1654. Add IOUtils class, containing generic io-related
|
|
|
+ utility methods. (Enis Soztutar via cutting)
|
|
|
+
|
|
|
+ HADOOP-1158. Change JobTracker to record map-output transmission
|
|
|
+ errors and use them to trigger speculative re-execution of tasks.
|
|
|
+ (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+ HADOOP-1601. Change GenericWritable to use ReflectionUtils for
|
|
|
+ instance creation, avoiding classloader issues, and to implement
|
|
|
+ Configurable. (Enis Soztutar via cutting)
|
|
|
+
|
|
|
+ HADOOP-1750. Log standard output and standard error when forking
|
|
|
+ task processes. (omalley via cutting)
|
|
|
+
|
|
|
+ HADOOP-1803. Generalize build.xml to make files in all
|
|
|
+ src/contrib/*/bin directories executable. (stack via cutting)
|
|
|
+
|
|
|
+ HADOOP-1739. Let OS always choose the tasktracker's umbilical
|
|
|
+ port. Also switch default address for umbilical connections to
|
|
|
+ loopback. (cutting)
|
|
|
+
|
|
|
+ HADOOP-1812. Let OS choose ports for IPC and RPC unit tests. (cutting)
|
|
|
+
|
|
|
+ HADOOP-1825. Create $HADOOP_PID_DIR when it does not exist.
|
|
|
+ (Michael Bieniosek via cutting)
|
|
|
+
|
|
|
+ HADOOP-1425. Replace uses of ToolBase with the Tool interface.
|
|
|
+ (Enis Soztutar via cutting)
|
|
|
+
|
|
|
+ HADOOP-1569. Reimplement DistCP to use the standard FileSystem/URI
|
|
|
+ code in Hadoop so that you can copy from and to all of the supported file
|
|
|
+ systems.(Chris Douglas via omalley)
|
|
|
+
|
|
|
+ HADOOP-1018. Improve documentation w.r.t handling of lost hearbeats between
|
|
|
+ TaskTrackers and JobTracker. (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-1718. Add ant targets for measuring code coverage with clover.
|
|
|
+ (simonwillnauer via nigel)
|
|
|
+
|
|
|
+ HADOOP-1592. Log error messages to the client console when tasks
|
|
|
+ fail. (Amar Kamat via cutting)
|
|
|
+
|
|
|
+ HADOOP-1879. Remove some unneeded casts. (Nilay Vaish via cutting)
|
|
|
+
|
|
|
+ HADOOP-1878. Add space between priority links on job details
|
|
|
+ page. (Thomas Friol via cutting)
|
|
|
+
|
|
|
+ HADOOP-120. In ArrayWritable, prevent creation with null value
|
|
|
+ class, and improve documentation. (Cameron Pope via cutting)
|
|
|
+
|
|
|
+ HADOOP-1926. Add a random text writer example/benchmark so that we can
|
|
|
+ benchmark compression codecs on random data. (acmurthy via omalley)
|
|
|
+
|
|
|
+ HADOOP-1906. Warn the user if they have an obsolete madred-default.xml
|
|
|
+ file in their configuration directory. (acmurthy via omalley)
|
|
|
+
|
|
|
+ HADOOP-1971. Warn when job does not specify a jar. (enis via cutting)
|
|
|
+
|
|
|
+ HADOOP-1942. Increase the concurrency of transaction logging to
|
|
|
+ edits log. Reduce the number of syncs by double-buffering the changes
|
|
|
+ to the transaction log. (Dhruba Borthakur)
|
|
|
+
|
|
|
+ HADOOP-2046. Improve mapred javadoc. (Arun C. Murthy via cutting)
|
|
|
+
|
|
|
+ HADOOP-2105. Improve overview.html to clarify supported platforms,
|
|
|
+ software pre-requisites for hadoop, how to install them on various
|
|
|
+ platforms and a better general description of hadoop and it's utility.
|
|
|
+ (Jim Kellerman via acmurthy)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.14.4 - 2007-11-26
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-2140. Add missing Apache Licensing text at the front of several
|
|
|
+ C and C++ files.
|
|
|
+
|
|
|
+ HADOOP-2169. Fix the DT_SONAME field of libhdfs.so to set it to the
|
|
|
+ correct value of 'libhdfs.so', currently it is set to the absolute path of
|
|
|
+ libhdfs.so. (acmurthy)
|
|
|
+
|
|
|
+ HADOOP-2001. Make the job priority updates and job kills synchronized on
|
|
|
+ the JobTracker. Deadlock was seen in the JobTracker because of the lack of
|
|
|
+ this synchronization. (Arun C Murthy via ddas)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.14.3 - 2007-10-19
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-2053. Fixed a dangling reference to a memory buffer in the map
|
|
|
+ output sorter. (acmurthy via omalley)
|
|
|
+
|
|
|
+ HADOOP-2036. Fix a NullPointerException in JvmMetrics class. (nigel)
|
|
|
+
|
|
|
+ HADOOP-2043. Release 0.14.2 was compiled with Java 1.6 rather than
|
|
|
+ Java 1.5. (cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.14.2 - 2007-10-09
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-1948. Removed spurious error message during block crc upgrade.
|
|
|
+ (Raghu Angadi via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1862. reduces are getting stuck trying to find map outputs.
|
|
|
+ (Arun C. Murthy via ddas)
|
|
|
+
|
|
|
+ HADOOP-1977. Fixed handling of ToolBase cli options in JobClient.
|
|
|
+ (enis via omalley)
|
|
|
+
|
|
|
+ HADOOP-1972. Fix LzoCompressor to ensure the user has actually asked
|
|
|
+ to finish compression. (arun via omalley)
|
|
|
+
|
|
|
+ HADOOP-1970. Fix deadlock in progress reporting in the task. (Vivek
|
|
|
+ Ratan via omalley)
|
|
|
+
|
|
|
+ HADOOP-1978. Name-node removes edits.new after a successful startup.
|
|
|
+ (Konstantin Shvachko via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1955. The Namenode tries to not pick the same source Datanode for
|
|
|
+ a replication request if the earlier replication request for the same
|
|
|
+ block and that source Datanode had failed.
|
|
|
+ (Raghu Angadi via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1961. The -get option to dfs-shell works when a single filename
|
|
|
+ is specified. (Raghu Angadi via dhruba)
|
|
|
+
|
|
|
+ HADOOP-1997. TestCheckpoint closes the edits file after writing to it,
|
|
|
+ otherwise the rename of this file on Windows fails.
|
|
|
+ (Konstantin Shvachko via dhruba)
|
|
|
+
|
|
|
+Release 0.14.1 - 2007-09-04
|
|
|
+
|
|
|
+ BUG FIXES
|
|
|
+
|
|
|
+ HADOOP-1740. Fix null pointer exception in sorting map outputs. (Devaraj
|
|
|
+ Das via omalley)
|
|
|
+
|
|
|
+ HADOOP-1790. Fix tasktracker to work correctly on multi-homed
|
|
|
+ boxes. (Torsten Curdt via cutting)
|
|
|
+
|
|
|
+ HADOOP-1798. Fix jobtracker to correctly account for failed
|
|
|
+ tasks. (omalley via cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.14.0 - 2007-08-17
|
|
|
+
|
|
|
+ INCOMPATIBLE CHANGES
|
|
|
+
|
|
|
+ 1. HADOOP-1134.
|
|
|
+ CONFIG/API - dfs.block.size must now be a multiple of
|
|
|
+ io.byte.per.checksum, otherwise new files can not be written.
|
|
|
+ LAYOUT - DFS layout version changed from -6 to -7, which will require an
|
|
|
+ upgrade from previous versions.
|
|
|
+ PROTOCOL - Datanode RPC protocol version changed from 7 to 8.
|
|
|
+
|
|
|
+ 2. HADOOP-1283
|
|
|
+ API - deprecated file locking API.
|
|
|
+
|
|
|
+ 3. HADOOP-894
|
|
|
+ PROTOCOL - changed ClientProtocol to fetch parts of block locations.
|
|
|
+
|
|
|
+ 4. HADOOP-1336
|
|
|
+ CONFIG - Enable speculative execution by default.
|
|
|
+
|
|
|
+ 5. HADOOP-1197
|
|
|
+ API - deprecated method for Configuration.getObject, because
|
|
|
+ Configurations should only contain strings.
|
|
|
+
|
|
|
+ 6. HADOOP-1343
|
|
|
+ API - deprecate Configuration.set(String,Object) so that only strings are
|
|
|
+ put in Configrations.
|
|
|
+
|
|
|
+ 7. HADOOP-1207
|
|
|
+ CLI - Fix FsShell 'rm' command to continue when a non-existent file is
|
|
|
+ encountered.
|
|
|
+
|
|
|
+ 8. HADOOP-1473
|
|
|
+ CLI/API - Job, TIP, and Task id formats have changed and are now unique
|
|
|
+ across job tracker restarts.
|
|
|
+
|
|
|
+ 9. HADOOP-1400
|
|
|
+ API - JobClient constructor now takes a JobConf object instead of a
|
|
|
+ Configuration object.
|
|
|
+
|
|
|
+ NEW FEATURES and BUG FIXES
|
|
|
+
|
|
|
+ 1. HADOOP-1197. In Configuration, deprecate getObject() and add
|
|
|
+ getRaw(), which skips variable expansion. (omalley via cutting)
|
|
|
+
|
|
|
+ 2. HADOOP-1343. In Configuration, deprecate set(String,Object) and
|
|
|
+ implement Iterable. (omalley via cutting)
|
|
|
+
|
|
|
+ 3. HADOOP-1344. Add RunningJob#getJobName(). (Michael Bieniosek via cutting)
|
|
|
+
|
|
|
+ 4. HADOOP-1342. In aggregators, permit one to limit the number of
|
|
|
+ unique values per key. (Runping Qi via cutting)
|
|
|
+
|
|
|
+ 5. HADOOP-1340. Set the replication factor of the MD5 file in the filecache
|
|
|
+ to be the same as the replication factor of the original file.
|
|
|
+ (Dhruba Borthakur via tomwhite.)
|
|
|
+
|
|
|
+ 6. HADOOP-1355. Fix null pointer dereference in
|
|
|
+ TaskLogAppender.append(LoggingEvent). (Arun C Murthy via tomwhite.)
|
|
|
+
|
|
|
+ 7. HADOOP-1357. Fix CopyFiles to correctly avoid removing "/".
|
|
|
+ (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+ 8. HADOOP-234. Add pipes facility, which permits writing MapReduce
|
|
|
+ programs in C++.
|
|
|
+
|
|
|
+ 9. HADOOP-1359. Fix a potential NullPointerException in HDFS.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+ 10. HADOOP-1364. Fix inconsistent synchronization in SequenceFile.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+ 11. HADOOP-1379. Add findbugs target to build.xml.
|
|
|
+ (Nigel Daley via cutting)
|
|
|
+
|
|
|
+ 12. HADOOP-1364. Fix various inconsistent synchronization issues.
|
|
|
+ (Devaraj Das via cutting)
|
|
|
+
|
|
|
+ 13. HADOOP-1393. Remove a potential unexpected negative number from
|
|
|
+ uses of random number generator. (omalley via cutting)
|
|
|
+
|
|
|
+ 14. HADOOP-1387. A number of "performance" code-cleanups suggested
|
|
|
+ by findbugs. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+ 15. HADOOP-1401. Add contrib/hbase javadoc to tree. (stack via cutting)
|
|
|
+
|
|
|
+ 16. HADOOP-894. Change HDFS so that the client only retrieves a limited
|
|
|
+ number of block locations per request from the namenode.
|
|
|
+ (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+ 17. HADOOP-1406. Plug a leak in MapReduce's use of metrics.
|
|
|
+ (David Bowen via cutting)
|
|
|
+
|
|
|
+ 18. HADOOP-1394. Implement "performance" code-cleanups in HDFS
|
|
|
+ suggested by findbugs. (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+ 19. HADOOP-1413. Add example program that uses Knuth's dancing links
|
|
|
+ algorithm to solve pentomino problems. (omalley via cutting)
|
|
|
+
|
|
|
+ 20. HADOOP-1226. Change HDFS so that paths it returns are always
|
|
|
+ fully qualified. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+ 21. HADOOP-800. Improvements to HDFS web-based file browser.
|
|
|
+ (Enis Soztutar via cutting)
|
|
|
+
|
|
|
+ 22. HADOOP-1408. Fix a compiler warning by adding a class to replace
|
|
|
+ a generic. (omalley via cutting)
|
|
|
+
|
|
|
+ 23. HADOOP-1376. Modify RandomWriter example so that it can generate
|
|
|
+ data for the Terasort benchmark. (Devaraj Das via cutting)
|
|
|
+
|
|
|
+ 24. HADOOP-1429. Stop logging exceptions during normal IPC server
|
|
|
+ shutdown. (stack via cutting)
|
|
|
+
|
|
|
+ 25. HADOOP-1461. Fix the synchronization of the task tracker to
|
|
|
+ avoid lockups in job cleanup. (Arun C Murthy via omalley)
|
|
|
+
|
|
|
+ 26. HADOOP-1446. Update the TaskTracker metrics while the task is
|
|
|
+ running. (Devaraj via omalley)
|
|
|
+
|
|
|
+ 27. HADOOP-1414. Fix a number of issues identified by FindBugs as
|
|
|
+ "Bad Practice". (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+ 28. HADOOP-1392. Fix "correctness" bugs identified by FindBugs in
|
|
|
+ fs and dfs packages. (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+ 29. HADOOP-1412. Fix "dodgy" bugs identified by FindBugs in fs and
|
|
|
+ io packages. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+ 30. HADOOP-1261. Remove redundant events from HDFS namenode's edit
|
|
|
+ log when a datanode restarts. (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+ 31. HADOOP-1336. Re-enable speculative execution by
|
|
|
+ default. (omalley via cutting)
|
|
|
+
|
|
|
+ 32. HADOOP-1311. Fix a bug in BytesWritable#set() where start offset
|
|
|
+ was ignored. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+ 33. HADOOP-1450. Move checksumming closer to user code, so that
|
|
|
+ checksums are created before data is stored in large buffers and
|
|
|
+ verified after data is read from large buffers, to better catch
|
|
|
+ memory errors. (cutting)
|
|
|
+
|
|
|
+ 34. HADOOP-1447. Add support in contrib/data_join for text inputs.
|
|
|
+ (Senthil Subramanian via cutting)
|
|
|
+
|
|
|
+ 35. HADOOP-1456. Fix TestDecommission assertion failure by setting
|
|
|
+ the namenode to ignore the load on datanodes while allocating
|
|
|
+ replicas. (Dhruba Borthakur via tomwhite)
|
|
|
+
|
|
|
+ 36. HADOOP-1396. Fix FileNotFoundException on DFS block.
|
|
|
+ (Dhruba Borthakur via tomwhite)
|
|
|
+
|
|
|
+ 37. HADOOP-1467. Remove redundant counters from WordCount example.
|
|
|
+ (Owen O'Malley via tomwhite)
|
|
|
+
|
|
|
+ 38. HADOOP-1139. Log HDFS block transitions at INFO level, to better
|
|
|
+ enable diagnosis of problems. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+ 39. HADOOP-1269. Finer grained locking in HDFS namenode.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+ 40. HADOOP-1438. Improve HDFS documentation, correcting typos and
|
|
|
+ making images appear in PDF. Also update copyright date for all
|
|
|
+ docs. (Luke Nezda via cutting)
|
|
|
+
|
|
|
+ 41. HADOOP-1457. Add counters for monitoring task assignments.
|
|
|
+ (Arun C Murthy via tomwhite)
|
|
|
+
|
|
|
+ 42. HADOOP-1472. Fix so that timed-out tasks are counted as failures
|
|
|
+ rather than as killed. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+ 43. HADOOP-1234. Fix a race condition in file cache that caused
|
|
|
+ tasktracker to not be able to find cached files.
|
|
|
+ (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+ 44. HADOOP-1482. Fix secondary namenode to roll info port.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+ 45. HADOOP-1300. Improve removal of excess block replicas to be
|
|
|
+ rack-aware. Attempts are now made to keep replicas on more
|
|
|
+ racks. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+ 46. HADOOP-1417. Disable a few FindBugs checks that generate a lot
|
|
|
+ of spurious warnings. (Nigel Daley via cutting)
|
|
|
+
|
|
|
+ 47. HADOOP-1320. Rewrite RandomWriter example to bypass reduce.
|
|
|
+ (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+ 48. HADOOP-1449. Add some examples to contrib/data_join.
|
|
|
+ (Senthil Subramanian via cutting)
|
|
|
+
|
|
|
+ 49. HADOOP-1459. Fix so that, in HDFS, getFileCacheHints() returns
|
|
|
+ hostnames instead of IP addresses. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+ 50. HADOOP-1493. Permit specification of "java.library.path" system
|
|
|
+ property in "mapred.child.java.opts" configuration property.
|
|
|
+ (Enis Soztutar via cutting)
|
|
|
+
|
|
|
+ 51. HADOOP-1372. Use LocalDirAllocator for HDFS temporary block
|
|
|
+ files, so that disk space, writability, etc. is considered.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+ 52. HADOOP-1193. Pool allocation of compression codecs. This
|
|
|
+ eliminates a memory leak that could cause OutOfMemoryException,
|
|
|
+ and also substantially improves performance.
|
|
|
+ (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+ 53. HADOOP-1492. Fix a NullPointerException handling version
|
|
|
+ mismatch during datanode registration.
|
|
|
+ (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+ 54. HADOOP-1442. Fix handling of zero-length input splits.
|
|
|
+ (Senthil Subramanian via cutting)
|
|
|
+
|
|
|
+ 55. HADOOP-1444. Fix HDFS block id generation to check pending
|
|
|
+ blocks for duplicates. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+ 56. HADOOP-1207. Fix FsShell's 'rm' command to not stop when one of
|
|
|
+ the named files does not exist. (Tsz Wo Sze via cutting)
|
|
|
+
|
|
|
+ 57. HADOOP-1475. Clear tasktracker's file cache before it
|
|
|
+ re-initializes, to avoid confusion. (omalley via cutting)
|
|
|
+
|
|
|
+ 58. HADOOP-1505. Remove spurious stacktrace in ZlibFactory
|
|
|
+ introduced in HADOOP-1093. (Michael Stack via tomwhite)
|
|
|
+
|
|
|
+ 59. HADOOP-1484. Permit one to kill jobs from the web ui. Note that
|
|
|
+ this is disabled by default. One must set
|
|
|
+ "webinterface.private.actions" to enable this.
|
|
|
+ (Enis Soztutar via cutting)
|
|
|
+
|
|
|
+ 60. HADOOP-1003. Remove flushing of namenode edit log from primary
|
|
|
+ namenode lock, increasing namenode throughput.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+ 61. HADOOP-1023. Add links to searchable mail archives.
|
|
|
+ (tomwhite via cutting)
|
|
|
+
|
|
|
+ 62. HADOOP-1504. Fix terminate-hadoop-cluster script in contrib/ec2
|
|
|
+ to only terminate Hadoop instances, and not other instances
|
|
|
+ started by the same user. (tomwhite via cutting)
|
|
|
+
|
|
|
+ 63. HADOOP-1462. Improve task progress reporting. Progress reports
|
|
|
+ are no longer blocking since i/o is performed in a separate
|
|
|
+ thread. Reporting during sorting and more is also more
|
|
|
+ consistent. (Vivek Ratan via cutting)
|
|
|
+
|
|
|
+ 64. [ intentionally blank ]
|
|
|
+
|
|
|
+ 65. HADOOP-1453. Remove some unneeded calls to FileSystem#exists()
|
|
|
+ when opening files, reducing the namenode load somewhat.
|
|
|
+ (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+ 66. HADOOP-1489. Fix text input truncation bug due to mark/reset.
|
|
|
+ Add a unittest. (Bwolen Yang via cutting)
|
|
|
+
|
|
|
+ 67. HADOOP-1455. Permit specification of arbitrary job options on
|
|
|
+ pipes command line. (Devaraj Das via cutting)
|
|
|
+
|
|
|
+ 68. HADOOP-1501. Better randomize sending of block reports to
|
|
|
+ namenode, so reduce load spikes. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+ 69. HADOOP-1147. Remove @author tags from Java source files.
