|
|
@@ -0,0 +1,390 @@
|
|
|
+<?xml version="1.0"?>
|
|
|
+<!--
|
|
|
+ Licensed to the Apache Software Foundation (ASF) under one or more
|
|
|
+ contributor license agreements. See the NOTICE file distributed with
|
|
|
+ this work for additional information regarding copyright ownership.
|
|
|
+ The ASF licenses this file to You under the Apache License, Version 2.0
|
|
|
+ (the "License"); you may not use this file except in compliance with
|
|
|
+ the License. You may obtain a copy of the License at
|
|
|
+
|
|
|
+ http://www.apache.org/licenses/LICENSE-2.0
|
|
|
+
|
|
|
+ Unless required by applicable law or agreed to in writing, software
|
|
|
+ distributed under the License is distributed on an "AS IS" BASIS,
|
|
|
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
|
|
+ See the License for the specific language governing permissions and
|
|
|
+ limitations under the License.
|
|
|
+-->
|
|
|
+
|
|
|
+<!DOCTYPE document PUBLIC "-//APACHE//DTD Documentation V2.0//EN" "http://forrest.apache.org/dtd/document-v20.dtd">
|
|
|
+
|
|
|
+
|
|
|
+<document>
|
|
|
+ <header>
|
|
|
+ <title>Fault injection Framework and Development Guide</title>
|
|
|
+ </header>
|
|
|
+
|
|
|
+ <body>
|
|
|
+ <section>
|
|
|
+ <title>Introduction</title>
|
|
|
+ <p>The following is a brief help for Hadoops' Fault Injection (FI)
|
|
|
+ Framework and Developer's Guide for those who will be developing
|
|
|
+ their own faults (aspects).
|
|
|
+ </p>
|
|
|
+ <p>An idea of Fault Injection (FI) is fairly simple: it is an
|
|
|
+ infusion of errors and exceptions into an application's logic to
|
|
|
+ achieve a higher coverage and fault tolerance of the system.
|
|
|
+ Different implementations of this idea are available at this day.
|
|
|
+ Hadoop's FI framework is built on top of Aspect Oriented Paradigm
|
|
|
+ (AOP) implemented by AspectJ toolkit.
|
|
|
+ </p>
|
|
|
+ </section>
|
|
|
+ <section>
|
|
|
+ <title>Assumptions</title>
|
|
|
+ <p>The current implementation of the framework assumes that the faults it
|
|
|
+ will be emulating are of non-deterministic nature. i.e. the moment
|
|
|
+ of a fault's happening isn't known in advance and is a coin-flip
|
|
|
+ based.
|
|
|
+ </p>
|
|
|
+ </section>
|
|
|
+ <section>
|
|
|
+ <title>Architecture of the Fault Injection Framework</title>
|
|
|
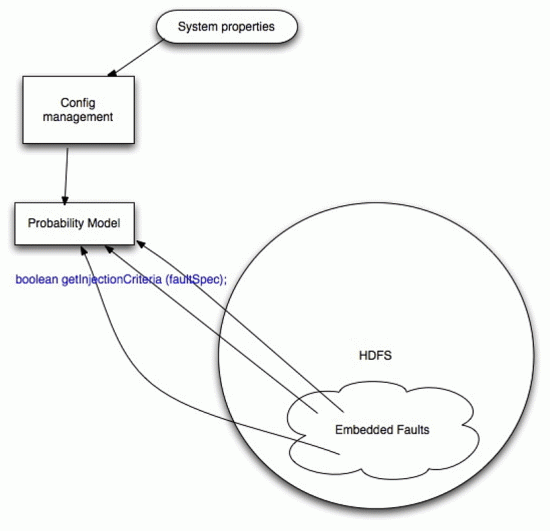
+ <figure src="images/FI-framework.gif" alt="Components layout" />
|
|
|
+ <section>
|
|
|
+ <title>Configuration management</title>
|
|
|
+ <p>This piece of the framework allow to
|
|
|
+ set expectations for faults to happen. The settings could be applied
|
|
|
+ either statically (in advance) or in a runtime. There's two ways to
|
|
|
+ configure desired level of faults in the framework:
|
|
|
+ </p>
|
|
|
+ <ul>
|
|
|
+ <li>
|
|
|
+ editing
|
|
|
+ <code>src/aop/fi-site.xml</code>
|
|
|
+ configuration file. This file is similar to other Hadoop's config
|
|
|
+ files
|
|
|
+ </li>
|
|
|
+ <li>
|
|
|
+ setting system properties of JVM through VM startup parameters or in
|
|
|
+ <code>build.properties</code>
|
|
|
+ file
|
|
|
+ </li>
|
|
|
+ </ul>
|
|
|
+ </section>
|
|
|
+ <section>
|
|
|
+ <title>Probability model</title>
|
|
|
+ <p>This fundamentally is a coin flipper. The methods of this class are
|
|
|
+ getting a random number between 0.0
|
|
|
+ and 1.0 and then checking if new number has happened to be in the
|
|
|
+ range of
|
|
|
+ 0.0 and a configured level for the fault in question. If that
|
|
|
+ condition
|
|
|
+ is true then the fault will occur.