|
|
|
+
|
|
|
+ 70. HADOOP-1283. Convert most uses of UTF8 in the namenode to be
|
|
|
+ String. (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+ 71. HADOOP-1511. Speedup hbase unit tests. (stack via cutting)
|
|
|
+
|
|
|
+ 72. HADOOP-1517. Remove some synchronization in namenode to permit
|
|
|
+ finer grained locking previously added. (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+ 73. HADOOP-1512. Fix failing TestTextInputFormat on Windows.
|
|
|
+ (Senthil Subramanian via nigel)
|
|
|
+
|
|
|
+ 74. HADOOP-1518. Add a session id to job metrics, for use by HOD.
|
|
|
+ (David Bowen via cutting)
|
|
|
+
|
|
|
+ 75. HADOOP-1292. Change 'bin/hadoop fs -get' to first copy files to
|
|
|
+ a temporary name, then rename them to their final name, so that
|
|
|
+ failures don't leave partial files. (Tsz Wo Sze via cutting)
|
|
|
+
|
|
|
+ 76. HADOOP-1377. Add support for modification time to FileSystem and
|
|
|
+ implement in HDFS and local implementations. Also, alter access
|
|
|
+ to file properties to be through a new FileStatus interface.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+ 77. HADOOP-1515. Add MultiFileInputFormat, which can pack multiple,
|
|
|
+ typically small, input files into each split. (Enis Soztutar via cutting)
|
|
|
+
|
|
|
+ 78. HADOOP-1514. Make reducers report progress while waiting for map
|
|
|
+ outputs, so they're not killed. (Vivek Ratan via cutting)
|
|
|
+
|
|
|
+ 79. HADOOP-1508. Add an Ant task for FsShell operations. Also add
|
|
|
+ new FsShell commands "touchz", "test" and "stat".
|
|
|
+ (Chris Douglas via cutting)
|
|
|
+
|
|
|
+ 80. HADOOP-1028. Add log messages for server startup and shutdown.
|
|
|
+ (Tsz Wo Sze via cutting)
|
|
|
+
|
|
|
+ 81. HADOOP-1485. Add metrics for monitoring shuffle.
|
|
|
+ (Devaraj Das via cutting)
|
|
|
+
|
|
|
+ 82. HADOOP-1536. Remove file locks from libhdfs tests.
|
|
|
+ (Dhruba Borthakur via nigel)
|
|
|
+
|
|
|
+ 83. HADOOP-1520. Add appropriate synchronization to FSEditsLog.
|
|
|
+ (Dhruba Borthakur via nigel)
|
|
|
+
|
|
|
+ 84. HADOOP-1513. Fix a race condition in directory creation.
|
|
|
+ (Devaraj via omalley)
|
|
|
+
|
|
|
+ 85. HADOOP-1546. Remove spurious column from HDFS web UI.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+ 86. HADOOP-1556. Make LocalJobRunner delete working files at end of
|
|
|
+ job run. (Devaraj Das via tomwhite)
|
|
|
+
|
|
|
+ 87. HADOOP-1571. Add contrib lib directories to root build.xml
|
|
|
+ javadoc classpath. (Michael Stack via tomwhite)
|
|
|
+
|
|
|
+ 88. HADOOP-1554. Log killed tasks to the job history and display them on the
|
|
|
+ web/ui. (Devaraj Das via omalley)
|
|
|
+
|
|
|
+ 89. HADOOP-1533. Add persistent error logging for distcp. The logs are stored
|
|
|
+ into a specified hdfs directory. (Senthil Subramanian via omalley)
|
|
|
+
|
|
|
+ 90. HADOOP-1286. Add support to HDFS for distributed upgrades, which
|
|
|
+ permits coordinated upgrade of datanode data.
|
|
|
+ (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+ 91. HADOOP-1580. Improve contrib/streaming so that subprocess exit
|
|
|
+ status is displayed for errors. (John Heidemann via cutting)
|
|
|
+
|
|
|
+ 92. HADOOP-1448. In HDFS, randomize lists of non-local block
|
|
|
+ locations returned to client, so that load is better balanced.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+ 93. HADOOP-1578. Fix datanode to send its storage id to namenode
|
|
|
+ during registration. (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+ 94. HADOOP-1584. Fix a bug in GenericWritable which limited it to
|
|
|
+ 128 types instead of 256. (Espen Amble Kolstad via cutting)
|
|
|
+
|
|
|
+ 95. HADOOP-1473. Make job ids unique across jobtracker restarts.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+ 96. HADOOP-1582. Fix hdfslib to return 0 instead of -1 at
|
|
|
+ end-of-file, per C conventions. (Christian Kunz via cutting)
|
|
|
+
|
|
|
+ 97. HADOOP-911. Fix a multithreading bug in libhdfs.
|
|
|
+ (Christian Kunz)
|
|
|
+
|
|
|
+ 98. HADOOP-1486. Fix so that fatal exceptions in namenode cause it
|
|
|
+ to exit. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+ 99. HADOOP-1470. Factor checksum generation and validation out of
|
|
|
+ ChecksumFileSystem so that it can be reused by FileSystem's with
|
|
|
+ built-in checksumming. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+100. HADOOP-1590. Use relative urls in jobtracker jsp pages, so that
|
|
|
+ webapp can be used in non-root contexts. (Thomas Friol via cutting)
|
|
|
+
|
|
|
+101. HADOOP-1596. Fix the parsing of taskids by streaming and improve the
|
|
|
+ error reporting. (omalley)
|
|
|
+
|
|
|
+102. HADOOP-1535. Fix the user-controlled grouping to the reduce function.
|
|
|
+ (Vivek Ratan via omalley)
|
|
|
+
|
|
|
+103. HADOOP-1585. Modify GenericWritable to declare the classes as subtypes
|
|
|
+ of Writable (Espen Amble Kolstad via omalley)
|
|
|
+
|
|
|
+104. HADOOP-1576. Fix errors in count of completed tasks when
|
|
|
+ speculative execution is enabled. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+105. HADOOP-1598. Fix license headers: adding missing; updating old.
|
|
|
+ (Enis Soztutar via cutting)
|
|
|
+
|
|
|
+106. HADOOP-1547. Provide examples for aggregate library.
|
|
|
+ (Runping Qi via tomwhite)
|
|
|
+
|
|
|
+107. HADOOP-1570. Permit jobs to enable and disable the use of
|
|
|
+ hadoop's native library. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+108. HADOOP-1433. Add job priority. (Johan Oskarsson via tomwhite)
|
|
|
+
|
|
|
+109. HADOOP-1597. Add status reports and post-upgrade options to HDFS
|
|
|
+ distributed upgrade. (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+110. HADOOP-1524. Permit user task logs to appear as they're
|
|
|
+ created. (Michael Bieniosek via cutting)
|
|
|
+
|
|
|
+111. HADOOP-1599. Fix distcp bug on Windows. (Senthil Subramanian via cutting)
|
|
|
+
|
|
|
+112. HADOOP-1562. Add JVM metrics, including GC and logging stats.
|
|
|
+ (David Bowen via cutting)
|
|
|
+
|
|
|
+113. HADOOP-1613. Fix "DFS Health" page to display correct time of
|
|
|
+ last contact. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+114. HADOOP-1134. Add optimized checksum support to HDFS. Checksums
|
|
|
+ are now stored with each block, rather than as parallel files.
|
|
|
+ This reduces the namenode's memory requirements and increases
|
|
|
+ data integrity. (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+115. HADOOP-1400. Make JobClient retry requests, so that clients can
|
|
|
+ survive jobtracker problems. (omalley via cutting)
|
|
|
+
|
|
|
+116. HADOOP-1564. Add unit tests for HDFS block-level checksums.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+117. HADOOP-1620. Reduce the number of abstract FileSystem methods,
|
|
|
+ simplifying implementations. (cutting)
|
|
|
+
|
|
|
+118. HADOOP-1625. Fix a "could not move files" exception in datanode.
|
|
|
+ (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+119. HADOOP-1624. Fix an infinite loop in datanode. (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+120. HADOOP-1084. Switch mapred file cache to use file modification
|
|
|
+ time instead of checksum to detect file changes, as checksums are
|
|
|
+ no longer easily accessed. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+130. HADOOP-1623. Fix an infinite loop when copying directories.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+131. HADOOP-1603. Fix a bug in namenode initialization where
|
|
|
+ default replication is sometimes reset to one on restart.
|
|
|
+ (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+132. HADOOP-1635. Remove hardcoded keypair name and fix launch-hadoop-cluster
|
|
|
+ to support later versions of ec2-api-tools. (Stu Hood via tomwhite)
|
|
|
+
|
|
|
+133. HADOOP-1638. Fix contrib EC2 scripts to support NAT addressing.
|
|
|
+ (Stu Hood via tomwhite)
|
|
|
+
|
|
|
+134. HADOOP-1632. Fix an IllegalArgumentException in fsck.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+135. HADOOP-1619. Fix FSInputChecker to not attempt to read past EOF.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+136. HADOOP-1640. Fix TestDecommission on Windows.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+137. HADOOP-1587. Fix TestSymLink to get required system properties.
|
|
|
+ (Devaraj Das via omalley)
|
|
|
+
|
|
|
+138. HADOOP-1628. Add block CRC protocol unit tests. (Raghu Angadi via omalley)
|
|
|
+
|
|
|
+139. HADOOP-1653. FSDirectory code-cleanups. FSDirectory.INode
|
|
|
+ becomes a static class. (Christophe Taton via dhruba)
|
|
|
+
|
|
|
+140. HADOOP-1066. Restructure documentation to make more user
|
|
|
+ friendly. (Connie Kleinjans and Jeff Hammerbacher via cutting)
|
|
|
+
|
|
|
+141. HADOOP-1551. libhdfs supports setting replication factor and
|
|
|
+ retrieving modification time of files. (Sameer Paranjpye via dhruba)
|
|
|
+
|
|
|
+141. HADOOP-1647. FileSystem.getFileStatus returns valid values for "/".
|
|
|
+ (Dhruba Borthakur via dhruba)
|
|
|
+
|
|
|
+142. HADOOP-1657. Fix NNBench to ensure that the block size is a
|
|
|
+ multiple of bytes.per.checksum. (Raghu Angadi via dhruba)
|
|
|
+
|
|
|
+143. HADOOP-1553. Replace user task output and log capture code to use shell
|
|
|
+ redirection instead of copier threads in the TaskTracker. Capping the
|
|
|
+ size of the output is now done via tail in memory and thus should not be
|
|
|
+ large. The output of the tasklog servlet is not forced into UTF8 and is
|
|
|
+ not buffered entirely in memory. (omalley)
|
|
|
+ Configuration changes to hadoop-default.xml:
|
|
|
+ remove mapred.userlog.num.splits
|
|
|
+ remove mapred.userlog.purge.splits
|
|
|
+ change default mapred.userlog.limit.kb to 0 (no limit)
|
|
|
+ change default mapred.userlog.retain.hours to 24
|
|
|
+ Configuration changes to log4j.properties:
|
|
|
+ remove log4j.appender.TLA.noKeepSplits
|
|
|
+ remove log4j.appender.TLA.purgeLogSplits
|
|
|
+ remove log4j.appender.TLA.logsRetainHours
|
|
|
+ URL changes:
|
|
|
+ http://<tasktracker>/tasklog.jsp -> http://<tasktracker>tasklog with
|
|
|
+ parameters limited to start and end, which may be positive (from
|
|
|
+ start) or negative (from end).
|
|
|
+ Environment:
|
|
|
+ require bash (v2 or later) and tail
|
|
|
+
|
|
|
+144. HADOOP-1659. Fix a job id/job name mixup. (Arun C. Murthy via omalley)
|
|
|
+
|
|
|
+145. HADOOP-1665. With HDFS Trash enabled and the same file was created
|
|
|
+ and deleted more than once, the suceeding deletions creates Trash item
|
|
|
+ names suffixed with a integer. (Dhruba Borthakur via dhruba)
|
|
|
+
|
|
|
+146. HADOOP-1666. FsShell object can be used for multiple fs commands.
|
|
|
+ (Dhruba Borthakur via dhruba)
|
|
|
+
|
|
|
+147. HADOOP-1654. Remove performance regression introduced by Block CRC.
|
|
|
+ (Raghu Angadi via dhruba)
|
|
|
+
|
|
|
+148. HADOOP-1680. Improvements to Block CRC upgrade messages.
|
|
|
+ (Raghu Angadi via dhruba)
|
|
|
+
|
|
|
+149. HADOOP-71. Allow Text and SequenceFile Map/Reduce inputs from non-default
|
|
|
+ filesystems. (omalley)
|
|
|
+
|
|
|
+150. HADOOP-1568. Expose HDFS as xml/http filesystem to provide cross-version
|
|
|
+ compatability. (Chris Douglas via omalley)
|
|
|
+
|
|
|
+151. HADOOP-1668. Added an INCOMPATIBILITY section to CHANGES.txt. (nigel)
|
|
|
+
|
|
|
+152. HADOOP-1629. Added a upgrade test for HADOOP-1134.
|
|
|
+ (Raghu Angadi via nigel)
|
|
|
+
|
|
|
+153. HADOOP-1698. Fix performance problems on map output sorting for jobs
|
|
|
+ with large numbers of reduces. (Devaraj Das via omalley)
|
|
|
+
|
|
|
+154. HADOOP-1716. Fix a Pipes wordcount example to remove the 'file:'
|
|
|
+ schema from its output path. (omalley via cutting)
|
|
|
+
|
|
|
+155. HADOOP-1714. Fix TestDFSUpgradeFromImage to work on Windows.
|
|
|
+ (Raghu Angadi via nigel)
|
|
|
+
|
|
|
+156. HADOOP-1663. Return a non-zero exit code if streaming fails. (Lohit Renu
|
|
|
+ via omalley)
|
|
|
+
|
|
|
+157. HADOOP-1712. Fix an unhandled exception on datanode during block
|
|
|
+ CRC upgrade. (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+158. HADOOP-1717. Fix TestDFSUpgradeFromImage to work on Solaris.
|
|
|
+ (nigel via cutting)
|
|
|
+
|
|
|
+159. HADOOP-1437. Add Eclipse plugin in contrib.
|
|
|
+ (Eugene Hung and Christophe Taton via cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.13.0 - 2007-06-08
|
|
|
+
|
|
|
+ 1. HADOOP-1047. Fix TestReplication to succeed more reliably.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+ 2. HADOOP-1063. Fix a race condition in MiniDFSCluster test code.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+ 3. HADOOP-1101. In web ui, split shuffle statistics from reduce
|
|
|
+ statistics, and add some task averages. (Devaraj Das via cutting)
|
|
|
+
|
|
|
+ 4. HADOOP-1071. Improve handling of protocol version mismatch in
|
|
|
+ JobTracker. (Tahir Hashmi via cutting)
|
|
|
+
|
|
|
+ 5. HADOOP-1116. Increase heap size used for contrib unit tests.
|
|
|
+ (Philippe Gassmann via cutting)
|
|
|
+
|
|
|
+ 6. HADOOP-1120. Add contrib/data_join, tools to simplify joining
|
|
|
+ data from multiple sources using MapReduce. (Runping Qi via cutting)
|
|
|
+
|
|
|
+ 7. HADOOP-1064. Reduce log level of some DFSClient messages.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+ 8. HADOOP-1137. Fix StatusHttpServer to work correctly when
|
|
|
+ resources are in a jar file. (Benjamin Reed via cutting)
|
|
|
+
|
|
|
+ 9. HADOOP-1094. Optimize generated Writable implementations for
|
|
|
+ records to not allocate a new BinaryOutputArchive or
|
|
|
+ BinaryInputArchive per call. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+10. HADOOP-1068. Improve error message for clusters with 0 datanodes.
|
|
|
+ (Dhruba Borthakur via tomwhite)
|
|
|
+
|
|
|
+11. HADOOP-1122. Fix divide-by-zero exception in FSNamesystem
|
|
|
+ chooseTarget method. (Dhruba Borthakur via tomwhite)
|
|
|
+
|
|
|
+12. HADOOP-1131. Add a closeAll() static method to FileSystem.
|
|
|
+ (Philippe Gassmann via tomwhite)
|
|
|
+
|
|
|
+13. HADOOP-1085. Improve port selection in HDFS and MapReduce test
|
|
|
+ code. Ports are now selected by the OS during testing rather than
|
|
|
+ by probing for free ports, improving test reliability.
|
|
|
+ (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+14. HADOOP-1153. Fix HDFS daemons to correctly stop their threads.
|
|
|
+ (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+15. HADOOP-1146. Add a counter for reduce input keys and rename the
|
|
|
+ "reduce input records" counter to be "reduce input groups".
|
|
|
+ (David Bowen via cutting)
|
|
|
+
|
|
|
+16. HADOOP-1165. In records, replace idential generated toString
|
|
|
+ methods with a method on the base class. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+17. HADOOP-1164. Fix TestReplicationPolicy to specify port zero, so
|
|
|
+ that a free port is automatically selected. (omalley via cutting)
|
|
|
+
|
|
|
+18. HADOOP-1166. Add a NullOutputFormat and use it in the
|
|
|
+ RandomWriter example. (omalley via cutting)
|
|
|
+
|
|
|
+19. HADOOP-1169. Fix a cut/paste error in CopyFiles utility so that
|
|
|
+ S3-based source files are correctly copied. (Michael Stack via cutting)
|
|
|
+
|
|
|
+20. HADOOP-1167. Remove extra synchronization in InMemoryFileSystem.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+21. HADOOP-1110. Fix an off-by-one error counting map inputs.
|
|
|
+ (David Bowen via cutting)
|
|
|
+
|
|
|
+22. HADOOP-1178. Fix a NullPointerException during namenode startup.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+23. HADOOP-1011. Fix a ConcurrentModificationException when viewing
|
|
|
+ job history. (Tahir Hashmi via cutting)
|
|
|
+
|
|
|
+24. HADOOP-672. Improve help for fs shell commands.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+25. HADOOP-1170. Improve datanode performance by removing device
|
|
|
+ checks from common operations. (Igor Bolotin via cutting)
|
|
|
+
|
|
|
+26. HADOOP-1090. Fix SortValidator's detection of whether the input
|
|
|
+ file belongs to the sort-input or sort-output directory.
|
|
|
+ (Arun C Murthy via tomwhite)
|
|
|
+
|
|
|
+27. HADOOP-1081. Fix bin/hadoop on Darwin. (Michael Bieniosek via cutting)
|
|
|
+
|
|
|
+28. HADOOP-1045. Add contrib/hbase, a BigTable-like online database.
|
|
|
+ (Jim Kellerman via cutting)
|
|
|
+
|
|
|
+29. HADOOP-1156. Fix a NullPointerException in MiniDFSCluster.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+30. HADOOP-702. Add tools to help automate HDFS upgrades.
|
|
|
+ (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+31. HADOOP-1163. Fix ganglia metrics to aggregate metrics from different
|
|
|
+ hosts properly. (Michael Bieniosek via tomwhite)
|
|
|
+
|
|
|
+32. HADOOP-1194. Make compression style record level for map output
|
|
|
+ compression. (Arun C Murthy via tomwhite)
|
|
|
+
|
|
|
+33. HADOOP-1187. Improve DFS Scalability: avoid scanning entire list of
|
|
|
+ datanodes in getAdditionalBlocks. (Dhruba Borthakur via tomwhite)
|
|
|
+
|
|
|
+34. HADOOP-1133. Add tool to analyze and debug namenode on a production
|
|
|
+ cluster. (Dhruba Borthakur via tomwhite)
|
|
|
+
|
|
|
+35. HADOOP-1151. Remove spurious printing to stderr in streaming
|
|
|
+ PipeMapRed. (Koji Noguchi via tomwhite)
|
|
|
+
|
|
|
+36. HADOOP-988. Change namenode to use a single map of blocks to metadata.
|
|
|
+ (Raghu Angadi via tomwhite)
|
|
|
+
|
|
|
+37. HADOOP-1203. Change UpgradeUtilities used by DFS tests to use
|
|
|
+ MiniDFSCluster to start and stop NameNode/DataNodes.