|
|
|
+ </p>
|
|
|
+ <p>Thus, to guarantee a happening of a fault one needs to set an
|
|
|
+ appropriate level to 1.0.
|
|
|
+ To completely prevent a fault from happening its probability level
|
|
|
+ has to be set to 0.0
|
|
|
+ </p>
|
|
|
+ <p><strong>Nota bene</strong>: default probability level is set to 0
|
|
|
+ (zero) unless the level is changed explicitly through the
|
|
|
+ configuration file or in the runtime. The name of the default
|
|
|
+ level's configuration parameter is
|
|
|
+ <code>fi.*</code>
|
|
|
+ </p>
|
|
|
+ </section>
|
|
|
+ <section>
|
|
|
+ <title>Fault injection mechanism: AOP and AspectJ</title>
|
|
|
+ <p>In the foundation of Hadoop's fault injection framework lays
|
|
|
+ cross-cutting concept implemented by AspectJ. The following basic
|
|
|
+ terms are important to remember:
|
|
|
+ </p>
|
|
|
+ <ul>
|
|
|
+ <li>
|
|
|
+ <strong>A cross-cutting concept</strong>
|
|
|
+ (aspect) is behavior, and often data, that is used across the scope
|
|
|
+ of a piece of software
|
|
|
+ </li>
|
|
|
+ <li>In AOP, the
|
|
|
+ <strong>aspects</strong>
|
|
|
+ provide a mechanism by which a cross-cutting concern can be
|
|
|
+ specified in a modular way
|
|
|
+ </li>
|
|
|
+ <li>
|
|
|
+ <strong>Advice</strong>
|
|
|
+ is the
|
|
|
+ code that is executed when an aspect is invoked
|
|
|
+ </li>
|
|
|
+ <li>
|
|
|
+ <strong>Join point</strong>
|
|
|
+ (or pointcut) is a specific
|
|
|
+ point within the application that may or not invoke some advice
|
|
|
+ </li>
|
|
|
+ </ul>
|
|
|
+ </section>
|
|
|
+ <section>
|
|
|
+ <title>Existing join points</title>
|
|
|
+ <p>
|
|
|
+ The following readily available join points are provided by AspectJ:
|
|
|
+ </p>
|
|
|
+ <ul>
|
|
|
+ <li>Join when a method is called
|
|
|
+ </li>
|
|
|
+ <li>Join during a method's execution
|
|
|
+ </li>
|
|
|
+ <li>Join when a constructor is invoked
|
|
|
+ </li>
|
|
|
+ <li>Join during a constructor's execution
|
|
|
+ </li>
|
|
|
+ <li>Join during aspect advice execution
|
|
|
+ </li>
|
|
|
+ <li>Join before an object is initialized
|
|
|
+ </li>
|
|
|
+ <li>Join during object initialization
|
|
|
+ </li>
|
|
|
+ <li>Join during static initializer execution
|
|
|
+ </li>
|
|
|
+ <li>Join when a class's field is referenced
|
|
|
+ </li>
|
|
|
+ <li>Join when a class's field is assigned
|
|
|
+ </li>
|
|
|
+ <li>Join when a handler is executed
|
|
|
+ </li>
|
|
|
+ </ul>
|
|
|
+ </section>
|
|
|
+ </section>
|
|
|
+ <section>
|
|
|
+ <title>Aspects examples</title>
|
|
|
+ <source>
|
|
|
+package org.apache.hadoop.hdfs.server.datanode;
|
|
|
+
|
|
|
+import org.apache.commons.logging.Log;
|
|
|
+import org.apache.commons.logging.LogFactory;
|
|
|
+import org.apache.hadoop.fi.ProbabilityModel;
|
|
|
+import org.apache.hadoop.hdfs.server.datanode.DataNode;
|
|
|
+import org.apache.hadoop.util.DiskChecker.*;
|
|
|
+
|
|
|
+import java.io.IOException;
|
|
|
+import java.io.OutputStream;
|
|
|
+import java.io.DataOutputStream;
|
|
|
+
|
|
|
+/**
|
|
|
+* This aspect takes care about faults injected into datanode.BlockReceiver
|
|
|
+* class
|
|
|
+*/
|
|
|
+public aspect BlockReceiverAspects {
|
|
|
+ public static final Log LOG = LogFactory.getLog(BlockReceiverAspects.class);
|
|
|
+
|
|
|
+ public static final String BLOCK_RECEIVER_FAULT="hdfs.datanode.BlockReceiver";
|
|
|
+ pointcut callReceivePacket() : call (* OutputStream.write(..))
|
|
|
+ && withincode (* BlockReceiver.receivePacket(..))
|
|
|
+ // to further limit the application of this aspect a very narrow 'target' can be used as follows
|
|
|
+ // && target(DataOutputStream)
|
|
|
+ && !within(BlockReceiverAspects +);
|
|
|
+
|
|
|
+ before () throws IOException : callReceivePacket () {
|
|
|
+ if (ProbabilityModel.injectCriteria(BLOCK_RECEIVER_FAULT)) {
|
|
|
+ LOG.info("Before the injection point");
|
|
|
+ Thread.dumpStack();
|
|
|
+ throw new DiskOutOfSpaceException ("FI: injected fault point at " +
|
|
|
+ thisJoinPoint.getStaticPart( ).getSourceLocation());
|
|
|
+ }
|
|
|
+ }
|
|
|
+}
|
|
|
+ </source>
|
|
|
+ <p>
|
|
|
+ The aspect has two main parts: the join point
|
|
|
+ <code>pointcut callReceivepacket()</code>
|
|
|
+ which servers as an identification mark of a specific point (in control
|
|
|
+ and/or data flow) in the life of an application. A call to the advice -
|
|
|
+ <code>before () throws IOException : callReceivepacket()</code>
|
|
|
+ - will be
|
|
|
+ <a href="#Putting+it+all+together">injected</a>
|
|
|
+ before that specific spot of the application's code.
|
|
|
+ </p>
|
|
|
+
|
|
|
+ <p>The pointcut identifies an invocation of class'
|
|
|
+ <code>java.io.OutputStream write()</code>
|
|
|
+ method
|
|
|
+ with any number of parameters and any return type. This invoke should
|
|
|
+ take place within the body of method
|
|
|
+ <code>receivepacket()</code>
|
|
|
+ from class<code>BlockReceiver</code>.
|
|
|
+ The method can have any parameters and any return type. possible
|
|
|
+ invocations of
|
|
|
+ <code>write()</code>
|
|
|
+ method happening anywhere within the aspect
|
|
|
+ <code>BlockReceiverAspects</code>
|
|
|
+ or its heirs will be ignored.
|
|
|
+ </p>
|
|
|
+ <p><strong>Note 1</strong>: This short example doesn't illustrate
|
|
|
+ the fact that you can have more than a single injection point per
|
|
|
+ class. In such a case the names of the faults have to be different
|
|
|
+ if a developer wants to trigger them separately.