|
|
|
+ (Nigel Daley via tomwhite)
|
|
|
+
|
|
|
+38. HADOOP-1217. Add test.timeout property to build.xml, so that
|
|
|
+ long-running unit tests may be automatically terminated.
|
|
|
+ (Nigel Daley via cutting)
|
|
|
+
|
|
|
+39. HADOOP-1149. Improve DFS Scalability: make
|
|
|
+ processOverReplicatedBlock() a no-op if blocks are not
|
|
|
+ over-replicated. (Raghu Angadi via tomwhite)
|
|
|
+
|
|
|
+40. HADOOP-1149. Improve DFS Scalability: optimize getDistance(),
|
|
|
+ contains(), and isOnSameRack() in NetworkTopology.
|
|
|
+ (Hairong Kuang via tomwhite)
|
|
|
+
|
|
|
+41. HADOOP-1218. Make synchronization on TaskTracker's RunningJob
|
|
|
+ object consistent. (Devaraj Das via tomwhite)
|
|
|
+
|
|
|
+42. HADOOP-1219. Ignore progress report once a task has reported as
|
|
|
+ 'done'. (Devaraj Das via tomwhite)
|
|
|
+
|
|
|
+43. HADOOP-1114. Permit user to specify additional CLASSPATH elements
|
|
|
+ with a HADOOP_CLASSPATH environment variable. (cutting)
|
|
|
+
|
|
|
+44. HADOOP-1198. Remove ipc.client.timeout parameter override from
|
|
|
+ unit test configuration. Using the default is more robust and
|
|
|
+ has almost the same run time. (Arun C Murthy via tomwhite)
|
|
|
+
|
|
|
+45. HADOOP-1211. Remove deprecated constructor and unused static
|
|
|
+ members in DataNode class. (Konstantin Shvachko via tomwhite)
|
|
|
+
|
|
|
+46. HADOOP-1136. Fix ArrayIndexOutOfBoundsException in
|
|
|
+ FSNamesystem$UnderReplicatedBlocks add() method.
|
|
|
+ (Hairong Kuang via tomwhite)
|
|
|
+
|
|
|
+47. HADOOP-978. Add the client name and the address of the node that
|
|
|
+ previously started to create the file to the description of
|
|
|
+ AlreadyBeingCreatedException. (Konstantin Shvachko via tomwhite)
|
|
|
+
|
|
|
+48. HADOOP-1001. Check the type of keys and values generated by the
|
|
|
+ mapper against the types specified in JobConf.
|
|
|
+ (Tahir Hashmi via tomwhite)
|
|
|
+
|
|
|
+49. HADOOP-971. Improve DFS Scalability: Improve name node performance
|
|
|
+ by adding a hostname to datanodes map. (Hairong Kuang via tomwhite)
|
|
|
+
|
|
|
+50. HADOOP-1189. Fix 'No space left on device' exceptions on datanodes.
|
|
|
+ (Raghu Angadi via tomwhite)
|
|
|
+
|
|
|
+51. HADOOP-819. Change LineRecordWriter to not insert a tab between
|
|
|
+ key and value when either is null, and to print nothing when both
|
|
|
+ are null. (Runping Qi via cutting)
|
|
|
+
|
|
|
+52. HADOOP-1204. Rename InputFormatBase to be FileInputFormat, and
|
|
|
+ deprecate InputFormatBase. Also make LineRecordReader easier to
|
|
|
+ extend. (Runping Qi via cutting)
|
|
|
+
|
|
|
+53. HADOOP-1213. Improve logging of errors by IPC server, to
|
|
|
+ consistently include the service name and the call. (cutting)
|
|
|
+
|
|
|
+54. HADOOP-1238. Fix metrics reporting by TaskTracker to correctly
|
|
|
+ track maps_running and reduces_running.
|
|
|
+ (Michael Bieniosek via cutting)
|
|
|
+
|
|
|
+55. HADOOP-1093. Fix a race condition in HDFS where blocks were
|
|
|
+ sometimes erased before they were reported written.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+56. HADOOP-1239. Add a package name to some testjar test classes.
|
|
|
+ (Jim Kellerman via cutting)
|
|
|
+
|
|
|
+57. HADOOP-1241. Fix NullPointerException in processReport when
|
|
|
+ namenode is restarted. (Dhruba Borthakur via tomwhite)
|
|
|
+
|
|
|
+58. HADOOP-1244. Fix stop-dfs.sh to no longer incorrectly specify
|
|
|
+ slaves file for stopping datanode.
|
|
|
+ (Michael Bieniosek via tomwhite)
|
|
|
+
|
|
|
+59. HADOOP-1253. Fix ConcurrentModificationException and
|
|
|
+ NullPointerException in JobControl.
|
|
|
+ (Johan Oskarson via tomwhite)
|
|
|
+
|
|
|
+60. HADOOP-1256. Fix NameNode so that multiple DataNodeDescriptors
|
|
|
+ can no longer be created on startup. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+61. HADOOP-1214. Replace streaming classes with new counterparts
|
|
|
+ from Hadoop core. (Runping Qi via tomwhite)
|
|
|
+
|
|
|
+62. HADOOP-1250. Move a chmod utility from streaming to FileUtil.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+63. HADOOP-1258. Fix TestCheckpoint test case to wait for
|
|
|
+ MiniDFSCluster to be active. (Nigel Daley via tomwhite)
|
|
|
+
|
|
|
+64. HADOOP-1148. Re-indent all Java source code to consistently use
|
|
|
+ two spaces per indent level. (cutting)
|
|
|
+
|
|
|
+65. HADOOP-1251. Add a method to Reporter to get the map InputSplit.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+66. HADOOP-1224. Fix "Browse the filesystem" link to no longer point
|
|
|
+ to dead datanodes. (Enis Soztutar via tomwhite)
|
|
|
+
|
|
|
+67. HADOOP-1154. Fail a streaming task if the threads reading from or
|
|
|
+ writing to the streaming process fail. (Koji Noguchi via tomwhite)
|
|
|
+
|
|
|
+68. HADOOP-968. Move shuffle and sort to run in reduce's child JVM,
|
|
|
+ rather than in TaskTracker. (Devaraj Das via cutting)
|
|
|
+
|
|
|
+69. HADOOP-1111. Add support for client notification of job
|
|
|
+ completion. If the job configuration has a job.end.notification.url
|
|
|
+ property it will make a HTTP GET request to the specified URL.
|
|
|
+ The number of retries and the interval between retries is also
|
|
|
+ configurable. (Alejandro Abdelnur via tomwhite)
|
|
|
+
|
|
|
+70. HADOOP-1275. Fix misspelled job notification property in
|
|
|
+ hadoop-default.xml. (Alejandro Abdelnur via tomwhite)
|
|
|
+
|
|
|
+71. HADOOP-1152. Fix race condition in MapOutputCopier.copyOutput file
|
|
|
+ rename causing possible reduce task hang.
|
|
|
+ (Tahir Hashmi via tomwhite)
|
|
|
+
|
|
|
+72. HADOOP-1050. Distinguish between failed and killed tasks so as to
|
|
|
+ not count a lost tasktracker against the job.
|
|
|
+ (Arun C Murthy via tomwhite)
|
|
|
+
|
|
|
+73. HADOOP-1271. Fix StreamBaseRecordReader to be able to log record
|
|
|
+ data that's not UTF-8. (Arun C Murthy via tomwhite)
|
|
|
+
|
|
|
+74. HADOOP-1190. Fix unchecked warnings in main Hadoop code.
|
|
|
+ (tomwhite)
|
|
|
+
|
|
|
+75. HADOOP-1127. Fix AlreadyBeingCreatedException in namenode for
|
|
|
+ jobs run with speculative execution.
|
|
|
+ (Arun C Murthy via tomwhite)
|
|
|
+
|
|
|
+76. HADOOP-1282. Omnibus HBase patch. Improved tests & configuration.
|
|
|
+ (Jim Kellerman via cutting)
|
|
|
+
|
|
|
+77. HADOOP-1262. Make dfs client try to read from a different replica
|
|
|
+ of the checksum file when a checksum error is detected.
|
|
|
+ (Hairong Kuang via tomwhite)
|
|
|
+
|
|
|
+78. HADOOP-1279. Fix JobTracker to maintain list of recently
|
|
|
+ completed jobs by order of completion, not submission.
|
|
|
+ (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+79. HADOOP-1284. In contrib/streaming, permit flexible specification
|
|
|
+ of field delimiter and fields for partitioning and sorting.
|
|
|
+ (Runping Qi via cutting)
|
|
|
+
|
|
|
+80. HADOOP-1176. Fix a bug where reduce would hang when a map had
|
|
|
+ more than 2GB of output for it. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+81. HADOOP-1293. Fix contrib/streaming to print more than the first
|
|
|
+ twenty lines of standard error. (Koji Noguchi via cutting)
|
|
|
+
|
|
|
+82. HADOOP-1297. Fix datanode so that requests to remove blocks that
|
|
|
+ do not exist no longer causes block reports to be re-sent every
|
|
|
+ second. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+83. HADOOP-1216. Change MapReduce so that, when numReduceTasks is
|
|
|
+ zero, map outputs are written directly as final output, skipping
|
|
|
+ shuffle, sort and reduce. Use this to implement reduce=NONE
|
|
|
+ option in contrib/streaming. (Runping Qi via cutting)
|
|
|
+
|
|
|
+84. HADOOP-1294. Fix unchecked warnings in main Hadoop code under
|
|
|
+ Java 6. (tomwhite)
|
|
|
+
|
|
|
+85. HADOOP-1299. Fix so that RPC will restart after RPC.stopClient()
|
|
|
+ has been called. (Michael Stack via cutting)
|
|
|
+
|
|
|
+86. HADOOP-1278. Improve blacklisting of TaskTrackers by JobTracker,
|
|
|
+ to reduce false positives. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+87. HADOOP-1290. Move contrib/abacus into mapred/lib/aggregate.
|
|
|
+ (Runping Qi via cutting)
|
|
|
+
|
|
|
+88. HADOOP-1272. Extract inner classes from FSNamesystem into separate
|
|
|
+ classes. (Dhruba Borthakur via tomwhite)
|
|
|
+
|
|
|
+89. HADOOP-1247. Add support to contrib/streaming for aggregate
|
|
|
+ package, formerly called Abacus. (Runping Qi via cutting)
|
|
|
+
|
|
|
+90. HADOOP-1061. Fix bug in listing files in the S3 filesystem.
|
|
|
+ NOTE: this change is not backwards compatible! You should use the
|
|
|
+ MigrationTool supplied to migrate existing S3 filesystem data to
|
|
|
+ the new format. Please backup your data first before upgrading
|
|
|
+ (using 'hadoop distcp' for example). (tomwhite)
|
|
|
+
|
|
|
+91. HADOOP-1304. Make configurable the maximum number of task
|
|
|
+ attempts before a job fails. (Devaraj Das via cutting)
|
|
|
+
|
|
|
+92. HADOOP-1308. Use generics to restrict types when classes are
|
|
|
+ passed as parameters to JobConf methods. (Michael Bieniosek via cutting)
|
|
|
+
|
|
|
+93. HADOOP-1312. Fix a ConcurrentModificationException in NameNode
|
|
|
+ that killed the heartbeat monitoring thread.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+94. HADOOP-1315. Clean up contrib/streaming, switching it to use core
|
|
|
+ classes more and removing unused code. (Runping Qi via cutting)
|
|
|
+
|
|
|
+95. HADOOP-485. Allow a different comparator for grouping keys in
|
|
|
+ calls to reduce. (Tahir Hashmi via cutting)
|
|
|
+
|
|
|
+96. HADOOP-1322. Fix TaskTracker blacklisting to work correctly in
|
|
|
+ one- and two-node clusters. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+97. HADOOP-1144. Permit one to specify a maximum percentage of tasks
|
|
|
+ that can fail before a job is aborted. The default is zero.
|
|
|
+ (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+98. HADOOP-1184. Fix HDFS decomissioning to complete when the only
|
|
|
+ copy of a block is on a decommissioned node. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+99. HADOOP-1263. Change DFSClient to retry certain namenode calls
|
|
|
+ with a random, exponentially increasing backoff time, to avoid
|
|
|
+ overloading the namenode on, e.g., job start. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+100. HADOOP-1325. First complete, functioning version of HBase.
|
|
|
+ (Jim Kellerman via cutting)
|
|
|
+
|
|
|
+101. HADOOP-1276. Make tasktracker expiry interval configurable.
|
|
|
+ (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+102. HADOOP-1326. Change JobClient#RunJob() to return the job.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+103. HADOOP-1270. Randomize the fetch of map outputs, speeding the
|
|
|
+ shuffle. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+104. HADOOP-1200. Restore disk checking lost in HADOOP-1170.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+105. HADOOP-1252. Changed MapReduce's allocation of local files to
|
|
|
+ use round-robin among available devices, rather than a hashcode.
|
|
|
+ More care is also taken to not allocate files on full or offline
|
|
|
+ drives. (Devaraj Das via cutting)
|
|
|
+
|
|
|
+106. HADOOP-1324. Change so that an FSError kills only the task that
|
|
|
+ generates it rather than the entire task tracker.
|
|
|
+ (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+107. HADOOP-1310. Fix unchecked warnings in aggregate code. (tomwhite)
|
|
|
+
|
|
|
+108. HADOOP-1255. Fix a bug where the namenode falls into an infinite
|
|
|
+ loop trying to remove a dead node. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+109. HADOOP-1160. Fix DistributedFileSystem.close() to close the
|
|
|
+ underlying FileSystem, correctly aborting files being written.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+110. HADOOP-1341. Fix intermittent failures in HBase unit tests
|
|
|
+ caused by deadlock. (Jim Kellerman via cutting)
|
|
|
+
|
|
|
+111. HADOOP-1350. Fix shuffle performance problem caused by forcing
|
|
|
+ chunked encoding of map outputs. (Devaraj Das via cutting)
|
|
|
+
|
|
|
+112. HADOOP-1345. Fix HDFS to correctly retry another replica when a
|
|
|
+ checksum error is encountered. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+113. HADOOP-1205. Improve synchronization around HDFS block map.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+114. HADOOP-1353. Fix a potential NullPointerException in namenode.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+115. HADOOP-1354. Fix a potential NullPointerException in FsShell.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+116. HADOOP-1358. Fix a potential bug when DFSClient calls skipBytes.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+117. HADOOP-1356. Fix a bug in ValueHistogram. (Runping Qi via cutting)
|
|
|
+
|
|
|
+118. HADOOP-1363. Fix locking bug in JobClient#waitForCompletion().
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+119. HADOOP-1368. Fix inconsistent synchronization in JobInProgress.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+120. HADOOP-1369. Fix inconsistent synchronization in TaskTracker.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+121. HADOOP-1361. Fix various calls to skipBytes() to check return
|
|
|
+ value. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+122. HADOOP-1388. Fix a potential NullPointerException in web ui.
|
|
|
+ (Devaraj Das via cutting)
|
|
|
+
|
|
|
+123. HADOOP-1385. Fix MD5Hash#hashCode() to generally hash to more
|
|
|
+ than 256 values. (omalley via cutting)
|
|
|
+
|
|
|
+124. HADOOP-1386. Fix Path to not permit the empty string as a
|
|
|
+ path, as this has lead to accidental file deletion. Instead
|
|
|
+ force applications to use "." to name the default directory.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+125. HADOOP-1407. Fix integer division bug in JobInProgress which
|
|
|
+ meant failed tasks didn't cause the job to fail.
|
|
|
+ (Arun C Murthy via tomwhite)
|
|
|
+
|
|
|
+126. HADOOP-1427. Fix a typo that caused GzipCodec to incorrectly use
|
|
|
+ a very small input buffer. (Espen Amble Kolstad via cutting)
|
|
|
+
|
|
|
+127. HADOOP-1435. Fix globbing code to no longer use the empty string
|
|
|
+ to indicate the default directory, per HADOOP-1386.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+128. HADOOP-1411. Make task retry framework handle
|
|
|
+ AlreadyBeingCreatedException when wrapped as a RemoteException.
|
|
|
+ (Hairong Kuang via tomwhite)
|
|
|
+
|
|
|
+129. HADOOP-1242. Improve handling of DFS upgrades.
|
|
|
+ (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+130. HADOOP-1332. Fix so that TaskTracker exits reliably during unit
|
|
|
+ tests on Windows. (omalley via cutting)
|
|
|
+
|
|
|
+131. HADOOP-1431. Fix so that sort progress reporting during map runs
|
|
|
+ only while sorting, so that stuck maps are correctly terminated.
|
|
|
+ (Devaraj Das and Arun C Murthy via cutting)
|
|
|
+
|
|
|
+132. HADOOP-1452. Change TaskTracker.MapOutputServlet.doGet.totalRead
|
|
|
+ to a long, permitting map outputs to exceed 2^31 bytes.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+133. HADOOP-1443. Fix a bug opening zero-length files in HDFS.
|
|
|
+ (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.12.3 - 2007-04-06
|
|
|
+
|
|
|
+ 1. HADOOP-1162. Fix bug in record CSV and XML serialization of
|
|
|
+ binary values. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+ 2. HADOOP-1123. Fix NullPointerException in LocalFileSystem when
|
|
|
+ trying to recover from a checksum error.
|
|
|
+ (Hairong Kuang & Nigel Daley via tomwhite)
|
|
|
+
|
|
|
+ 3. HADOOP-1177. Fix bug where IOException in MapOutputLocation.getFile
|
|
|
+ was not being logged. (Devaraj Das via tomwhite)
|
|
|
+
|
|
|
+ 4. HADOOP-1175. Fix bugs in JSP for displaying a task's log messages.
|
|
|
+ (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+ 5. HADOOP-1191. Fix map tasks to wait until sort progress thread has
|
|
|
+ stopped before reporting the task done. (Devaraj Das via cutting)
|
|
|
+
|
|
|
+ 6. HADOOP-1192. Fix an integer overflow bug in FSShell's 'dus'
|
|
|
+ command and a performance problem in HDFS's implementation of it.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+ 7. HADOOP-1105. Fix reducers to make "progress" while iterating
|
|
|
+ through values. (Devaraj Das & Owen O'Malley via tomwhite)
|
|
|
+
|
|
|
+ 8. HADOOP-1179. Make Task Tracker close index file as soon as the read
|
|
|
+ is done when serving get-map-output requests.
|
|
|
+ (Devaraj Das via tomwhite)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.12.2 - 2007-23-17
|
|
|
+
|
|
|
+ 1. HADOOP-1135. Fix bug in block report processing which may cause
|
|
|
+ the namenode to delete blocks. (Dhruba Borthakur via tomwhite)
|
|
|
+
|
|
|
+ 2. HADOOP-1145. Make XML serializer and deserializer classes public
|
|
|
+ in record package. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+ 3. HADOOP-1140. Fix a deadlock in metrics. (David Bowen via cutting)
|
|
|
+
|
|
|
+ 4. HADOOP-1150. Fix streaming -reducer and -mapper to give them
|
|
|
+ defaults. (Owen O'Malley via tomwhite)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.12.1 - 2007-03-17
|
|
|
+
|
|
|
+ 1. HADOOP-1035. Fix a StackOverflowError in FSDataSet.
|
|
|
+ (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+ 2. HADOOP-1053. Fix VInt representation of negative values. Also
|
|
|
+ remove references in generated record code to methods outside of
|
|
|
+ the record package and improve some record documentation.
|
|
|
+ (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+ 3. HADOOP-1067. Compile fails if Checkstyle jar is present in lib
|
|
|
+ directory. Also remove dependency on a particular Checkstyle
|
|
|
+ version number. (tomwhite)
|
|
|
+
|
|
|
+ 4. HADOOP-1060. Fix an IndexOutOfBoundsException in the JobTracker
|
|
|
+ that could cause jobs to hang. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+ 5. HADOOP-1077. Fix a race condition fetching map outputs that could
|
|
|
+ hang reduces. (Devaraj Das via cutting)
|
|
|
+
|
|
|
+ 6. HADOOP-1083. Fix so that when a cluster restarts with a missing
|
|
|
+ datanode, its blocks are replicated. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+ 7. HADOOP-1082. Fix a NullPointerException in ChecksumFileSystem.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+ 8. HADOOP-1088. Fix record serialization of negative values.
|
|
|
+ (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+ 9. HADOOP-1080. Fix bug in bin/hadoop on Windows when native
|
|
|
+ libraries are present. (ab via cutting)
|
|
|
+
|
|
|
+10. HADOOP-1091. Fix a NullPointerException in MetricsRecord.
|
|
|
+ (David Bowen via tomwhite)
|
|
|
+
|
|
|
+11. HADOOP-1092. Fix a NullPointerException in HeartbeatMonitor
|
|
|
+ thread. (Hairong Kuang via tomwhite)
|
|
|
+
|
|
|
+12. HADOOP-1112. Fix a race condition in Hadoop metrics.
|
|
|
+ (David Bowen via tomwhite)
|
|
|
+
|
|
|
+13. HADOOP-1108. Checksummed file system should retry reading if a
|
|
|
+ different replica is found when handling ChecksumException.
|
|
|
+ (Hairong Kuang via tomwhite)
|
|
|
+
|
|
|
+14. HADOOP-1070. Fix a problem with number of racks and datanodes
|
|
|
+ temporarily doubling. (Konstantin Shvachko via tomwhite)
|
|
|
+
|
|
|
+15. HADOOP-1099. Fix NullPointerException in JobInProgress.
|
|
|
+ (Gautam Kowshik via tomwhite)
|
|
|
+
|
|
|
+16. HADOOP-1115. Fix bug where FsShell copyToLocal doesn't
|
|
|
+ copy directories. (Hairong Kuang via tomwhite)
|
|
|
+
|
|
|
+17. HADOOP-1109. Fix NullPointerException in StreamInputFormat.
|
|
|
+ (Koji Noguchi via tomwhite)
|
|
|
+
|
|
|
+18. HADOOP-1117. Fix DFS scalability: when the namenode is
|
|
|
+ restarted it consumes 80% CPU. (Dhruba Borthakur via
|
|
|
+ tomwhite)
|
|
|
+
|
|
|
+19. HADOOP-1089. Make the C++ version of write and read v-int
|
|
|
+ agree with the Java versions. (Milind Bhandarkar via
|
|
|
+ tomwhite)
|
|
|
+
|
|
|
+20. HADOOP-1096. Rename InputArchive and OutputArchive and
|
|
|
+ make them public. (Milind Bhandarkar via tomwhite)
|
|
|
+
|
|
|
+21. HADOOP-1128. Fix missing progress information in map tasks.
|
|
|
+ (Espen Amble Kolstad, Andrzej Bialecki, and Owen O'Malley
|
|
|
+ via tomwhite)
|
|
|
+
|
|
|
+22. HADOOP-1129. Fix DFSClient to not hide IOExceptions in
|
|
|
+ flush method. (Hairong Kuang via tomwhite)
|
|
|
+
|
|
|
+23. HADOOP-1126. Optimize CPU usage for under replicated blocks
|
|
|
+ when cluster restarts. (Hairong Kuang via tomwhite)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.12.0 - 2007-03-02
|
|
|
+
|
|
|
+ 1. HADOOP-975. Separate stdout and stderr from tasks.
|
|
|
+ (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+ 2. HADOOP-982. Add some setters and a toString() method to
|
|
|
+ BytesWritable. (omalley via cutting)
|
|
|
+
|
|
|
+ 3. HADOOP-858. Move contrib/smallJobsBenchmark to src/test, removing
|
|
|
+ obsolete bits. (Nigel Daley via cutting)
|
|
|
+
|
|
|
+ 4. HADOOP-992. Fix MiniMR unit tests to use MiniDFS when specified,
|
|
|
+ rather than the local FS. (omalley via cutting)
|
|
|
+
|
|
|
+ 5. HADOOP-954. Change use of metrics to use callback mechanism.
|
|
|
+ Also rename utility class Metrics to MetricsUtil.
|
|
|
+ (David Bowen & Nigel Daley via cutting)
|
|
|
+
|
|
|
+ 6. HADOOP-893. Improve HDFS client's handling of dead datanodes.
|
|
|
+ The set is no longer reset with each block, but rather is now
|
|
|
+ maintained for the life of an open file. (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+ 7. HADOOP-882. Upgrade to jets3t version 0.5, used by the S3
|
|
|
+ FileSystem. This version supports retries. (Michael Stack via cutting)
|
|
|
+
|
|
|
+ 8. HADOOP-977. Send task's stdout and stderr to JobClient's stdout
|
|
|
+ and stderr respectively, with each line tagged by the task's name.
|
|
|
+ (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+ 9. HADOOP-761. Change unit tests to not use /tmp. (Nigel Daley via cutting)
|
|
|
+
|
|
|
+10. HADOOP-1007. Make names of metrics used in Hadoop unique.
|
|
|
+ (Nigel Daley via cutting)
|
|
|
+
|
|
|
+11. HADOOP-491. Change mapred.task.timeout to be per-job, and make a
|
|
|
+ value of zero mean no timeout. Also change contrib/streaming to
|
|
|
+ disable task timeouts. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+12. HADOOP-1010. Add Reporter.NULL, a Reporter implementation that
|
|
|
+ does nothing. (Runping Qi via cutting)
|
|
|
+
|
|
|
+13. HADOOP-923. In HDFS NameNode, move replication computation to a
|
|
|
+ separate thread, to improve heartbeat processing time.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+14. HADOOP-476. Rewrite contrib/streaming command-line processing,
|
|
|
+ improving parameter validation. (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+15. HADOOP-973. Improve error messages in Namenode. This should help
|
|
|
+ to track down a problem that was appearing as a
|
|
|
+ NullPointerException. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+16. HADOOP-649. Fix so that jobs with no tasks are not lost.
|
|
|
+ (Thomas Friol via cutting)
|
|
|
+
|
|
|
+17. HADOOP-803. Reduce memory use by HDFS namenode, phase I.
|
|
|
+ (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+18. HADOOP-1021. Fix MRCaching-based unit tests on Windows.
|
|
|
+ (Nigel Daley via cutting)
|
|
|
+
|
|
|
+19. HADOOP-889. Remove duplicate code from HDFS unit tests.
|
|
|
+ (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+20. HADOOP-943. Improve HDFS's fsck command to display the filename
|
|
|
+ for under-replicated blocks. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+21. HADOOP-333. Add validator for sort benchmark output.
|
|
|
+ (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+22. HADOOP-947. Improve performance of datanode decomissioning.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+23. HADOOP-442. Permit one to specify hosts allowed to connect to
|
|
|
+ namenode and jobtracker with include and exclude files. (Wendy
|
|
|
+ Chien via cutting)
|
|
|
+
|
|
|
+24. HADOOP-1017. Cache constructors, for improved performance.
|
|
|
+ (Ron Bodkin via cutting)
|
|
|
+
|
|
|
+25. HADOOP-867. Move split creation out of JobTracker to client.
|
|
|
+ Splits are now saved in a separate file, read by task processes
|
|
|
+ directly, so that user code is no longer required in the
|
|
|
+ JobTracker. (omalley via cutting)
|
|
|
+
|
|
|
+26. HADOOP-1006. Remove obsolete '-local' option from test code.
|
|
|
+ (Gautam Kowshik via cutting)
|
|
|
+
|
|
|
+27. HADOOP-952. Create a public (shared) Hadoop EC2 AMI.
|
|
|
+ The EC2 scripts now support launch of public AMIs.
|
|
|
+ (tomwhite)
|
|
|
+
|
|
|
+28. HADOOP-1025. Remove some obsolete code in ipc.Server. (cutting)
|
|
|
+
|
|
|
+29. HADOOP-997. Implement S3 retry mechanism for failed block
|
|
|
+ transfers. This includes a generic retry mechanism for use
|
|
|
+ elsewhere in Hadoop. (tomwhite)
|
|
|
+
|
|
|
+30. HADOOP-990. Improve HDFS support for full datanode volumes.
|
|
|
+ (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+31. HADOOP-564. Replace uses of "dfs://" URIs with the more standard
|
|
|
+ "hdfs://". (Wendy Chien via cutting)
|
|
|
+
|
|
|
+32. HADOOP-1030. In unit tests, unify setting of ipc.client.timeout.
|
|
|
+ Also increase the value used from one to two seconds, in hopes of
|
|
|
+ making tests complete more reliably. (cutting)
|
|
|
+
|
|
|
+33. HADOOP-654. Stop assigning tasks to a tasktracker if it has
|
|
|
+ failed more than a specified number in the job.
|
|
|
+ (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+34. HADOOP-985. Change HDFS to identify nodes by IP address rather
|
|
|
+ than by DNS hostname. (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+35. HADOOP-248. Optimize location of map outputs to not use random
|
|
|
+ probes. (Devaraj Das via cutting)
|
|
|
+
|
|
|
+36. HADOOP-1029. Fix streaming's input format to correctly seek to
|
|
|
+ the start of splits. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+37. HADOOP-492. Add per-job and per-task counters. These are
|
|
|
+ incremented via the Reporter interface and available through the
|
|
|
+ web ui and the JobClient API. The mapreduce framework maintains a
|
|
|
+ few basic counters, and applications may add their own. Counters
|
|
|
+ are also passed to the metrics system.
|
|
|
+ (David Bowen via cutting)
|
|
|
+
|
|
|
+38. HADOOP-1034. Fix datanode to better log exceptions.
|
|
|
+ (Philippe Gassmann via cutting)
|
|
|
+
|
|
|
+39. HADOOP-878. In contrib/streaming, fix reducer=NONE to work with
|
|
|
+ multiple maps. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+40. HADOOP-1039. In HDFS's TestCheckpoint, avoid restarting
|
|
|
+ MiniDFSCluster so often, speeding this test. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+41. HADOOP-1040. Update RandomWriter example to use counters and
|
|
|
+ user-defined input and output formats. (omalley via cutting)
|
|
|
+
|
|
|
+42. HADOOP-1027. Fix problems with in-memory merging during shuffle
|
|
|
+ and re-enable this optimization. (Devaraj Das via cutting)
|
|
|
+
|
|
|
+43. HADOOP-1036. Fix exception handling in TaskTracker to keep tasks
|
|
|
+ from being lost. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+44. HADOOP-1042. Improve the handling of failed map output fetches.
|
|
|
+ (Devaraj Das via cutting)
|
|
|
+
|
|
|
+45. HADOOP-928. Make checksums optional per FileSystem.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+46. HADOOP-1044. Fix HDFS's TestDecommission to not spuriously fail.
|
|
|
+ (Wendy Chien via cutting)
|
|
|
+
|
|
|
+47. HADOOP-972. Optimize HDFS's rack-aware block placement algorithm.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+48. HADOOP-1043. Optimize shuffle, increasing parallelism.
|
|
|
+ (Devaraj Das via cutting)
|
|
|
+
|
|
|
+49. HADOOP-940. Improve HDFS's replication scheduling.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+50. HADOOP-1020. Fix a bug in Path resolution, and a with unit tests
|
|
|
+ on Windows. (cutting)
|
|
|
+
|
|
|
+51. HADOOP-941. Enhance record facility.
|
|
|
+ (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+52. HADOOP-1000. Fix so that log messages in task subprocesses are
|
|
|
+ not written to a task's standard error. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+53. HADOOP-1037. Fix bin/slaves.sh, which currently only works with
|
|
|
+ /bin/bash, to specify /bin/bash rather than /bin/sh. (cutting)
|
|
|
+
|
|
|
+54. HADOOP-1046. Clean up tmp from partially received stale block files. (ab)
|
|
|
+
|
|
|
+55. HADOOP-1041. Optimize mapred counter implementation. Also group
|
|
|
+ counters by their declaring Enum. (David Bowen via cutting)
|
|
|
+
|
|
|
+56. HADOOP-1032. Permit one to specify jars that will be cached
|
|
|
+ across multiple jobs. (Gautam Kowshik via cutting)
|
|
|
+
|
|
|
+57. HADOOP-1051. Add optional checkstyle task to build.xml. To use
|
|
|
+ this developers must download the (LGPL'd) checkstyle jar
|
|
|
+ themselves. (tomwhite via cutting)
|
|
|
+
|
|
|
+58. HADOOP-1049. Fix a race condition in IPC client.
|
|
|
+ (Devaraj Das via cutting)
|
|
|
+
|
|
|
+60. HADOOP-1056. Check HDFS include/exclude node lists with both IP
|
|
|
+ address and hostname. (Wendy Chien via cutting)
|
|
|
+
|
|
|
+61. HADOOP-994. In HDFS, limit the number of blocks invalidated at
|
|
|
+ once. Large lists were causing datenodes to timeout.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+62. HADOOP-432. Add a trash feature, disabled by default. When
|
|
|
+ enabled, the FSShell 'rm' command will move things to a trash
|
|
|
+ directory in the filesystem. In HDFS, a thread periodically
|
|
|
+ checkpoints the trash and removes old checkpoints. (cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.11.2 - 2007-02-16
|
|
|
+
|
|
|
+ 1. HADOOP-1009. Fix an infinite loop in the HDFS namenode.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+ 2. HADOOP-1014. Disable in-memory merging during shuffle, as this is
|
|
|
+ causing data corruption. (Devaraj Das via cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.11.1 - 2007-02-09
|
|
|
+
|
|
|
+ 1. HADOOP-976. Make SequenceFile.Metadata public. (Runping Qi via cutting)
|
|
|
+
|
|
|
+ 2. HADOOP-917. Fix a NullPointerException in SequenceFile's merger
|
|
|
+ with large map outputs. (omalley via cutting)
|
|
|
+
|
|
|
+ 3. HADOOP-984. Fix a bug in shuffle error handling introduced by
|
|
|
+ HADOOP-331. If a map output is unavailable, the job tracker is
|
|
|
+ once more informed. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+ 4. HADOOP-987. Fix a problem in HDFS where blocks were not removed
|
|
|
+ from neededReplications after a replication target was selected.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+Release 0.11.0 - 2007-02-02
|
|
|
+
|
|
|
+ 1. HADOOP-781. Remove methods deprecated in 0.10 that are no longer
|
|
|
+ widely used. (cutting)
|
|
|
+
|
|
|
+ 2. HADOOP-842. Change HDFS protocol so that the open() method is
|
|
|
+ passed the client hostname, to permit the namenode to order block
|
|
|
+ locations on the basis of network topology.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+ 3. HADOOP-852. Add an ant task to compile record definitions, and
|
|
|
+ use it to compile record unit tests. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+ 4. HADOOP-757. Fix "Bad File Descriptor" exception in HDFS client
|
|
|
+ when an output file is closed twice. (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+ 5. [ intentionally blank ]
|
|
|
+
|
|
|
+ 6. HADOOP-890. Replace dashes in metric names with underscores,
|
|
|
+ for better compatibility with some monitoring systems.
|
|
|
+ (Nigel Daley via cutting)
|
|
|
+
|
|
|
+ 7. HADOOP-801. Add to jobtracker a log of task completion events.
|
|
|
+ (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+ 8. HADOOP-855. In HDFS, try to repair files with checksum errors.
|
|
|
+ An exception is still thrown, but corrupt blocks are now removed
|
|
|
+ when they have replicas. (Wendy Chien via cutting)
|
|
|
+
|
|
|
+ 9. HADOOP-886. Reduce number of timer threads created by metrics API
|
|
|
+ by pooling contexts. (Nigel Daley via cutting)
|
|
|
+
|
|
|
+10. HADOOP-897. Add a "javac.args" property to build.xml that permits
|
|
|
+ one to pass arbitrary options to javac. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+11. HADOOP-899. Update libhdfs for changes in HADOOP-871.
|
|
|
+ (Sameer Paranjpye via cutting)
|
|
|
+
|
|
|
+12. HADOOP-905. Remove some dead code from JobClient. (cutting)
|
|
|
+
|
|
|
+13. HADOOP-902. Fix a NullPointerException in HDFS client when
|
|
|
+ closing output streams. (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+14. HADOOP-735. Switch generated record code to use BytesWritable to
|
|
|
+ represent fields of type 'buffer'. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+15. HADOOP-830. Improve mapreduce merge performance by buffering and
|
|
|
+ merging multiple map outputs as they arrive at reduce nodes before
|
|
|
+ they're written to disk. (Devaraj Das via cutting)
|
|
|
+
|
|
|
+16. HADOOP-908. Add a new contrib package, Abacus, that simplifies
|
|
|
+ counting and aggregation, built on MapReduce. (Runping Qi via cutting)
|
|
|
+
|
|
|
+17. HADOOP-901. Add support for recursive renaming to the S3 filesystem.
|
|
|
+ (Tom White via cutting)
|
|
|
+
|
|
|
+18. HADOOP-912. Fix a bug in TaskTracker.isIdle() that was
|
|
|
+ sporadically causing unit test failures. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+19. HADOOP-909. Fix the 'du' command to correctly compute the size of
|
|
|
+ FileSystem directory trees. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+20. HADOOP-731. When a checksum error is encountered on a file stored
|
|
|
+ in HDFS, try another replica of the data, if any.
|
|
|
+ (Wendy Chien via cutting)
|
|
|
+
|
|
|
+21. HADOOP-732. Add support to SequenceFile for arbitrary metadata,
|
|
|
+ as a set of attribute value pairs. (Runping Qi via cutting)
|
|
|
+
|
|
|
+22. HADOOP-929. Fix PhasedFileSystem to pass configuration to
|
|
|
+ underlying FileSystem. (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+23. HADOOP-935. Fix contrib/abacus to not delete pre-existing output
|
|
|
+ files, but rather to fail in this case. (Runping Qi via cutting)
|
|
|
+
|
|
|
+24. HADOOP-936. More metric renamings, as in HADOOP-890.
|
|
|
+ (Nigel Daley via cutting)
|
|
|
+
|
|
|
+25. HADOOP-856. Fix HDFS's fsck command to not report that
|
|
|
+ non-existent filesystems are healthy. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+26. HADOOP-602. Remove the dependency on Lucene's PriorityQueue
|
|
|
+ utility, by copying it into Hadoop. This facilitates using Hadoop
|
|
|
+ with different versions of Lucene without worrying about CLASSPATH
|
|
|
+ order. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+27. [ intentionally blank ]
|
|
|
+
|
|
|
+28. HADOOP-227. Add support for backup namenodes, which periodically
|
|
|
+ get snapshots of the namenode state. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+29. HADOOP-884. Add scripts in contrib/ec2 to facilitate running
|
|
|
+ Hadoop on an Amazon's EC2 cluster. (Tom White via cutting)
|
|
|
+
|
|
|
+30. HADOOP-937. Change the namenode to request re-registration of
|
|
|
+ datanodes in more circumstances. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+31. HADOOP-922. Optimize small forward seeks in HDFS. If data is has
|
|
|
+ likely already in flight, skip ahead rather than re-opening the
|
|
|
+ block. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+32. HADOOP-961. Add a 'job -events' sub-command that prints job
|
|
|
+ events, including task completions and failures. (omalley via cutting)
|
|
|
+
|
|
|
+33. HADOOP-959. Fix namenode snapshot code added in HADOOP-227 to
|
|
|
+ work on Windows. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+34. HADOOP-934. Fix TaskTracker to catch metrics exceptions that were
|
|
|
+ causing heartbeats to fail. (Arun Murthy via cutting)
|
|
|
+
|
|
|
+35. HADOOP-881. Fix JobTracker web interface to display the correct
|
|
|
+ number of task failures. (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+36. HADOOP-788. Change contrib/streaming to subclass TextInputFormat,
|
|
|
+ permitting it to take advantage of native compression facilities.
|
|
|
+ (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+37. HADOOP-962. In contrib/ec2: make scripts executable in tar file;
|
|
|
+ add a README; make the environment file use a template.