|
|
|
+ </p>
|
|
|
+ <p><strong>Note 2</strong>: After
|
|
|
+ <a href="#Putting+it+all+together">injection step</a>
|
|
|
+ you can verify that the faults were properly injected by
|
|
|
+ searching for
|
|
|
+ <code>ajc</code>
|
|
|
+ keywords in a disassembled class file.
|
|
|
+ </p>
|
|
|
+
|
|
|
+ </section>
|
|
|
+
|
|
|
+ <section>
|
|
|
+ <title>Fault naming convention & namespaces</title>
|
|
|
+ <p>For the sake of unified naming
|
|
|
+ convention the following two types of names are recommended for a
|
|
|
+ new aspects development:</p>
|
|
|
+ <ul>
|
|
|
+ <li>Activity specific notation (as
|
|
|
+ when we don't care about a particular location of a fault's
|
|
|
+ happening). In this case the name of the fault is rather abstract:
|
|
|
+ <code>fi.hdfs.DiskError</code>
|
|
|
+ </li>
|
|
|
+ <li>Location specific notation.
|
|
|
+ Here, the fault's name is mnemonic as in:
|
|
|
+ <code>fi.hdfs.datanode.BlockReceiver[optional location details]</code>
|
|
|
+ </li>
|
|
|
+ </ul>
|
|
|
+ </section>
|
|
|
+
|
|
|
+ <section>
|
|
|
+ <title>Development tools</title>
|
|
|
+ <ul>
|
|
|
+ <li>Eclipse
|
|
|
+ <a href="http://www.eclipse.org/ajdt/">AspectJ
|
|
|
+ Development Toolkit
|
|
|
+ </a>
|
|
|
+ might help you in the aspects' development
|
|
|
+ process.
|
|
|
+ </li>
|
|
|
+ <li>IntelliJ IDEA provides AspectJ weaver and Spring-AOP plugins
|
|
|
+ </li>
|
|
|
+ </ul>
|
|
|
+ </section>
|
|
|
+
|
|
|
+ <section>
|
|
|
+ <title>Putting it all together</title>
|
|
|
+ <p>Faults (or aspects) have to injected (or woven) together before
|
|
|
+ they can be used. Here's a step-by-step instruction how this can be
|
|
|
+ done.</p>
|
|
|
+ <p>Weaving aspects in place:</p>
|
|
|
+ <source>
|
|
|
+% ant injectfaults
|
|
|
+ </source>
|
|
|
+ <p>If you
|
|
|
+ misidentified the join point of your aspect then you'll see a
|
|
|
+ warning similar to this one below when 'injectfaults' target is
|
|
|
+ completed:</p>
|
|
|
+ <source>
|
|
|
+[iajc] warning at
|
|
|
+src/test/aop/org/apache/hadoop/hdfs/server/datanode/ \
|
|
|
+ BlockReceiverAspects.aj:44::0
|
|
|
+advice defined in org.apache.hadoop.hdfs.server.datanode.BlockReceiverAspects
|
|
|
+has not been applied [Xlint:adviceDidNotMatch]
|
|
|
+ </source>
|
|
|
+ <p>It isn't an error, so the build will report the successful result.