|
|
|
+ (Tom White via cutting)
|
|
|
+
|
|
|
+38. HADOOP-549. Fix a NullPointerException in TaskReport's
|
|
|
+ serialization. (omalley via cutting)
|
|
|
+
|
|
|
+39. HADOOP-963. Fix remote exceptions to have the stack trace of the
|
|
|
+ caller thread, not the IPC listener thread. (omalley via cutting)
|
|
|
+
|
|
|
+40. HADOOP-967. Change RPC clients to start sending a version header.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+41. HADOOP-964. Fix a bug introduced by HADOOP-830 where jobs failed
|
|
|
+ whose comparators and/or i/o types were in the job's jar.
|
|
|
+ (Dennis Kubes via cutting)
|
|
|
+
|
|
|
+42. HADOOP-969. Fix a deadlock in JobTracker. (omalley via cutting)
|
|
|
+
|
|
|
+43. HADOOP-862. Add support for the S3 FileSystem to the CopyFiles
|
|
|
+ tool. (Michael Stack via cutting)
|
|
|
+
|
|
|
+44. HADOOP-965. Fix IsolationRunner so that job's jar can be found.
|
|
|
+ (Dennis Kubes via cutting)
|
|
|
+
|
|
|
+45. HADOOP-309. Fix two NullPointerExceptions in StatusHttpServer.
|
|
|
+ (navychen via cutting)
|
|
|
+
|
|
|
+46. HADOOP-692. Add rack awareness to HDFS's placement of blocks.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.10.1 - 2007-01-10
|
|
|
+
|
|
|
+ 1. HADOOP-857. Fix S3 FileSystem implementation to permit its use
|
|
|
+ for MapReduce input and output. (Tom White via cutting)
|
|
|
+
|
|
|
+ 2. HADOOP-863. Reduce logging verbosity introduced by HADOOP-813.
|
|
|
+ (Devaraj Das via cutting)
|
|
|
+
|
|
|
+ 3. HADOOP-815. Fix memory leaks in JobTracker. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+ 4. HADOOP-600. Fix a race condition in JobTracker.
|
|
|
+ (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+ 5. HADOOP-864. Fix 'bin/hadoop -jar' to operate correctly when
|
|
|
+ hadoop.tmp.dir does not yet exist. (omalley via cutting)
|
|
|
+
|
|
|
+ 6. HADOOP-866. Fix 'dfs -get' command to remove existing crc files,
|
|
|
+ if any. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+ 7. HADOOP-871. Fix a bug in bin/hadoop setting JAVA_LIBRARY_PATH.
|
|
|
+ (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+ 8. HADOOP-868. Decrease the number of open files during map,
|
|
|
+ respecting io.sort.fa ctor. (Devaraj Das via cutting)
|
|
|
+
|
|
|
+ 9. HADOOP-865. Fix S3 FileSystem so that partially created files can
|
|
|
+ be deleted. (Tom White via cutting)
|
|
|
+
|
|
|
+10. HADOOP-873. Pass java.library.path correctly to child processes.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+11. HADOOP-851. Add support for the LZO codec. This is much faster
|
|
|
+ than the default, zlib-based compression, but it is only available
|
|
|
+ when the native library is built. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+12. HADOOP-880. Fix S3 FileSystem to remove directories.
|
|
|
+ (Tom White via cutting)
|
|
|
+
|
|
|
+13. HADOOP-879. Fix InputFormatBase to handle output generated by
|
|
|
+ MapFileOutputFormat. (cutting)
|
|
|
+
|
|
|
+14. HADOOP-659. In HDFS, prioritize replication of blocks based on
|
|
|
+ current replication level. Blocks which are severely
|
|
|
+ under-replicated should be further replicated before blocks which
|
|
|
+ are less under-replicated. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+15. HADOOP-726. Deprecate FileSystem locking methods. They are not
|
|
|
+ currently usable. Locking should eventually provided as an
|
|
|
+ independent service. (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+16. HADOOP-758. Fix exception handling during reduce so that root
|
|
|
+ exceptions are not masked by exceptions in cleanups.
|
|
|
+ (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.10.0 - 2007-01-05
|
|
|
+
|
|
|
+ 1. HADOOP-763. Change DFS namenode benchmark to not use MapReduce.
|
|
|
+ (Nigel Daley via cutting)
|
|
|
+
|
|
|
+ 2. HADOOP-777. Use fully-qualified hostnames for tasktrackers and
|
|
|
+ datanodes. (Mahadev Konar via cutting)
|
|
|
+
|
|
|
+ 3. HADOOP-621. Change 'dfs -cat' to exit sooner when output has been
|
|
|
+ closed. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+ 4. HADOOP-752. Rationalize some synchronization in DFS namenode.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+ 5. HADOOP-629. Fix RPC services to better check the protocol name and
|
|
|
+ version. (omalley via cutting)
|
|
|
+
|
|
|
+ 6. HADOOP-774. Limit the number of invalid blocks returned with
|
|
|
+ heartbeats by the namenode to datanodes. Transmitting and
|
|
|
+ processing very large invalid block lists can tie up both the
|
|
|
+ namenode and datanode for too long. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+ 7. HADOOP-738. Change 'dfs -get' command to not create CRC files by
|
|
|
+ default, adding a -crc option to force their creation.
|
|
|
+ (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+ 8. HADOOP-676. Improved exceptions and error messages for common job
|
|
|
+ input specification errors. (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+ 9. [Included in 0.9.2 release]
|
|
|
+
|
|
|
+10. HADOOP-756. Add new dfsadmin option to wait for filesystem to be
|
|
|
+ operational. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+11. HADOOP-770. Fix jobtracker web interface to display, on restart,
|
|
|
+ jobs that were running when it was last stopped.
|
|
|
+ (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+12. HADOOP-331. Write all map outputs to a single file with an index,
|
|
|
+ rather than to a separate file per reduce task. This should both
|
|
|
+ speed the shuffle and make things more scalable.
|
|
|
+ (Devaraj Das via cutting)
|
|
|
+
|
|
|
+13. HADOOP-818. Fix contrib unit tests to not depend on core unit
|
|
|
+ tests. (omalley via cutting)
|
|
|
+
|
|
|
+14. HADOOP-786. Log common exception at debug level.
|
|
|
+ (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+15. HADOOP-796. Provide more convenient access to failed task
|
|
|
+ information in the web interface. (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+16. HADOOP-764. Reduce memory allocations in namenode some.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+17. HADOOP-802. Update description of mapred.speculative.execution to
|
|
|
+ mention reduces. (Nigel Daley via cutting)
|
|
|
+
|
|
|
+18. HADOOP-806. Include link to datanodes on front page of namenode
|
|
|
+ web interface. (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+19. HADOOP-618. Make JobSubmissionProtocol public.
|
|
|
+ (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+20. HADOOP-782. Fully remove killed tasks. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+21. HADOOP-792. Fix 'dfs -mv' to return correct status.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+22. HADOOP-673. Give each task its own working directory again.
|
|
|
+ (Mahadev Konar via cutting)
|
|
|
+
|
|
|
+23. HADOOP-571. Extend the syntax of Path to be a URI; to be
|
|
|
+ optionally qualified with a scheme and authority. The scheme
|
|
|
+ determines the FileSystem implementation, while the authority
|
|
|
+ determines the FileSystem instance. New FileSystem
|
|
|
+ implementations may be provided by defining an fs.<scheme>.impl
|
|
|
+ property, naming the FileSystem implementation class. This
|
|
|
+ permits easy integration of new FileSystem implementations.
|
|
|
+ (cutting)
|
|
|
+
|
|
|
+24. HADOOP-720. Add an HDFS white paper to website.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+25. HADOOP-794. Fix a divide-by-zero exception when a job specifies
|
|
|
+ zero map tasks. (omalley via cutting)
|
|
|
+
|
|
|
+26. HADOOP-454. Add a 'dfs -dus' command that provides summary disk
|
|
|
+ usage. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+27. HADOOP-574. Add an Amazon S3 implementation of FileSystem. To
|
|
|
+ use this, one need only specify paths of the form
|
|
|
+ s3://id:secret@bucket/. Alternately, the AWS access key id and
|
|
|
+ secret can be specified in your config, with the properties
|
|
|
+ fs.s3.awsAccessKeyId and fs.s3.awsSecretAccessKey.
|
|
|
+ (Tom White via cutting)
|
|
|
+
|
|
|
+28. HADOOP-824. Rename DFSShell to be FsShell, since it applies
|
|
|
+ generically to all FileSystem implementations. (cutting)
|
|
|
+
|
|
|
+29. HADOOP-813. Fix map output sorting to report progress, so that
|
|
|
+ sorts which take longer than the task timeout do not fail.
|
|
|
+ (Devaraj Das via cutting)
|
|
|
+
|
|
|
+30. HADOOP-825. Fix HDFS daemons when configured with new URI syntax.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+31. HADOOP-596. Fix a bug in phase reporting during reduce.
|
|
|
+ (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+32. HADOOP-811. Add a utility, MultithreadedMapRunner.
|
|
|
+ (Alejandro Abdelnur via cutting)
|
|
|
+
|
|
|
+33. HADOOP-829. Within HDFS, clearly separate three different
|
|
|
+ representations for datanodes: one for RPCs, one for
|
|
|
+ namenode-internal use, and one for namespace persistence.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+34. HADOOP-823. Fix problem starting datanode when not all configured
|
|
|
+ data directories exist. (Bryan Pendleton via cutting)
|
|
|
+
|
|
|
+35. HADOOP-451. Add a Split interface. CAUTION: This incompatibly
|
|
|
+ changes the InputFormat and RecordReader interfaces. Not only is
|
|
|
+ FileSplit replaced with Split, but a FileSystem parameter is no
|
|
|
+ longer passed in several methods, input validation has changed,
|
|
|
+ etc. (omalley via cutting)
|
|
|
+
|
|
|
+36. HADOOP-814. Optimize locking in namenode. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+37. HADOOP-738. Change 'fs -put' and 'fs -get' commands to accept
|
|
|
+ standard input and output, respectively. Standard i/o is
|
|
|
+ specified by a file named '-'. (Wendy Chien via cutting)
|
|
|
+
|
|
|
+38. HADOOP-835. Fix a NullPointerException reading record-compressed
|
|
|
+ SequenceFiles. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+39. HADOOP-836. Fix a MapReduce bug on Windows, where the wrong
|
|
|
+ FileSystem was used. Also add a static FileSystem.getLocal()
|
|
|
+ method and better Path checking in HDFS, to help avoid such issues
|
|
|
+ in the future. (omalley via cutting)
|
|
|
+
|
|
|
+40. HADOOP-837. Improve RunJar utility to unpack jar file
|
|
|
+ hadoop.tmp.dir, rather than the system temporary directory.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+41. HADOOP-841. Fix native library to build 32-bit version even when
|
|
|
+ on a 64-bit host, if a 32-bit JVM is used. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+42. HADOOP-838. Fix tasktracker to pass java.library.path to
|
|
|
+ sub-processes, so that libhadoop.a is found.
|
|
|
+ (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+43. HADOOP-844. Send metrics messages on a fixed-delay schedule
|
|
|
+ instead of a fixed-rate schedule. (David Bowen via cutting)
|
|
|
+
|
|
|
+44. HADOOP-849. Fix OutOfMemory exceptions in TaskTracker due to a
|
|
|
+ file handle leak in SequenceFile. (Devaraj Das via cutting)
|
|
|
+
|
|
|
+45. HADOOP-745. Fix a synchronization bug in the HDFS namenode.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+46. HADOOP-850. Add Writable implementations for variable-length
|
|
|
+ integers. (ab via cutting)
|
|
|
+
|
|
|
+47. HADOOP-525. Add raw comparators to record types. This greatly
|
|
|
+ improves record sort performance. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+48. HADOOP-628. Fix a problem with 'fs -cat' command, where some
|
|
|
+ characters were replaced with question marks. (Wendy Chien via cutting)
|
|
|
+
|
|
|
+49. HADOOP-804. Reduce verbosity of MapReduce logging.
|
|
|
+ (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+50. HADOOP-853. Rename 'site' to 'docs', in preparation for inclusion
|
|
|
+ in releases. (cutting)
|
|
|
+
|
|
|
+51. HADOOP-371. Include contrib jars and site documentation in
|
|
|
+ distributions. Also add contrib and example documentation to
|
|
|
+ distributed javadoc, in separate sections. (Nigel Daley via cutting)
|
|
|
+
|
|
|
+52. HADOOP-846. Report progress during entire map, as sorting of
|
|
|
+ intermediate outputs may happen at any time, potentially causing
|
|
|
+ task timeouts. (Devaraj Das via cutting)
|
|
|
+
|
|
|
+53. HADOOP-840. In task tracker, queue task cleanups and perform them
|
|
|
+ in a separate thread. (omalley & Mahadev Konar via cutting)
|
|
|
+
|
|
|
+54. HADOOP-681. Add to HDFS the ability to decommission nodes. This
|
|
|
+ causes their blocks to be re-replicated on other nodes, so that
|
|
|
+ they may be removed from a cluster. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+55. HADOOP-470. In HDFS web ui, list the datanodes containing each
|
|
|
+ copy of a block. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+56. HADOOP-700. Change bin/hadoop to only include core jar file on
|
|
|
+ classpath, not example, test, etc. Also rename core jar to
|
|
|
+ hadoop-${version}-core.jar so that it can be more easily
|
|
|
+ identified. (Nigel Daley via cutting)
|
|
|
+
|
|
|
+57. HADOOP-619. Extend InputFormatBase to accept individual files and
|
|
|
+ glob patterns as MapReduce inputs, not just directories. Also
|
|
|
+ change contrib/streaming to use this. (Sanjay Dahia via cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.9.2 - 2006-12-15
|
|
|
+
|
|
|
+ 1. HADOOP-639. Restructure InterTrackerProtocol to make task
|
|
|
+ accounting more reliable. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+ 2. HADOOP-827. Turn off speculative execution by default, since it's
|
|
|
+ currently broken. (omalley via cutting)
|
|
|
+
|
|
|
+ 3. HADOOP-791. Fix a deadlock in the task tracker.
|
|
|
+ (Mahadev Konar via cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.9.1 - 2006-12-06
|
|
|
+
|
|
|
+ 1. HADOOP-780. Use ReflectionUtils to instantiate key and value
|
|
|
+ objects. (ab)
|
|
|
+
|
|
|
+ 2. HADOOP-779. Fix contrib/streaming to work correctly with gzipped
|
|
|
+ input files. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.9.0 - 2006-12-01
|
|
|
+
|
|
|
+ 1. HADOOP-655. Remove most deprecated code. A few deprecated things
|
|
|
+ remain, notably UTF8 and some methods that are still required.
|
|
|
+ Also cleaned up constructors for SequenceFile, MapFile, SetFile,
|
|
|
+ and ArrayFile a bit. (cutting)
|
|
|
+
|
|
|
+ 2. HADOOP-565. Upgrade to Jetty version 6. (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+ 3. HADOOP-682. Fix DFS format command to work correctly when
|
|
|
+ configured with a non-existent directory. (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+ 4. HADOOP-645. Fix a bug in contrib/streaming when -reducer is NONE.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+ 5. HADOOP-687. Fix a classpath bug in bin/hadoop that blocked the
|
|
|
+ servers from starting. (Sameer Paranjpye via omalley)
|
|
|
+
|
|
|
+ 6. HADOOP-683. Remove a script dependency on bash, so it works with
|
|
|
+ dash, the new default for /bin/sh on Ubuntu. (James Todd via cutting)
|
|
|
+
|
|
|
+ 7. HADOOP-382. Extend unit tests to run multiple datanodes.
|
|
|
+ (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+ 8. HADOOP-604. Fix some synchronization issues and a
|
|
|
+ NullPointerException in DFS datanode. (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+ 9. HADOOP-459. Fix memory leaks and a host of other issues with
|
|
|
+ libhdfs. (Sameer Paranjpye via cutting)
|
|
|
+
|
|
|
+10. HADOOP-694. Fix a NullPointerException in jobtracker.
|
|
|
+ (Mahadev Konar via cutting)
|
|
|
+
|
|
|
+11. HADOOP-637. Fix a memory leak in the IPC server. Direct buffers
|
|
|
+ are not collected like normal buffers, and provided little
|
|
|
+ advantage. (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+12. HADOOP-696. Fix TestTextInputFormat unit test to not rely on the
|
|
|
+ order of directory listings. (Sameer Paranjpye via cutting)
|
|
|
+
|
|
|
+13. HADOOP-611. Add support for iterator-based merging to
|
|
|
+ SequenceFile. (Devaraj Das via cutting)
|
|
|
+
|
|
|
+14. HADOOP-688. Move DFS administrative commands to a separate
|
|
|
+ command named 'dfsadmin'. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+15. HADOOP-708. Fix test-libhdfs to return the correct status, so
|
|
|
+ that failures will break the build. (Nigel Daley via cutting)
|
|
|
+
|
|
|
+16. HADOOP-646. Fix namenode to handle edits files larger than 2GB.
|
|
|
+ (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+17. HADOOP-705. Fix a bug in the JobTracker when failed jobs were
|
|
|
+ not completely cleaned up. (Mahadev Konar via cutting)
|
|
|
+
|
|
|
+18. HADOOP-613. Perform final merge while reducing. This removes one
|
|
|
+ sort pass over the data and should consequently significantly
|
|
|
+ decrease overall processing time. (Devaraj Das via cutting)
|
|
|
+
|
|
|
+19. HADOOP-661. Make each job's configuration visible through the web
|
|
|
+ ui. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+20. HADOOP-489. In MapReduce, separate user logs from system logs.
|
|
|
+ Each task's log output is now available through the web ui. (Arun
|
|
|
+ C Murthy via cutting)
|
|
|
+
|
|
|
+21. HADOOP-712. Fix record io's xml serialization to correctly handle
|
|
|
+ control-characters. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+22. HADOOP-668. Improvements to the web-based DFS browser.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+23. HADOOP-715. Fix build.xml so that test logs are written in build
|
|
|
+ directory, rather than in CWD. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+24. HADOOP-538. Add support for building an optional native library,
|
|
|
+ libhadoop.so, that improves the performance of zlib-based
|
|
|
+ compression. To build this, specify -Dcompile.native to Ant.
|
|
|
+ (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+25. HADOOP-610. Fix an problem when the DFS block size is configured
|
|
|
+ to be smaller than the buffer size, typically only when debugging.
|
|
|
+ (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+26. HADOOP-695. Fix a NullPointerException in contrib/streaming.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+27. HADOOP-652. In DFS, when a file is deleted, the block count is
|
|
|
+ now decremented. (Vladimir Krokhmalyov via cutting)
|
|
|
+
|
|
|
+28. HADOOP-725. In DFS, optimize block placement algorithm,
|
|
|
+ previously a performance bottleneck. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+29. HADOOP-723. In MapReduce, fix a race condition during the
|
|
|
+ shuffle, which resulted in FileNotFoundExceptions. (omalley via cutting)
|
|
|
+
|
|
|
+30. HADOOP-447. In DFS, fix getBlockSize(Path) to work with relative
|
|
|
+ paths. (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+31. HADOOP-733. Make exit codes in DFShell consistent and add a unit
|
|
|
+ test. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+32. HADOOP-709. Fix contrib/streaming to work with commands that
|
|
|
+ contain control characters. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+33. HADOOP-677. In IPC, permit a version header to be transmitted
|
|
|
+ when connections are established. This will permit us to change
|
|
|
+ the format of IPC requests back-compatibly in subsequent releases.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+34. HADOOP-699. Fix DFS web interface so that filesystem browsing
|
|
|
+ works correctly, using the right port number. Also add support
|
|
|
+ for sorting datanode list by various columns.
|
|
|
+ (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+35. HADOOP-76. Implement speculative reduce. Now when a job is
|
|
|
+ configured for speculative execution, both maps and reduces will
|
|
|
+ execute speculatively. Reduce outputs are written to temporary
|
|
|
+ location and moved to the final location when reduce is complete.
|
|
|
+ (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+36. HADOOP-736. Roll back to Jetty 5.1.4, due to performance problems
|
|
|
+ with Jetty 6.0.1.
|
|
|
+
|
|
|
+37. HADOOP-739. Fix TestIPC to use different port number, making it
|
|
|
+ more reliable. (Nigel Daley via cutting)
|
|
|
+
|
|
|
+38. HADOOP-749. Fix a NullPointerException in jobfailures.jsp.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+39. HADOOP-747. Fix record serialization to work correctly when
|
|
|
+ records are embedded in Maps. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+40. HADOOP-698. Fix HDFS client not to retry the same datanode on
|
|
|
+ read failures. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+41. HADOOP-689. Add GenericWritable, to facilitate polymorphism in
|
|
|
+ MapReduce, SequenceFile, etc. (Feng Jiang via cutting)
|
|
|
+
|
|
|
+42. HADOOP-430. Stop datanode's HTTP server when registration with
|
|
|
+ namenode fails. (Wendy Chien via cutting)
|
|
|
+
|
|
|
+43. HADOOP-750. Fix a potential race condition during mapreduce
|
|
|
+ shuffle. (omalley via cutting)
|
|
|
+
|
|
|
+44. HADOOP-728. Fix contrib/streaming-related issues, including
|
|
|
+ '-reducer NONE'. (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.8.0 - 2006-11-03
|
|
|
+
|
|
|
+ 1. HADOOP-477. Extend contrib/streaming to scan the PATH environment
|
|
|
+ variables when resolving executable program names.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+ 2. HADOOP-583. In DFSClient, reduce the log level of re-connect
|
|
|
+ attempts from 'info' to 'debug', so they are not normally shown.
|
|
|
+ (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+ 3. HADOOP-498. Re-implement DFS integrity checker to run server-side,
|
|
|
+ for much improved performance. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+ 4. HADOOP-586. Use the jar name for otherwise un-named jobs.
|
|
|
+ (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+ 5. HADOOP-514. Make DFS heartbeat interval configurable.
|
|
|
+ (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+ 6. HADOOP-588. Fix logging and accounting of failed tasks.
|
|
|
+ (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+ 7. HADOOP-462. Improve command line parsing in DFSShell, so that
|
|
|
+ incorrect numbers of arguments result in informative errors rather
|
|
|
+ than ArrayOutOfBoundsException. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+ 8. HADOOP-561. Fix DFS so that one replica of each block is written
|
|
|
+ locally, if possible. This was the intent, but there as a bug.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+ 9. HADOOP-610. Fix TaskTracker to survive more exceptions, keeping
|
|
|
+ tasks from becoming lost. (omalley via cutting)
|
|
|
+
|
|
|
+10. HADOOP-625. Add a servlet to all http daemons that displays a
|
|
|
+ stack dump, useful for debugging. (omalley via cutting)
|
|
|
+
|
|
|
+11. HADOOP-554. Fix DFSShell to return -1 for errors.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+12. HADOOP-626. Correct the documentation in the NNBench example
|
|
|
+ code, and also remove a mistaken call there.
|
|
|
+ (Nigel Daley via cutting)
|
|
|
+
|
|
|
+13. HADOOP-634. Add missing license to many files.
|
|
|
+ (Nigel Daley via cutting)
|
|
|
+
|
|
|
+14. HADOOP-627. Fix some synchronization problems in MiniMRCluster
|
|
|
+ that sometimes caused unit tests to fail. (Nigel Daley via cutting)
|
|
|
+
|
|
|
+15. HADOOP-563. Improve the NameNode's lease policy so that leases
|
|
|
+ are held for one hour without renewal (instead of one minute).
|
|
|
+ However another attempt to create the same file will still succeed
|
|
|
+ if the lease has not been renewed within a minute. This prevents
|
|
|
+ communication or scheduling problems from causing a write to fail
|
|
|
+ for up to an hour, barring some other process trying to create the
|
|
|
+ same file. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+16. HADOOP-635. In DFSShell, permit specification of multiple files
|
|
|
+ as the source for file copy and move commands.
|
|
|
+ (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+17. HADOOP-641. Change NameNode to request a fresh block report from
|
|
|
+ a re-discovered DataNode, so that no-longer-needed replications
|
|
|
+ are stopped promptly. (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+18. HADOOP-642. Change IPC client to specify an explicit connect
|
|
|
+ timeout. (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+19. HADOOP-638. Fix an unsynchronized access to TaskTracker's
|
|
|
+ internal state. (Nigel Daley via cutting)
|
|
|
+
|
|
|
+20. HADOOP-624. Fix servlet path to stop a Jetty warning on startup.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+21. HADOOP-578. Failed tasks are no longer placed at the end of the
|
|
|
+ task queue. This was originally done to work around other
|
|
|
+ problems that have now been fixed. Re-executing failed tasks
|
|
|
+ sooner causes buggy jobs to fail faster. (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+22. HADOOP-658. Update source file headers per Apache policy. (cutting)
|
|
|
+
|
|
|
+23. HADOOP-636. Add MapFile & ArrayFile constructors which accept a
|
|
|
+ Progressable, and pass it down to SequenceFile. This permits
|
|
|
+ reduce tasks which use MapFile to still report progress while
|
|
|
+ writing blocks to the filesystem. (cutting)
|
|
|
+
|
|
|
+24. HADOOP-576. Enable contrib/streaming to use the file cache. Also
|
|
|
+ extend the cache to permit symbolic links to cached items, rather
|
|
|
+ than local file copies. (Mahadev Konar via cutting)
|
|
|
+
|
|
|
+25. HADOOP-482. Fix unit tests to work when a cluster is running on
|
|
|
+ the same machine, removing port conflicts. (Wendy Chien via cutting)
|
|
|
+
|
|
|
+26. HADOOP-90. Permit dfs.name.dir to list multiple directories,
|
|
|
+ where namenode data is to be replicated. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+27. HADOOP-651. Fix DFSCk to correctly pass parameters to the servlet
|
|
|
+ on the namenode. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+28. HADOOP-553. Change main() routines of DataNode and NameNode to
|
|
|
+ log exceptions rather than letting the JVM print them to standard
|
|
|
+ error. Also, change the hadoop-daemon.sh script to rotate
|
|
|
+ standard i/o log files. (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+29. HADOOP-399. Fix javadoc warnings. (Nigel Daley via cutting)
|
|
|
+
|
|
|
+30. HADOOP-599. Fix web ui and command line to correctly report DFS
|
|
|
+ filesystem size statistics. Also improve web layout.
|
|
|
+ (Raghu Angadi via cutting)
|
|
|
+
|
|
|
+31. HADOOP-660. Permit specification of junit test output format.
|
|
|
+ (Nigel Daley via cutting)
|
|
|
+
|
|
|
+32. HADOOP-663. Fix a few unit test issues. (Mahadev Konar via cutting)
|
|
|
+
|
|
|
+33. HADOOP-664. Cause entire build to fail if libhdfs tests fail.
|
|
|
+ (Nigel Daley via cutting)
|
|
|
+
|
|
|
+34. HADOOP-633. Keep jobtracker from dying when job initialization
|
|
|
+ throws exceptions. Also improve exception handling in a few other
|
|
|
+ places and add more informative thread names.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+35. HADOOP-669. Fix a problem introduced by HADOOP-90 that can cause
|
|
|
+ DFS to lose files. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+36. HADOOP-373. Consistently check the value returned by
|
|
|
+ FileSystem.mkdirs(). (Wendy Chien via cutting)
|
|
|
+
|
|
|
+37. HADOOP-670. Code cleanups in some DFS internals: use generic
|
|
|
+ types, replace Vector with ArrayList, etc.
|
|
|
+ (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+38. HADOOP-647. Permit map outputs to use a different compression
|
|
|
+ type than the job output. (omalley via cutting)
|
|
|
+
|
|
|
+39. HADOOP-671. Fix file cache to check for pre-existence before
|
|
|
+ creating . (Mahadev Konar via cutting)
|
|
|
+
|
|
|
+40. HADOOP-665. Extend many DFSShell commands to accept multiple
|
|
|
+ arguments. Now commands like "ls", "rm", etc. will operate on
|
|
|
+ multiple files. (Dhruba Borthakur via cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.7.2 - 2006-10-18
|
|
|
+
|
|
|
+ 1. HADOOP-607. Fix a bug where classes included in job jars were not
|
|
|
+ found by tasks. (Mahadev Konar via cutting)
|
|
|
+
|
|
|
+ 2. HADOOP-609. Add a unit test that checks that classes in job jars
|
|
|
+ can be found by tasks. Also modify unit tests to specify multiple
|
|
|
+ local directories. (Mahadev Konar via cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.7.1 - 2006-10-11
|
|
|
+
|
|
|
+ 1. HADOOP-593. Fix a NullPointerException in the JobTracker.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+ 2. HADOOP-592. Fix a NullPointerException in the IPC Server. Also
|
|
|
+ consistently log when stale calls are discarded. (omalley via cutting)
|
|
|
+
|
|
|
+ 3. HADOOP-594. Increase the DFS safe-mode threshold from .95 to
|
|
|
+ .999, so that nearly all blocks must be reported before filesystem
|
|
|
+ modifications are permitted. (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+ 4. HADOOP-598. Fix tasks to retry when reporting completion, so that
|
|
|
+ a single RPC timeout won't fail a task. (omalley via cutting)
|
|
|
+
|
|
|
+ 5. HADOOP-597. Fix TaskTracker to not discard map outputs for errors
|
|
|
+ in transmitting them to reduce nodes. (omalley via cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.7.0 - 2006-10-06
|
|
|
+
|
|
|
+ 1. HADOOP-243. Fix rounding in the display of task and job progress
|
|
|
+ so that things are not shown to be 100% complete until they are in
|
|
|
+ fact finished. (omalley via cutting)
|
|
|
+
|
|
|
+ 2. HADOOP-438. Limit the length of absolute paths in DFS, since the
|
|
|
+ file format used to store pathnames has some limitations.
|
|
|
+ (Wendy Chien via cutting)
|
|
|
+
|
|
|
+ 3. HADOOP-530. Improve error messages in SequenceFile when keys or
|
|
|
+ values are of the wrong type. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+ 4. HADOOP-288. Add a file caching system and use it in MapReduce to
|
|
|
+ cache job jar files on slave nodes. (Mahadev Konar via cutting)
|
|
|
+
|
|
|
+ 5. HADOOP-533. Fix unit test to not modify conf directory.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+ 6. HADOOP-527. Permit specification of the local address that various
|
|
|
+ Hadoop daemons should bind to. (Philippe Gassmann via cutting)
|
|
|
+
|
|
|
+ 7. HADOOP-542. Updates to contrib/streaming: reformatted source code,
|
|
|
+ on-the-fly merge sort, a fix for HADOOP-540, etc.
|
|
|
+ (Michel Tourn via cutting)
|
|
|
+
|
|
|
+ 8. HADOOP-545. Remove an unused config file parameter.
|
|
|
+ (Philippe Gassmann via cutting)
|
|
|
+
|
|
|
+ 9. HADOOP-548. Add an Ant property "test.output" to build.xml that
|
|
|
+ causes test output to be logged to the console. (omalley via cutting)
|
|
|
+
|
|
|
+10. HADOOP-261. Record an error message when map output is lost.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+11. HADOOP-293. Report the full list of task error messages in the
|
|
|
+ web ui, not just the most recent. (omalley via cutting)
|
|
|
+
|
|
|
+12. HADOOP-551. Restore JobClient's console printouts to only include
|
|
|
+ a maximum of one update per one percent of progress.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+13. HADOOP-306. Add a "safe" mode to DFS. The name node enters this
|
|
|
+ when less than a specified percentage of file data is complete.
|
|
|
+ Currently safe mode is only used on startup, but eventually it
|
|
|
+ will also be entered when datanodes disconnect and file data
|
|
|
+ becomes incomplete. While in safe mode no filesystem
|
|
|
+ modifications are permitted and block replication is inhibited.
|
|
|
+ (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+14. HADOOP-431. Change 'dfs -rm' to not operate recursively and add a
|
|
|
+ new command, 'dfs -rmr' which operates recursively.
|
|
|
+ (Sameer Paranjpye via cutting)
|
|
|
+
|
|
|
+15. HADOOP-263. Include timestamps for job transitions. The web
|
|
|
+ interface now displays the start and end times of tasks and the
|
|
|
+ start times of sorting and reducing for reduce tasks. Also,
|
|
|
+ extend ObjectWritable to handle enums, so that they can be passed
|
|
|
+ as RPC parameters. (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+16. HADOOP-556. Contrib/streaming: send keep-alive reports to task
|
|
|
+ tracker every 10 seconds rather than every 100 records, to avoid
|
|
|
+ task timeouts. (Michel Tourn via cutting)
|
|
|
+
|
|
|
+17. HADOOP-547. Fix reduce tasks to ping tasktracker while copying
|
|
|
+ data, rather than only between copies, avoiding task timeouts.
|
|
|
+ (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+18. HADOOP-537. Fix src/c++/libhdfs build process to create files in
|
|
|
+ build/, no longer modifying the source tree.
|
|
|
+ (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+19. HADOOP-487. Throw a more informative exception for unknown RPC
|
|
|
+ hosts. (Sameer Paranjpye via cutting)
|
|
|
+
|
|
|
+20. HADOOP-559. Add file name globbing (pattern matching) support to
|
|
|
+ the FileSystem API, and use it in DFSShell ('bin/hadoop dfs')
|
|
|
+ commands. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+21. HADOOP-508. Fix a bug in FSDataInputStream. Incorrect data was
|
|
|
+ returned after seeking to a random location.
|
|
|
+ (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+22. HADOOP-560. Add a "killed" task state. This can be used to
|
|
|
+ distinguish kills from other failures. Task state has also been
|
|
|
+ converted to use an enum type instead of an int, uncovering a bug
|
|
|
+ elsewhere. The web interface is also updated to display killed
|
|
|
+ tasks. (omalley via cutting)
|
|
|
+
|
|
|
+23. HADOOP-423. Normalize Paths containing directories named "." and
|
|
|
+ "..", using the standard, unix interpretation. Also add checks in
|
|
|
+ DFS, prohibiting the use of "." or ".." as directory or file
|
|
|
+ names. (Wendy Chien via cutting)
|
|
|
+
|
|
|
+24. HADOOP-513. Replace map output handling with a servlet, rather
|
|
|
+ than a JSP page. This fixes an issue where
|
|
|
+ IllegalStateException's were logged, sets content-length
|
|
|
+ correctly, and better handles some errors. (omalley via cutting)
|
|
|
+
|
|
|
+25. HADOOP-552. Improved error checking when copying map output files
|
|
|
+ to reduce nodes. (omalley via cutting)
|
|
|
+
|
|
|
+26. HADOOP-566. Fix scripts to work correctly when accessed through
|
|
|
+ relative symbolic links. (Lee Faris via cutting)
|
|
|
+
|
|
|
+27. HADOOP-519. Add positioned read methods to FSInputStream. These
|
|
|
+ permit one to read from a stream without moving its position, and
|
|
|
+ can hence be performed by multiple threads at once on a single
|
|
|
+ stream. Implement an optimized version for DFS and local FS.
|
|
|
+ (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+28. HADOOP-522. Permit block compression with MapFile and SetFile.
|
|
|
+ Since these formats are always sorted, block compression can
|
|
|
+ provide a big advantage. (cutting)
|
|
|
+
|
|
|
+29. HADOOP-567. Record version and revision information in builds. A
|
|
|
+ package manifest is added to the generated jar file containing
|
|
|
+ version information, and a VersionInfo utility is added that
|
|
|
+ includes further information, including the build date and user,
|
|
|
+ and the subversion revision and repository. A 'bin/hadoop
|
|
|
+ version' comand is added to show this information, and it is also
|
|
|
+ added to various web interfaces. (omalley via cutting)
|
|
|
+
|
|
|
+30. HADOOP-568. Fix so that errors while initializing tasks on a
|
|
|
+ tasktracker correctly report the task as failed to the jobtracker,
|
|
|
+ so that it will be rescheduled. (omalley via cutting)
|
|
|
+
|
|
|
+31. HADOOP-550. Disable automatic UTF-8 validation in Text. This
|
|
|
+ permits, e.g., TextInputFormat to again operate on non-UTF-8 data.
|
|
|
+ (Hairong and Mahadev via cutting)
|
|
|
+
|
|
|
+32. HADOOP-343. Fix mapred copying so that a failed tasktracker
|
|
|
+ doesn't cause other copies to slow. (Sameer Paranjpye via cutting)
|
|
|
+
|
|
|
+33. HADOOP-239. Add a persistent job history mechanism, so that basic
|
|
|
+ job statistics are not lost after 24 hours and/or when the
|
|
|
+ jobtracker is restarted. (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+34. HADOOP-506. Ignore heartbeats from stale task trackers.
|
|
|
+ (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+35. HADOOP-255. Discard stale, queued IPC calls. Do not process
|
|
|
+ calls whose clients will likely time out before they receive a
|
|
|
+ response. When the queue is full, new calls are now received and
|
|
|
+ queued, and the oldest calls are discarded, so that, when servers
|
|
|
+ get bogged down, they no longer develop a backlog on the socket.
|
|
|
+ This should improve some DFS namenode failure modes.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+36. HADOOP-581. Fix datanode to not reset itself on communications
|
|
|
+ errors with the namenode. If a request to the namenode fails, the
|
|
|
+ datanode should retry, not restart. This reduces the load on the
|
|
|
+ namenode, since restarts cause a resend of the block report.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.6.2 - 2006-09-18
|
|
|
+
|
|
|
+1. HADOOP-532. Fix a bug reading value-compressed sequence files,
|
|
|
+ where an exception was thrown reporting that the full value had not
|
|
|
+ been read. (omalley via cutting)
|
|
|
+
|
|
|
+2. HADOOP-534. Change the default value class in JobConf to be Text
|
|
|
+ instead of the now-deprecated UTF8. This fixes the Grep example
|
|
|
+ program, which was updated to use Text, but relies on this
|
|
|
+ default. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.6.1 - 2006-09-13
|
|
|
+
|
|
|
+ 1. HADOOP-520. Fix a bug in libhdfs, where write failures were not
|
|
|
+ correctly returning error codes. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+ 2. HADOOP-523. Fix a NullPointerException when TextInputFormat is
|
|
|
+ explicitly specified. Also add a test case for this.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+ 3. HADOOP-521. Fix another NullPointerException finding the
|
|
|
+ ClassLoader when using libhdfs. (omalley via cutting)
|
|
|
+
|
|
|
+ 4. HADOOP-526. Fix a NullPointerException when attempting to start
|
|
|
+ two datanodes in the same directory. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+ 5. HADOOP-529. Fix a NullPointerException when opening
|
|
|
+ value-compressed sequence files generated by pre-0.6.0 Hadoop.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.6.0 - 2006-09-08
|
|
|
+
|
|
|
+ 1. HADOOP-427. Replace some uses of DatanodeDescriptor in the DFS
|
|
|
+ web UI code with DatanodeInfo, the preferred public class.
|
|
|
+ (Devaraj Das via cutting)
|
|
|
+
|
|
|
+ 2. HADOOP-426. Fix streaming contrib module to work correctly on
|
|
|
+ Solaris. This was causing nightly builds to fail.
|
|
|
+ (Michel Tourn via cutting)
|
|
|
+
|
|
|
+ 3. HADOOP-400. Improvements to task assignment. Tasks are no longer
|
|
|
+ re-run on nodes where they have failed (unless no other node is
|
|
|
+ available). Also, tasks are better load-balanced among nodes.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+ 4. HADOOP-324. Fix datanode to not exit when a disk is full, but
|
|
|
+ rather simply to fail writes. (Wendy Chien via cutting)
|
|
|
+
|
|
|
+ 5. HADOOP-434. Change smallJobsBenchmark to use standard Hadoop
|
|
|
+ scripts. (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+ 6. HADOOP-453. Fix a bug in Text.setCapacity(). (siren via cutting)
|
|
|
+
|
|
|
+
|
|
|
+ 7. HADOOP-450. Change so that input types are determined by the
|
|
|
+ RecordReader rather than specified directly in the JobConf. This
|
|
|
+ facilitates jobs with a variety of input types.
|
|
|
+
|
|
|
+ WARNING: This contains incompatible API changes! The RecordReader
|
|
|
+ interface has two new methods that all user-defined InputFormats
|
|
|
+ must now define. Also, the values returned by TextInputFormat are
|
|
|
+ no longer of class UTF8, but now of class Text.