|
|
|
+
|
|
|
+ To prepare dev.jar file with all your faults weaved in
|
|
|
+ place run (HDFS-475 pending)</p>
|
|
|
+ <source>
|
|
|
+% ant jar-fault-inject
|
|
|
+ </source>
|
|
|
+
|
|
|
+ <p>Test jars can be created by</p>
|
|
|
+ <source>
|
|
|
+% ant jar-test-fault-inject
|
|
|
+ </source>
|
|
|
+
|
|
|
+ <p>To run HDFS tests with faults injected:</p>
|
|
|
+ <source>
|
|
|
+% ant run-test-hdfs-fault-inject
|
|
|
+ </source>
|
|
|
+ <section>
|
|
|
+ <title>How to use fault injection framework</title>
|
|
|
+ <p>Faults could be triggered by the following two meanings:
|
|
|
+ </p>
|
|
|
+ <ul>
|
|
|
+ <li>In the runtime as:
|
|
|
+ <source>
|
|
|
+% ant run-test-hdfs -Dfi.hdfs.datanode.BlockReceiver=0.12
|
|
|
+ </source>
|
|
|
+ To set a certain level, e.g. 25%, of all injected faults one can run
|
|
|
+ <br/>
|
|
|
+ <source>
|
|
|
+% ant run-test-hdfs-fault-inject -Dfi.*=0.25
|
|
|
+ </source>
|
|
|
+ </li>
|
|
|
+ <li>or from a program as follows:
|
|
|
+ </li>
|
|
|
+ </ul>
|
|
|
+ <source>
|
|
|
+package org.apache.hadoop.fs;
|
|
|
+
|
|
|
+import org.junit.Test;
|
|
|
+import org.junit.Before;
|
|
|
+import junit.framework.TestCase;
|
|
|
+
|
|
|
+public class DemoFiTest extends TestCase {
|
|
|
+ public static final String BLOCK_RECEIVER_FAULT="hdfs.datanode.BlockReceiver";
|
|
|
+ @Override
|
|
|
+ @Before
|
|
|
+ public void setUp(){
|
|
|
+ //Setting up the test's environment as required
|
|
|
+ }
|
|
|
+
|
|
|
+ @Test
|
|
|
+ public void testFI() {
|
|
|
+ // It triggers the fault, assuming that there's one called 'hdfs.datanode.BlockReceiver'
|
|
|
+ System.setProperty("fi." + BLOCK_RECEIVER_FAULT, "0.12");
|
|
|
+ //
|
|
|
+ // The main logic of your tests goes here
|
|
|
+ //
|
|
|
+ // Now set the level back to 0 (zero) to prevent this fault from happening again
|
|
|
+ System.setProperty("fi." + BLOCK_RECEIVER_FAULT, "0.0");
|
|
|
+ // or delete its trigger completely
|
|
|
+ System.getProperties().remove("fi." + BLOCK_RECEIVER_FAULT);
|
|
|
+ }
|
|
|
+
|
|
|
+ @Override
|
|
|
+ @After
|
|
|
+ public void tearDown() {
|
|
|
+ //Cleaning up test test environment
|
|
|
+ }
|
|
|
+}
|
|
|
+ </source>
|
|
|
+ <p>
|
|
|
+ as you can see above these two methods do the same thing. They are
|
|
|
+ setting the probability level of
|
|
|
+ <code>hdfs.datanode.BlockReceiver</code>
|
|
|
+ at 12%.
|
|
|
+ The difference, however, is that the program provides more
|
|
|
+ flexibility and allows to turn a fault off when a test doesn't need
|
|
|
+ it anymore.
|
|
|
+ </p>
|
|
|
+ </section>
|
|
|
+ </section>
|
|
|
+
|
|
|
+ <section>
|
|
|
+ <title>Additional information and contacts</title>
|
|
|
+ <p>This two sources of information seem to be particularly
|
|
|
+ interesting and worth further reading:
|
|
|
+ </p>
|
|
|
+ <ul>
|
|
|
+ <li>
|
|
|
+ <a href="http://www.eclipse.org/aspectj/doc/next/devguide/">
|
|
|
+ http://www.eclipse.org/aspectj/doc/next/devguide/
|
|
|
+ </a>
|
|
|
+ </li>
|
|
|
+ <li>AspectJ Cookbook (ISBN-13: 978-0-596-00654-9)
|
|
|
+ </li>
|
|
|
+ </ul>
|
|
|
+ <p>Should you have any farther comments or questions to the author
|
|
|
+ check
|
|
|
+ <a href="http://issues.apache.org/jira/browse/HDFS-435">HDFS-435</a>
|
|
|
+ </p>
|
|
|
+ </section>
|
|
|
+ </body>
|
|
|
+</document>
|

 Tsz-wo Sze
Tsz-wo Sze
{kind=link}