|
|
|
+
|
|
|
+ 8. HADOOP-436. Fix an error-handling bug in the web ui.
|
|
|
+ (Devaraj Das via cutting)
|
|
|
+
|
|
|
+ 9. HADOOP-455. Fix a bug in Text, where DEL was not permitted.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+10. HADOOP-456. Change the DFS namenode to keep a persistent record
|
|
|
+ of the set of known datanodes. This will be used to implement a
|
|
|
+ "safe mode" where filesystem changes are prohibited when a
|
|
|
+ critical percentage of the datanodes are unavailable.
|
|
|
+ (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+11. HADOOP-322. Add a job control utility. This permits one to
|
|
|
+ specify job interdependencies. Each job is submitted only after
|
|
|
+ the jobs it depends on have successfully completed.
|
|
|
+ (Runping Qi via cutting)
|
|
|
+
|
|
|
+12. HADOOP-176. Fix a bug in IntWritable.Comparator.
|
|
|
+ (Dick King via cutting)
|
|
|
+
|
|
|
+13. HADOOP-421. Replace uses of String in recordio package with Text
|
|
|
+ class, for improved handling of UTF-8 data.
|
|
|
+ (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+14. HADOOP-464. Improved error message when job jar not found.
|
|
|
+ (Michel Tourn via cutting)
|
|
|
+
|
|
|
+15. HADOOP-469. Fix /bin/bash specifics that have crept into our
|
|
|
+ /bin/sh scripts since HADOOP-352.
|
|
|
+ (Jean-Baptiste Quenot via cutting)
|
|
|
+
|
|
|
+16. HADOOP-468. Add HADOOP_NICENESS environment variable to set
|
|
|
+ scheduling priority for daemons. (Vetle Roeim via cutting)
|
|
|
+
|
|
|
+17. HADOOP-473. Fix TextInputFormat to correctly handle more EOL
|
|
|
+ formats. Things now work correctly with CR, LF or CRLF.
|
|
|
+ (Dennis Kubes & James White via cutting)
|
|
|
+
|
|
|
+18. HADOOP-461. Make Java 1.5 an explicit requirement. (cutting)
|
|
|
+
|
|
|
+19. HADOOP-54. Add block compression to SequenceFile. One may now
|
|
|
+ specify that blocks of keys and values are compressed together,
|
|
|
+ improving compression for small keys and values.
|
|
|
+ SequenceFile.Writer's constructor is now deprecated and replaced
|
|
|
+ with a factory method. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+20. HADOOP-281. Prohibit DFS files that are also directories.
|
|
|
+ (Wendy Chien via cutting)
|
|
|
+
|
|
|
+21. HADOOP-486. Add the job username to JobStatus instances returned
|
|
|
+ by JobClient. (Mahadev Konar via cutting)
|
|
|
+
|
|
|
+22. HADOOP-437. contrib/streaming: Add support for gzipped inputs.
|
|
|
+ (Michel Tourn via cutting)
|
|
|
+
|
|
|
+23. HADOOP-463. Add variable expansion to config files.
|
|
|
+ Configuration property values may now contain variable
|
|
|
+ expressions. A variable is referenced with the syntax
|
|
|
+ '${variable}'. Variables values are found first in the
|
|
|
+ configuration, and then in Java system properties. The default
|
|
|
+ configuration is modified so that temporary directories are now
|
|
|
+ under ${hadoop.tmp.dir}, which is, by default,
|
|
|
+ /tmp/hadoop-${user.name}. (Michel Tourn via cutting)
|
|
|
+
|
|
|
+24. HADOOP-419. Fix a NullPointerException finding the ClassLoader
|
|
|
+ when using libhdfs. (omalley via cutting)
|
|
|
+
|
|
|
+25. HADOOP-460. Fix contrib/smallJobsBenchmark to use Text instead of
|
|
|
+ UTF8. (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+26. HADOOP-196. Fix Configuration(Configuration) constructor to work
|
|
|
+ correctly. (Sami Siren via cutting)
|
|
|
+
|
|
|
+27. HADOOP-501. Fix Configuration.toString() to handle URL resources.
|
|
|
+ (Thomas Friol via cutting)
|
|
|
+
|
|
|
+28. HADOOP-499. Reduce the use of Strings in contrib/streaming,
|
|
|
+ replacing them with Text for better performance.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+29. HADOOP-64. Manage multiple volumes with a single DataNode.
|
|
|
+ Previously DataNode would create a separate daemon per configured
|
|
|
+ volume, each with its own connection to the NameNode. Now all
|
|
|
+ volumes are handled by a single DataNode daemon, reducing the load
|
|
|
+ on the NameNode. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+30. HADOOP-424. Fix MapReduce so that jobs which generate zero splits
|
|
|
+ do not fail. (Fr??d??ric Bertin via cutting)
|
|
|
+
|
|
|
+31. HADOOP-408. Adjust some timeouts and remove some others so that
|
|
|
+ unit tests run faster. (cutting)
|
|
|
+
|
|
|
+32. HADOOP-507. Fix an IllegalAccessException in DFS.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+33. HADOOP-320. Fix so that checksum files are correctly copied when
|
|
|
+ the destination of a file copy is a directory.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+34. HADOOP-286. In DFSClient, avoid pinging the NameNode with
|
|
|
+ renewLease() calls when no files are being written.
|
|
|
+ (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+35. HADOOP-312. Close idle IPC connections. All IPC connections were
|
|
|
+ cached forever. Now, after a connection has been idle for more
|
|
|
+ than a configurable amount of time (one second by default), the
|
|
|
+ connection is closed, conserving resources on both client and
|
|
|
+ server. (Devaraj Das via cutting)
|
|
|
+
|
|
|
+36. HADOOP-497. Permit the specification of the network interface and
|
|
|
+ nameserver to be used when determining the local hostname
|
|
|
+ advertised by datanodes and tasktrackers.
|
|
|
+ (Lorenzo Thione via cutting)
|
|
|
+
|
|
|
+37. HADOOP-441. Add a compression codec API and extend SequenceFile
|
|
|
+ to use it. This will permit the use of alternate compression
|
|
|
+ codecs in SequenceFile. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+38. HADOOP-483. Improvements to libhdfs build and documentation.
|
|
|
+ (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+39. HADOOP-458. Fix a memory corruption bug in libhdfs.
|
|
|
+ (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+40. HADOOP-517. Fix a contrib/streaming bug in end-of-line detection.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+41. HADOOP-474. Add CompressionCodecFactory, and use it in
|
|
|
+ TextInputFormat and TextOutputFormat. Compressed input files are
|
|
|
+ automatically decompressed when they have the correct extension.
|
|
|
+ Output files will, when output compression is specified, be
|
|
|
+ generated with an approprate extension. Also add a gzip codec and
|
|
|
+ fix problems with UTF8 text inputs. (omalley via cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.5.0 - 2006-08-04
|
|
|
+
|
|
|
+ 1. HADOOP-352. Fix shell scripts to use /bin/sh instead of
|
|
|
+ /bin/bash, for better portability.
|
|
|
+ (Jean-Baptiste Quenot via cutting)
|
|
|
+
|
|
|
+ 2. HADOOP-313. Permit task state to be saved so that single tasks
|
|
|
+ may be manually re-executed when debugging. (omalley via cutting)
|
|
|
+
|
|
|
+ 3. HADOOP-339. Add method to JobClient API listing jobs that are
|
|
|
+ not yet complete, i.e., that are queued or running.
|
|
|
+ (Mahadev Konar via cutting)
|
|
|
+
|
|
|
+ 4. HADOOP-355. Updates to the streaming contrib module, including
|
|
|
+ API fixes, making reduce optional, and adding an input type for
|
|
|
+ StreamSequenceRecordReader. (Michel Tourn via cutting)
|
|
|
+
|
|
|
+ 5. HADOOP-358. Fix a NPE bug in Path.equals().
|
|
|
+ (Fr??d??ric Bertin via cutting)
|
|
|
+
|
|
|
+ 6. HADOOP-327. Fix ToolBase to not call System.exit() when
|
|
|
+ exceptions are thrown. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+ 7. HADOOP-359. Permit map output to be compressed.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+ 8. HADOOP-341. Permit input URI to CopyFiles to use the HTTP
|
|
|
+ protocol. This lets one, e.g., more easily copy log files into
|
|
|
+ DFS. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+ 9. HADOOP-361. Remove unix dependencies from streaming contrib
|
|
|
+ module tests, making them pure java. (Michel Tourn via cutting)
|
|
|
+
|
|
|
+10. HADOOP-354. Make public methods to stop DFS daemons.
|
|
|
+ (Barry Kaplan via cutting)
|
|
|
+
|
|
|
+11. HADOOP-252. Add versioning to RPC protocols.
|
|
|
+ (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+12. HADOOP-356. Add contrib to "compile" and "test" build targets, so
|
|
|
+ that this code is better maintained. (Michel Tourn via cutting)
|
|
|
+
|
|
|
+13. HADOOP-307. Add smallJobsBenchmark contrib module. This runs
|
|
|
+ lots of small jobs, in order to determine per-task overheads.
|
|
|
+ (Sanjay Dahiya via cutting)
|
|
|
+
|
|
|
+14. HADOOP-342. Add a tool for log analysis: Logalyzer.
|
|
|
+ (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+15. HADOOP-347. Add web-based browsing of DFS content. The namenode
|
|
|
+ redirects browsing requests to datanodes. Content requests are
|
|
|
+ redirected to datanodes where the data is local when possible.
|
|
|
+ (Devaraj Das via cutting)
|
|
|
+
|
|
|
+16. HADOOP-351. Make Hadoop IPC kernel independent of Jetty.
|
|
|
+ (Devaraj Das via cutting)
|
|
|
+
|
|
|
+17. HADOOP-237. Add metric reporting to DFS and MapReduce. With only
|
|
|
+ minor configuration changes, one can now monitor many Hadoop
|
|
|
+ system statistics using Ganglia or other monitoring systems.
|
|
|
+ (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+18. HADOOP-376. Fix datanode's HTTP server to scan for a free port.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+19. HADOOP-260. Add --config option to shell scripts, specifying an
|
|
|
+ alternate configuration directory. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+20. HADOOP-381. Permit developers to save the temporary files for
|
|
|
+ tasks whose names match a regular expression, to facilliate
|
|
|
+ debugging. (omalley via cutting)
|
|
|
+
|
|
|
+21. HADOOP-344. Fix some Windows-related problems with DF.
|
|
|
+ (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+22. HADOOP-380. Fix reduce tasks to poll less frequently for map
|
|
|
+ outputs. (Mahadev Konar via cutting)
|
|
|
+
|
|
|
+23. HADOOP-321. Refactor DatanodeInfo, in preparation for
|
|
|
+ HADOOP-306. (Konstantin Shvachko & omalley via cutting)
|
|
|
+
|
|
|
+24. HADOOP-385. Fix some bugs in record io code generation.
|
|
|
+ (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+25. HADOOP-302. Add new Text class to replace UTF8, removing
|
|
|
+ limitations of that class. Also refactor utility methods for
|
|
|
+ writing zero-compressed integers (VInts and VLongs).
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+26. HADOOP-335. Refactor DFS namespace/transaction logging in
|
|
|
+ namenode. (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+27. HADOOP-375. Fix handling of the datanode HTTP daemon's port so
|
|
|
+ that multiple datanode's can be run on a single host.
|
|
|
+ (Devaraj Das via cutting)
|
|
|
+
|
|
|
+28. HADOOP-386. When removing excess DFS block replicas, remove those
|
|
|
+ on nodes with the least free space first.
|
|
|
+ (Johan Oskarson via cutting)
|
|
|
+
|
|
|
+29. HADOOP-389. Fix intermittent failures of mapreduce unit tests.
|
|
|
+ Also fix some build dependencies.
|
|
|
+ (Mahadev & Konstantin via cutting)
|
|
|
+
|
|
|
+30. HADOOP-362. Fix a problem where jobs hang when status messages
|
|
|
+ are recieved out-of-order. (omalley via cutting)
|
|
|
+
|
|
|
+31. HADOOP-394. Change order of DFS shutdown in unit tests to
|
|
|
+ minimize errors logged. (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+32. HADOOP-396. Make DatanodeID implement Writable.
|
|
|
+ (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+33. HADOOP-377. Permit one to add URL resources to a Configuration.
|
|
|
+ (Jean-Baptiste Quenot via cutting)
|
|
|
+
|
|
|
+34. HADOOP-345. Permit iteration over Configuration key/value pairs.
|
|
|
+ (Michel Tourn via cutting)
|
|
|
+
|
|
|
+35. HADOOP-409. Streaming contrib module: make configuration
|
|
|
+ properties available to commands as environment variables.
|
|
|
+ (Michel Tourn via cutting)
|
|
|
+
|
|
|
+36. HADOOP-369. Add -getmerge option to dfs command that appends all
|
|
|
+ files in a directory into a single local file.
|
|
|
+ (Johan Oskarson via cutting)
|
|
|
+
|
|
|
+37. HADOOP-410. Replace some TreeMaps with HashMaps in DFS, for
|
|
|
+ a 17% performance improvement. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+38. HADOOP-411. Add unit tests for command line parser.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+39. HADOOP-412. Add MapReduce input formats that support filtering
|
|
|
+ of SequenceFile data, including sampling and regex matching.
|
|
|
+ Also, move JobConf.newInstance() to a new utility class.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+40. HADOOP-226. Fix fsck command to properly consider replication
|
|
|
+ counts, now that these can vary per file. (Bryan Pendleton via cutting)
|
|
|
+
|
|
|
+41. HADOOP-425. Add a Python MapReduce example, using Jython.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.4.0 - 2006-06-28
|
|
|
+
|
|
|
+ 1. HADOOP-298. Improved progress reports for CopyFiles utility, the
|
|
|
+ distributed file copier. (omalley via cutting)
|
|
|
+
|
|
|
+ 2. HADOOP-299. Fix the task tracker, permitting multiple jobs to
|
|
|
+ more easily execute at the same time. (omalley via cutting)
|
|
|
+
|
|
|
+ 3. HADOOP-250. Add an HTTP user interface to the namenode, running
|
|
|
+ on port 50070. (Devaraj Das via cutting)
|
|
|
+
|
|
|
+ 4. HADOOP-123. Add MapReduce unit tests that run a jobtracker and
|
|
|
+ tasktracker, greatly increasing code coverage.
|
|
|
+ (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+ 5. HADOOP-271. Add links from jobtracker's web ui to tasktracker's
|
|
|
+ web ui. Also attempt to log a thread dump of child processes
|
|
|
+ before they're killed. (omalley via cutting)
|
|
|
+
|
|
|
+ 6. HADOOP-210. Change RPC server to use a selector instead of a
|
|
|
+ thread per connection. This should make it easier to scale to
|
|
|
+ larger clusters. Note that this incompatibly changes the RPC
|
|
|
+ protocol: clients and servers must both be upgraded to the new
|
|
|
+ version to ensure correct operation. (Devaraj Das via cutting)
|
|
|
+
|
|
|
+ 7. HADOOP-311. Change DFS client to retry failed reads, so that a
|
|
|
+ single read failure will not alone cause failure of a task.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+ 8. HADOOP-314. Remove the "append" phase when reducing. Map output
|
|
|
+ files are now directly passed to the sorter, without first
|
|
|
+ appending them into a single file. Now, the first third of reduce
|
|
|
+ progress is "copy" (transferring map output to reduce nodes), the
|
|
|
+ middle third is "sort" (sorting map output) and the last third is
|
|
|
+ "reduce" (generating output). Long-term, the "sort" phase will
|
|
|
+ also be removed. (omalley via cutting)
|
|
|
+
|
|
|
+ 9. HADOOP-316. Fix a potential deadlock in the jobtracker.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+10. HADOOP-319. Fix FileSystem.close() to remove the FileSystem
|
|
|
+ instance from the cache. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+11. HADOOP-135. Fix potential deadlock in JobTracker by acquiring
|
|
|
+ locks in a consistent order. (omalley via cutting)
|
|
|
+
|
|
|
+12. HADOOP-278. Check for existence of input directories before
|
|
|
+ starting MapReduce jobs, making it easier to debug this common
|
|
|
+ error. (omalley via cutting)
|
|
|
+
|
|
|
+13. HADOOP-304. Improve error message for
|
|
|
+ UnregisterdDatanodeException to include expected node name.
|
|
|
+ (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+14. HADOOP-305. Fix TaskTracker to ask for new tasks as soon as a
|
|
|
+ task is finished, rather than waiting for the next heartbeat.
|
|
|
+ This improves performance when tasks are short.
|
|
|
+ (Mahadev Konar via cutting)
|
|
|
+
|
|
|
+15. HADOOP-59. Add support for generic command line options. One may
|
|
|
+ now specify the filesystem (-fs), the MapReduce jobtracker (-jt),
|
|
|
+ a config file (-conf) or any configuration property (-D). The
|
|
|
+ "dfs", "fsck", "job", and "distcp" commands currently support
|
|
|
+ this, with more to be added. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+16. HADOOP-296. Permit specification of the amount of reserved space
|
|
|
+ on a DFS datanode. One may specify both the percentage free and
|
|
|
+ the number of bytes. (Johan Oskarson via cutting)
|
|
|
+
|
|
|
+17. HADOOP-325. Fix a problem initializing RPC parameter classes, and
|
|
|
+ remove the workaround used to initialize classes.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+18. HADOOP-328. Add an option to the "distcp" command to ignore read
|
|
|
+ errors while copying. (omalley via cutting)
|
|
|
+
|
|
|
+19. HADOOP-27. Don't allocate tasks to trackers whose local free
|
|
|
+ space is too low. (Johan Oskarson via cutting)
|
|
|
+
|
|
|
+20. HADOOP-318. Keep slow DFS output from causing task timeouts.
|
|
|
+ This incompatibly changes some public interfaces, adding a
|
|
|
+ parameter to OutputFormat.getRecordWriter() and the new method
|
|
|
+ Reporter.progress(), but it makes lots of tasks succeed that were
|
|
|
+ previously failing. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.3.2 - 2006-06-09
|
|
|
+
|
|
|
+ 1. HADOOP-275. Update the streaming contrib module to use log4j for
|
|
|
+ its logging. (Michel Tourn via cutting)
|
|
|
+
|
|
|
+ 2. HADOOP-279. Provide defaults for log4j logging parameters, so
|
|
|
+ that things still work reasonably when Hadoop-specific system
|
|
|
+ properties are not provided. (omalley via cutting)
|
|
|
+
|
|
|
+ 3. HADOOP-280. Fix a typo in AllTestDriver which caused the wrong
|
|
|
+ test to be run when "DistributedFSCheck" was specified.
|
|
|
+ (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+ 4. HADOOP-240. DFS's mkdirs() implementation no longer logs a warning
|
|
|
+ when the directory already exists. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+ 5. HADOOP-285. Fix DFS datanodes to be able to re-join the cluster
|
|
|
+ after the connection to the namenode is lost. (omalley via cutting)
|
|
|
+
|
|
|
+ 6. HADOOP-277. Fix a race condition when creating directories.
|
|
|
+ (Sameer Paranjpye via cutting)
|
|
|
+
|
|
|
+ 7. HADOOP-289. Improved exception handling in DFS datanode.
|
|
|
+ (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+ 8. HADOOP-292. Fix client-side logging to go to standard error
|
|
|
+ rather than standard output, so that it can be distinguished from
|
|
|
+ application output. (omalley via cutting)
|
|
|
+
|
|
|
+ 9. HADOOP-294. Fixed bug where conditions for retrying after errors
|
|
|
+ in the DFS client were reversed. (omalley via cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.3.1 - 2006-06-05
|
|
|
+
|
|
|
+ 1. HADOOP-272. Fix a bug in bin/hadoop setting log
|
|
|
+ parameters. (omalley & cutting)
|
|
|
+
|
|
|
+ 2. HADOOP-274. Change applications to log to standard output rather
|
|
|
+ than to a rolling log file like daemons. (omalley via cutting)
|
|
|
+
|
|
|
+ 3. HADOOP-262. Fix reduce tasks to report progress while they're
|
|
|
+ waiting for map outputs, so that they do not time out.
|
|
|
+ (Mahadev Konar via cutting)
|
|
|
+
|
|
|
+ 4. HADOOP-245 and HADOOP-246. Improvements to record io package.
|
|
|
+ (Mahadev Konar via cutting)
|
|
|
+
|
|
|
+ 5. HADOOP-276. Add logging config files to jar file so that they're
|
|
|
+ always found. (omalley via cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.3.0 - 2006-06-02
|
|
|
+
|
|
|
+ 1. HADOOP-208. Enhance MapReduce web interface, adding new pages
|
|
|
+ for failed tasks, and tasktrackers. (omalley via cutting)
|
|
|
+
|
|
|
+ 2. HADOOP-204. Tweaks to metrics package. (David Bowen via cutting)
|
|
|
+
|
|
|
+ 3. HADOOP-209. Add a MapReduce-based file copier. This will
|
|
|
+ copy files within or between file systems in parallel.
|
|
|
+ (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+ 4. HADOOP-146. Fix DFS to check when randomly generating a new block
|
|
|
+ id that no existing blocks already have that id.
|
|
|
+ (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+ 5. HADOOP-180. Make a daemon thread that does the actual task clean ups, so
|
|
|
+ that the main offerService thread in the taskTracker doesn't get stuck
|
|
|
+ and miss his heartbeat window. This was killing many task trackers as
|
|
|
+ big jobs finished (300+ tasks / node). (omalley via cutting)
|
|
|
+
|
|
|
+ 6. HADOOP-200. Avoid transmitting entire list of map task names to
|
|
|
+ reduce tasks. Instead just transmit the number of map tasks and
|
|
|
+ henceforth refer to them by number when collecting map output.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+ 7. HADOOP-219. Fix a NullPointerException when handling a checksum
|
|
|
+ exception under SequenceFile.Sorter.sort(). (cutting & stack)
|
|
|
+
|
|
|
+ 8. HADOOP-212. Permit alteration of the file block size in DFS. The
|
|
|
+ default block size for new files may now be specified in the
|
|
|
+ configuration with the dfs.block.size property. The block size
|
|
|
+ may also be specified when files are opened.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+ 9. HADOOP-218. Avoid accessing configuration while looping through
|
|
|
+ tasks in JobTracker. (Mahadev Konar via cutting)
|
|
|
+
|
|
|
+10. HADOOP-161. Add hashCode() method to DFS's Block.
|
|
|
+ (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+11. HADOOP-115. Map output types may now be specified. These are also
|
|
|
+ used as reduce input types, thus permitting reduce input types to
|
|
|
+ differ from reduce output types. (Runping Qi via cutting)
|
|
|
+
|
|
|
+12. HADOOP-216. Add task progress to task status page.
|
|
|
+ (Bryan Pendelton via cutting)
|
|
|
+
|
|
|
+13. HADOOP-233. Add web server to task tracker that shows running
|
|
|
+ tasks and logs. Also add log access to job tracker web interface.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+14. HADOOP-205. Incorporate pending tasks into tasktracker load
|
|
|
+ calculations. (Mahadev Konar via cutting)
|
|
|
+
|
|
|
+15. HADOOP-247. Fix sort progress to better handle exceptions.
|
|
|
+ (Mahadev Konar via cutting)
|
|
|
+
|
|
|
+16. HADOOP-195. Improve performance of the transfer of map outputs to
|
|
|
+ reduce nodes by performing multiple transfers in parallel, each on
|
|
|
+ a separate socket. (Sameer Paranjpye via cutting)
|
|
|
+
|
|
|
+17. HADOOP-251. Fix task processes to be tolerant of failed progress
|
|
|
+ reports to their parent process. (omalley via cutting)
|
|
|
+
|
|
|
+18. HADOOP-325. Improve the FileNotFound exceptions thrown by
|
|
|
+ LocalFileSystem to include the name of the file.
|
|
|
+ (Benjamin Reed via cutting)
|
|
|
+
|
|
|
+19. HADOOP-254. Use HTTP to transfer map output data to reduce
|
|
|
+ nodes. This, together with HADOOP-195, greatly improves the
|
|
|
+ performance of these transfers. (omalley via cutting)
|
|
|
+
|
|
|
+20. HADOOP-163. Cause datanodes that\ are unable to either read or
|
|
|
+ write data to exit, so that the namenode will no longer target
|
|
|
+ them for new blocks and will replicate their data on other nodes.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+21. HADOOP-222. Add a -setrep option to the dfs commands that alters
|
|
|
+ file replication levels. (Johan Oskarson via cutting)
|
|
|
+
|
|
|
+22. HADOOP-75. In DFS, only check for a complete file when the file
|
|
|
+ is closed, rather than as each block is written.
|
|
|
+ (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+23. HADOOP-124. Change DFS so that datanodes are identified by a
|
|
|
+ persistent ID rather than by host and port. This solves a number
|
|
|
+ of filesystem integrity problems, when, e.g., datanodes are
|
|
|
+ restarted. (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+24. HADOOP-256. Add a C API for DFS. (Arun C Murthy via cutting)
|
|
|
+
|
|
|
+25. HADOOP-211. Switch to use the Jakarta Commons logging internally,
|
|
|
+ configured to use log4j by default. (Arun C Murthy and cutting)
|
|
|
+
|
|
|
+26. HADOOP-265. Tasktracker now fails to start if it does not have a
|
|
|
+ writable local directory for temporary files. In this case, it
|
|
|
+ logs a message to the JobTracker and exits. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+27. HADOOP-270. Fix potential deadlock in datanode shutdown.
|
|
|
+ (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+Release 0.2.1 - 2006-05-12
|
|
|
+
|
|
|
+ 1. HADOOP-199. Fix reduce progress (broken by HADOOP-182).
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+ 2. HADOOP-201. Fix 'bin/hadoop dfs -report'. (cutting)
|
|
|
+
|
|
|
+ 3. HADOOP-207. Fix JDK 1.4 incompatibility introduced by HADOOP-96.
|
|
|
+ System.getenv() does not work in JDK 1.4. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.2.0 - 2006-05-05
|
|
|
+
|
|
|
+ 1. Fix HADOOP-126. 'bin/hadoop dfs -cp' now correctly copies .crc
|
|
|
+ files. (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+ 2. Fix HADOOP-51. Change DFS to support per-file replication counts.
|
|
|
+ (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+ 3. Fix HADOOP-131. Add scripts to start/stop dfs and mapred daemons.
|
|
|
+ Use these in start/stop-all scripts. (Chris Mattmann via cutting)
|
|
|
+
|
|
|
+ 4. Stop using ssh options by default that are not yet in widely used
|
|
|
+ versions of ssh. Folks can still enable their use by uncommenting
|
|
|
+ a line in conf/hadoop-env.sh. (cutting)
|
|
|
+
|
|
|
+ 5. Fix HADOOP-92. Show information about all attempts to run each
|
|
|
+ task in the web ui. (Mahadev konar via cutting)
|
|
|
+
|
|
|
+ 6. Fix HADOOP-128. Improved DFS error handling. (Owen O'Malley via cutting)
|
|
|
+
|
|
|
+ 7. Fix HADOOP-129. Replace uses of java.io.File with new class named
|
|
|
+ Path. This fixes bugs where java.io.File methods were called
|
|
|
+ directly when FileSystem methods were desired, and reduces the
|
|
|
+ likelihood of such bugs in the future. It also makes the handling
|
|
|
+ of pathnames more consistent between local and dfs FileSystems and
|
|
|
+ between Windows and Unix. java.io.File-based methods are still
|
|
|
+ available for back-compatibility, but are deprecated and will be
|
|
|
+ removed once 0.2 is released. (cutting)
|
|
|
+
|
|
|
+ 8. Change dfs.data.dir and mapred.local.dir to be comma-separated
|
|
|
+ lists of directories, no longer be space-separated. This fixes
|
|
|
+ several bugs on Windows. (cutting)
|
|
|
+
|
|
|
+ 9. Fix HADOOP-144. Use mapred task id for dfs client id, to
|
|
|
+ facilitate debugging. (omalley via cutting)
|
|
|
+
|
|
|
+10. Fix HADOOP-143. Do not line-wrap stack-traces in web ui.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+11. Fix HADOOP-118. In DFS, improve clean up of abandoned file
|
|
|
+ creations. (omalley via cutting)
|
|
|
+
|
|
|
+12. Fix HADOOP-138. Stop multiple tasks in a single heartbeat, rather
|
|
|
+ than one per heartbeat. (Stefan via cutting)
|
|
|
+
|
|
|
+13. Fix HADOOP-139. Remove a potential deadlock in
|
|
|
+ LocalFileSystem.lock(). (Igor Bolotin via cutting)
|
|
|
+
|
|
|
+14. Fix HADOOP-134. Don't hang jobs when the tasktracker is
|
|
|
+ misconfigured to use an un-writable local directory. (omalley via cutting)
|
|
|
+
|
|
|
+15. Fix HADOOP-115. Correct an error message. (Stack via cutting)
|
|
|
+
|
|
|
+16. Fix HADOOP-133. Retry pings from child to parent, in case of
|
|
|
+ (local) communcation problems. Also log exit status, so that one
|
|
|
+ can distinguish patricide from other deaths. (omalley via cutting)
|
|
|
+
|
|
|
+17. Fix HADOOP-142. Avoid re-running a task on a host where it has
|
|
|
+ previously failed. (omalley via cutting)
|
|
|
+
|
|
|
+18. Fix HADOOP-148. Maintain a task failure count for each
|
|
|
+ tasktracker and display it in the web ui. (omalley via cutting)
|
|
|
+
|
|
|
+19. Fix HADOOP-151. Close a potential socket leak, where new IPC
|
|
|
+ connection pools were created per configuration instance that RPCs
|
|
|
+ use. Now a global RPC connection pool is used again, as
|
|
|
+ originally intended. (cutting)
|
|
|
+
|
|
|
+20. Fix HADOOP-69. Don't throw a NullPointerException when getting
|
|
|
+ hints for non-existing file split. (Bryan Pendelton via cutting)
|
|
|
+
|
|
|
+21. Fix HADOOP-157. When a task that writes dfs files (e.g., a reduce
|
|
|
+ task) failed and was retried, it would fail again and again,
|
|
|
+ eventually failing the job. The problem was that dfs did not yet
|
|
|
+ know that the failed task had abandoned the files, and would not
|
|
|
+ yet let another task create files with the same names. Dfs now
|
|
|
+ retries when creating a file long enough for locks on abandoned
|
|
|
+ files to expire. (omalley via cutting)
|
|
|
+
|
|
|
+22. Fix HADOOP-150. Improved task names that include job
|
|
|
+ names. (omalley via cutting)
|
|
|
+
|
|
|
+23. Fix HADOOP-162. Fix ConcurrentModificationException when
|
|
|
+ releasing file locks. (omalley via cutting)
|
|
|
+
|
|
|
+24. Fix HADOOP-132. Initial check-in of new Metrics API, including
|
|
|
+ implementations for writing metric data to a file and for sending
|
|
|
+ it to Ganglia. (David Bowen via cutting)
|
|
|
+
|
|
|
+25. Fix HADOOP-160. Remove some uneeded synchronization around
|
|
|
+ time-consuming operations in the TaskTracker. (omalley via cutting)
|
|
|
+
|
|
|
+26. Fix HADOOP-166. RPCs failed when passed subclasses of a declared
|
|
|
+ parameter type. This is fixed by changing ObjectWritable to store
|
|
|
+ both the declared type and the instance type for Writables. Note
|
|
|
+ that this incompatibly changes the format of ObjectWritable and
|
|
|
+ will render unreadable any ObjectWritables stored in files.
|
|
|
+ Nutch only uses ObjectWritable in intermediate files, so this
|
|
|
+ should not be a problem for Nutch. (Stefan & cutting)
|
|
|
+
|
|
|
+27. Fix HADOOP-168. MapReduce RPC protocol methods should all declare
|
|
|
+ IOException, so that timeouts are handled appropriately.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+28. Fix HADOOP-169. Don't fail a reduce task if a call to the
|
|
|
+ jobtracker to locate map outputs fails. (omalley via cutting)
|
|
|
+
|
|
|
+29. Fix HADOOP-170. Permit FileSystem clients to examine and modify
|
|
|
+ the replication count of individual files. Also fix a few
|
|
|
+ replication-related bugs. (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+30. Permit specification of a higher replication levels for job
|
|
|
+ submission files (job.xml and job.jar). This helps with large
|
|
|
+ clusters, since these files are read by every node. (cutting)
|
|
|
+
|
|
|
+31. HADOOP-173. Optimize allocation of tasks with local data. (cutting)
|
|
|
+
|
|
|
+32. HADOOP-167. Reduce number of Configurations and JobConf's
|
|
|
+ created. (omalley via cutting)
|
|
|
+
|
|
|
+33. NUTCH-256. Change FileSystem#createNewFile() to create a .crc
|
|
|
+ file. The lack of a .crc file was causing warnings. (cutting)
|
|
|
+
|
|
|
+34. HADOOP-174. Change JobClient to not abort job until it has failed
|
|
|
+ to contact the job tracker for five attempts, not just one as
|
|
|
+ before. (omalley via cutting)
|
|
|
+
|
|
|
+35. HADOOP-177. Change MapReduce web interface to page through tasks.
|
|
|
+ Previously, when jobs had more than a few thousand tasks they
|
|
|
+ could crash web browsers. (Mahadev Konar via cutting)
|
|
|
+
|
|
|
+36. HADOOP-178. In DFS, piggyback blockwork requests from datanodes
|
|
|
+ on heartbeat responses from namenode. This reduces the volume of
|
|
|
+ RPC traffic. Also move startup delay in blockwork from datanode
|
|
|
+ to namenode. This fixes a problem where restarting the namenode
|
|
|
+ triggered a lot of uneeded replication. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+37. HADOOP-183. If the DFS namenode is restarted with different
|
|
|
+ minimum and/or maximum replication counts, existing files'
|
|
|
+ replication counts are now automatically adjusted to be within the
|
|
|
+ newly configured bounds. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+38. HADOOP-186. Better error handling in TaskTracker's top-level
|
|
|
+ loop. Also improve calculation of time to send next heartbeat.
|
|
|
+ (omalley via cutting)
|
|
|
+
|
|
|
+39. HADOOP-187. Add two MapReduce examples/benchmarks. One creates
|
|
|
+ files containing random data. The second sorts the output of the
|
|
|
+ first. (omalley via cutting)
|
|
|
+
|
|
|
+40. HADOOP-185. Fix so that, when a task tracker times out making the
|
|
|
+ RPC asking for a new task to run, the job tracker does not think
|
|
|
+ that it is actually running the task returned. (omalley via cutting)
|
|
|
+
|
|
|
+41. HADOOP-190. If a child process hangs after it has reported
|
|
|
+ completion, its output should not be lost. (Stack via cutting)
|
|
|
+
|
|
|
+42. HADOOP-184. Re-structure some test code to better support testing
|
|
|
+ on a cluster. (Mahadev Konar via cutting)
|
|
|
+
|
|
|
+43. HADOOP-191 Add streaming package, Hadoop's first contrib module.
|
|
|
+ This permits folks to easily submit MapReduce jobs whose map and
|
|
|
+ reduce functions are implemented by shell commands. Use
|
|
|
+ 'bin/hadoop jar build/hadoop-streaming.jar' to get details.
|
|
|
+ (Michel Tourn via cutting)
|
|
|
+
|
|
|
+44. HADOOP-189. Fix MapReduce in standalone configuration to
|
|
|
+ correctly handle job jar files that contain a lib directory with
|
|
|
+ nested jar files. (cutting)
|
|
|
+
|
|
|
+45. HADOOP-65. Initial version of record I/O framework that enables
|
|
|
+ the specification of record types and generates marshalling code
|
|
|
+ in both Java and C++. Generated Java code implements
|
|
|
+ WritableComparable, but is not yet otherwise used by
|
|
|
+ Hadoop. (Milind Bhandarkar via cutting)
|
|
|
+
|
|
|
+46. HADOOP-193. Add a MapReduce-based FileSystem benchmark.
|
|
|
+ (Konstantin Shvachko via cutting)
|
|
|
+
|
|
|
+47. HADOOP-194. Add a MapReduce-based FileSystem checker. This reads
|
|
|
+ every block in every file in the filesystem. (Konstantin Shvachko
|
|
|
+ via cutting)
|
|
|
+
|
|
|
+48. HADOOP-182. Fix so that lost task trackers to not change the
|
|
|
+ status of reduce tasks or completed jobs. Also fixes the progress
|
|
|
+ meter so that failed tasks are subtracted. (omalley via cutting)
|
|
|
+
|
|
|
+49. HADOOP-96. Logging improvements. Log files are now separate from
|
|
|
+ standard output and standard error files. Logs are now rolled.
|
|
|
+ Logging of all DFS state changes can be enabled, to facilitate
|
|
|
+ debugging. (Hairong Kuang via cutting)
|
|
|
+
|
|
|
+
|
|
|
+Release 0.1.1 - 2006-04-08
|
|
|
+
|
|
|
+ 1. Added CHANGES.txt, logging all significant changes to Hadoop. (cutting)
|
|
|
+
|
|
|
+ 2. Fix MapReduceBase.close() to throw IOException, as declared in the
|
|
|
+ Closeable interface. This permits subclasses which override this
|
|
|
+ method to throw that exception. (cutting)
|
|
|
+
|
|
|
+ 3. Fix HADOOP-117. Pathnames were mistakenly transposed in
|
|
|
+ JobConf.getLocalFile() causing many mapred temporary files to not
|
|
|
+ be removed. (Raghavendra Prabhu via cutting)
|
|
|
+
|
|
|
+ 4. Fix HADOOP-116. Clean up job submission files when jobs complete.
|
|
|
+ (cutting)
|
|
|
+
|
|
|
+ 5. Fix HADOOP-125. Fix handling of absolute paths on Windows (cutting)
|
|
|
+
|
|
|
+Release 0.1.0 - 2006-04-01
|
|
|
+
|
|
|
+ 1. The first release of Hadoop.
|
|
|
+
|

 Todd Lipcon
14 years ago
Todd Lipcon
14 years ago
{kind=link}

{kind=link}

{kind=link}
{kind=link}
{kind=link}

{kind=link}

{kind=link}
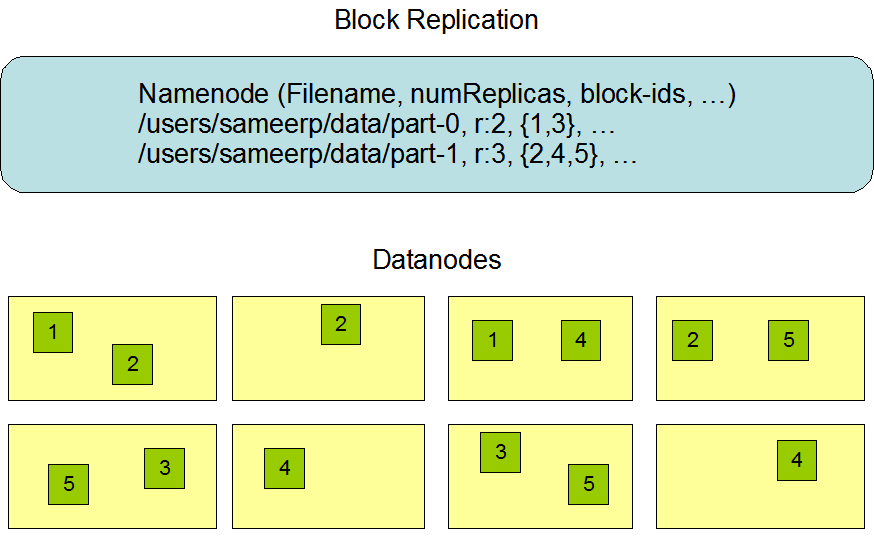
{kind=link}

{kind=link}

{kind=link}

{kind=link}
{kind=link}
{kind=link}

{kind=link}

{kind=link}
{kind=link}

{kind=link}

{kind=link}

{kind=link}